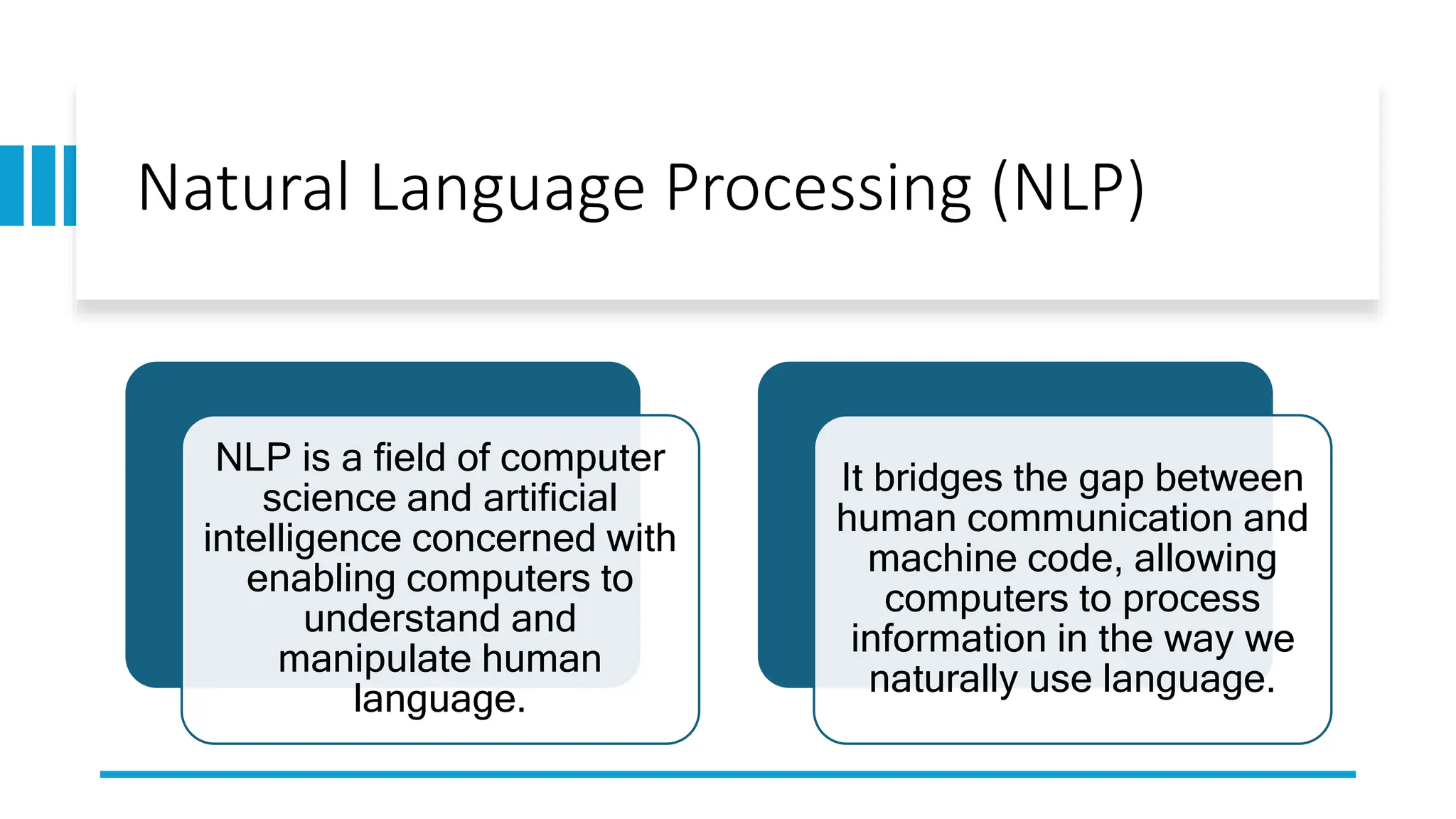
Natural Language Processing (NLP) is a field focused on enabling computers to understand human language and has various applications including machine translation, smart assistants, and chatbots. Key tasks in NLP include tokenization, part-of-speech tagging, and named entity recognition, while challenges involve language ambiguity and informal expressions. Techniques such as text normalization, lemmatization, and machine learning approaches enhance NLP tasks like sentiment analysis and topic modeling.

![Applications of NLP
NLP has a vast range of applications that are woven into our daily lives:
Machine Translation: Breaking down language barriers by translating text or speech from
one language to another [e.g., Google Translate].
Smart Assistants: Responding to voice commands and questions in a natural way [e.g.,
Siri, Alexa, Google Assistant].
Chatbots: Providing customer service or information through automated chat
conversations.](https://image.slidesharecdn.com/week8-module7nlp-240623030140-7434f440/75/Weekairtificial-intelligence-8-Module-7-NLP-pptx-3-2048.jpg)
![Cont...
• Sentiment Analysis: Extracting opinions and emotions from text data [e.g.,
social media monitoring].
• Text Summarization: Condensing large amounts of text into key points.
• Autocorrect and Predictive Text: Suggesting corrections and completions as
you type.
• Spam Filtering: Identifying and blocking unwanted emails.
• Search Engines: Ranking search results based on relevance to your query.](https://image.slidesharecdn.com/week8-module7nlp-240623030140-7434f440/75/Weekairtificial-intelligence-8-Module-7-NLP-pptx-4-2048.jpg)

























![Example:
Document 1: "The cat sat on the mat." Document
2: "The dog chased the cat."
Vocabulary: {the, cat, sat, on, mat, dog, chased}
Document 1 vector: [3, 1, 1, 1, 1, 0, 0] (3
occurrences of "the", etc.) Document 2 vector:
[2, 1, 0, 0, 0, 1, 1]](https://image.slidesharecdn.com/week8-module7nlp-240623030140-7434f440/75/Weekairtificial-intelligence-8-Module-7-NLP-pptx-30-2048.jpg)