Download to read offline



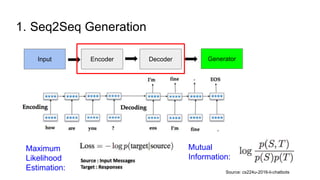
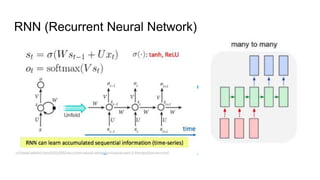




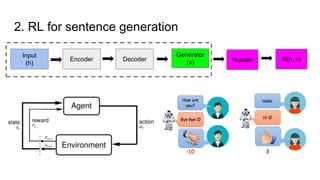


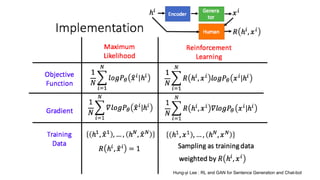





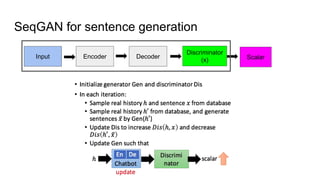


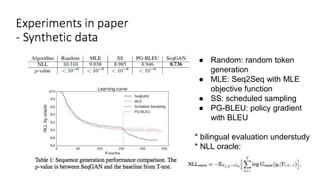





The document discusses various deep learning approaches for dialogue systems, including seq2seq generation, reinforcement learning, and seqgan techniques. It highlights the limitations of traditional models in generating engaging responses and how methods like reinforcement learning improve conversation quality by enhancing informativity and coherence. Furthermore, it demonstrates the effectiveness of seqgan in guiding generative models with discriminative feedback for better performance in synthetic and real-world data.





![[GAN by Hung-yi Lee]Part 2: The application of GAN to speech and text processing](https://cdn.slidesharecdn.com/ss_thumbnails/part2v2-180809095331-thumbnail.jpg?width=640&height=640&fit=bounds)






















































