Downloaded 43 times


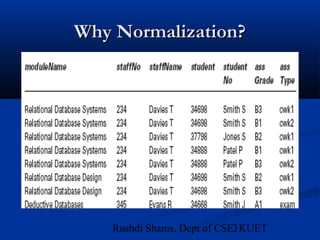





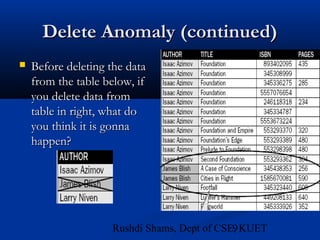
















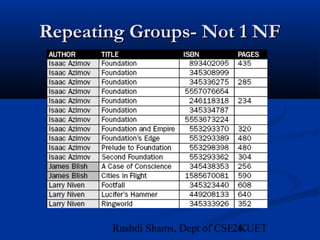
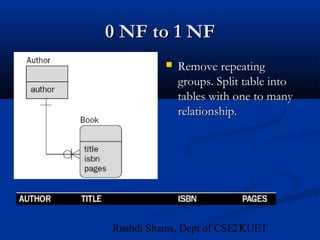
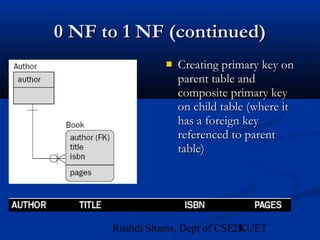
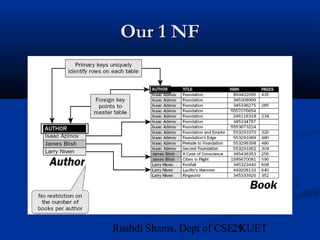
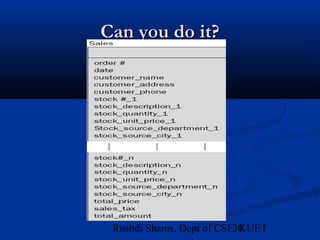



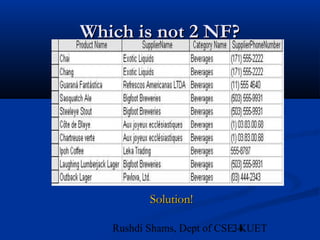
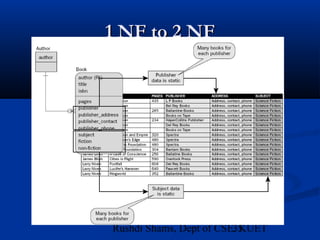
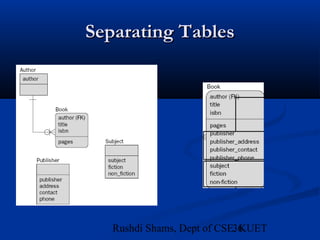
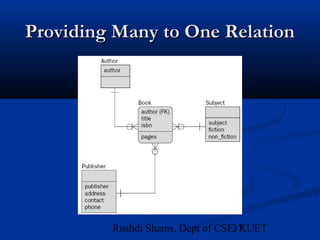
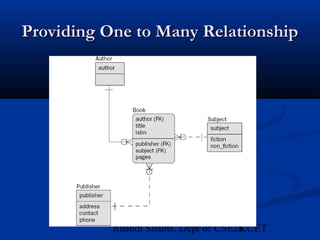

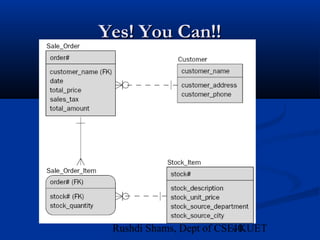










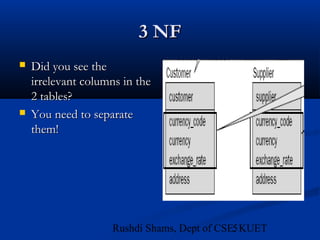
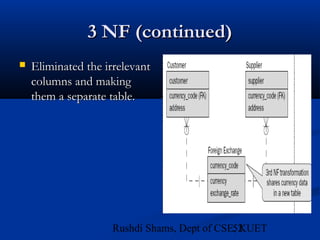

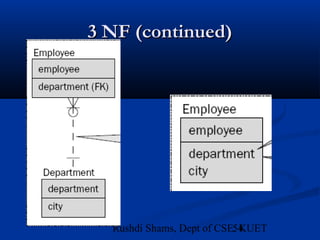

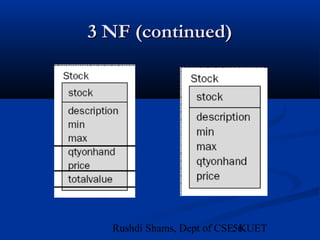
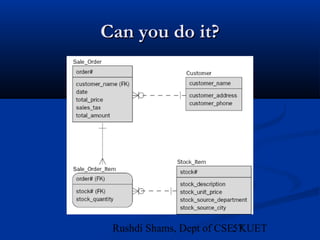
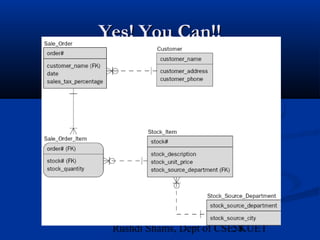




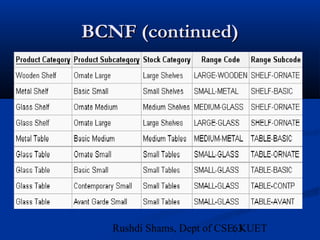











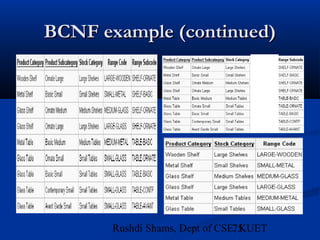
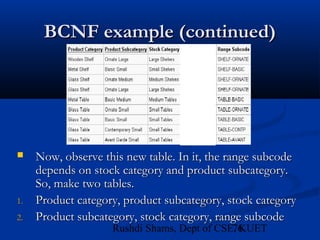

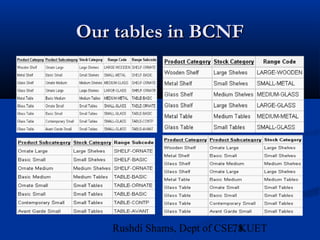










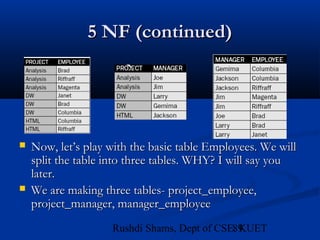
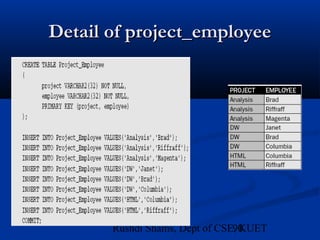
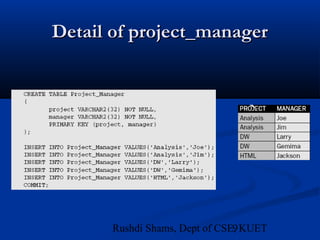
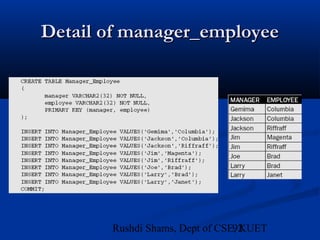











This document provides an overview of database normalization and different normal forms. It defines key terms like functional dependency, determinant, anomalies, candidate keys, and normal forms including 1NF, 2NF and 3NF. The document explains how to normalize a database by removing repeating groups and updating table structures to eliminate anomalies based on functional dependencies between attributes. Examples are provided to illustrate transitions between normal forms by separating tables to remove partial and transitive dependencies.























































































