Download to read offline



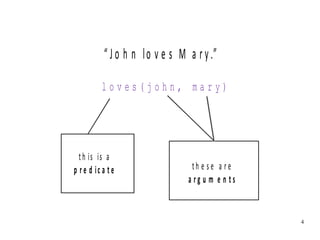
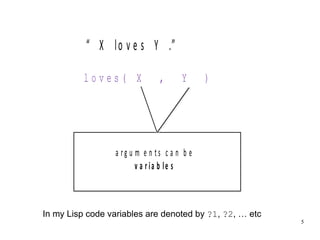




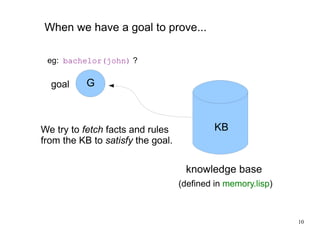
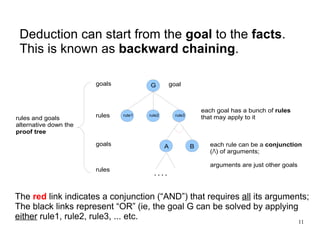
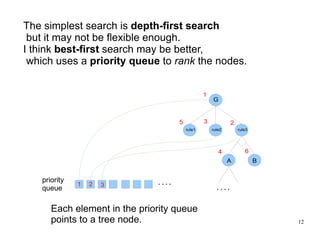
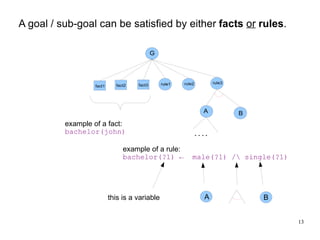
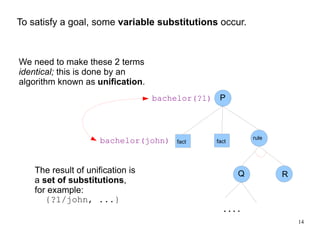
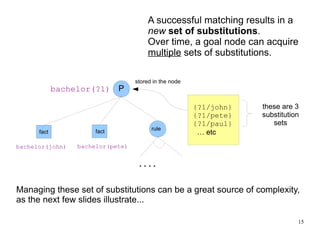

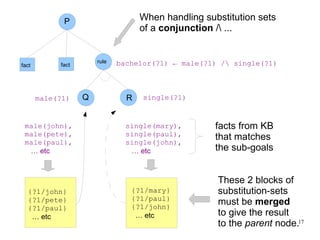
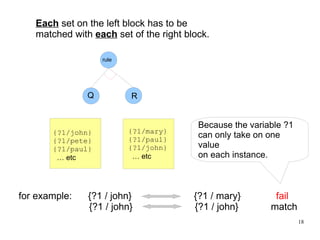
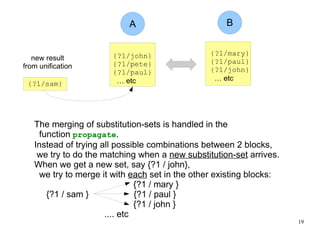
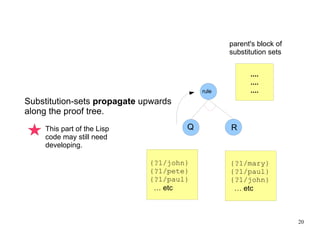
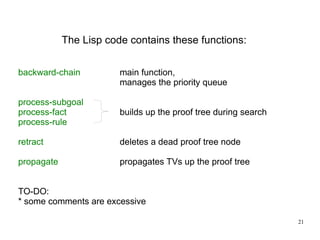

The document introduces the concepts behind the Genifer logic deduction source code. It discusses key concepts such as Horn clauses, unification, substitution sets, and backward chaining used in logical deduction. The code implements a backward chaining search using a priority queue to efficiently solve goals by applying facts and rules from a knowledge base. Managing substitution sets and propagating truth values during the search process introduces complexity that requires further development.



























![Adv math[unit 2]](https://cdn.slidesharecdn.com/ss_thumbnails/advmathunit2-140731091841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































