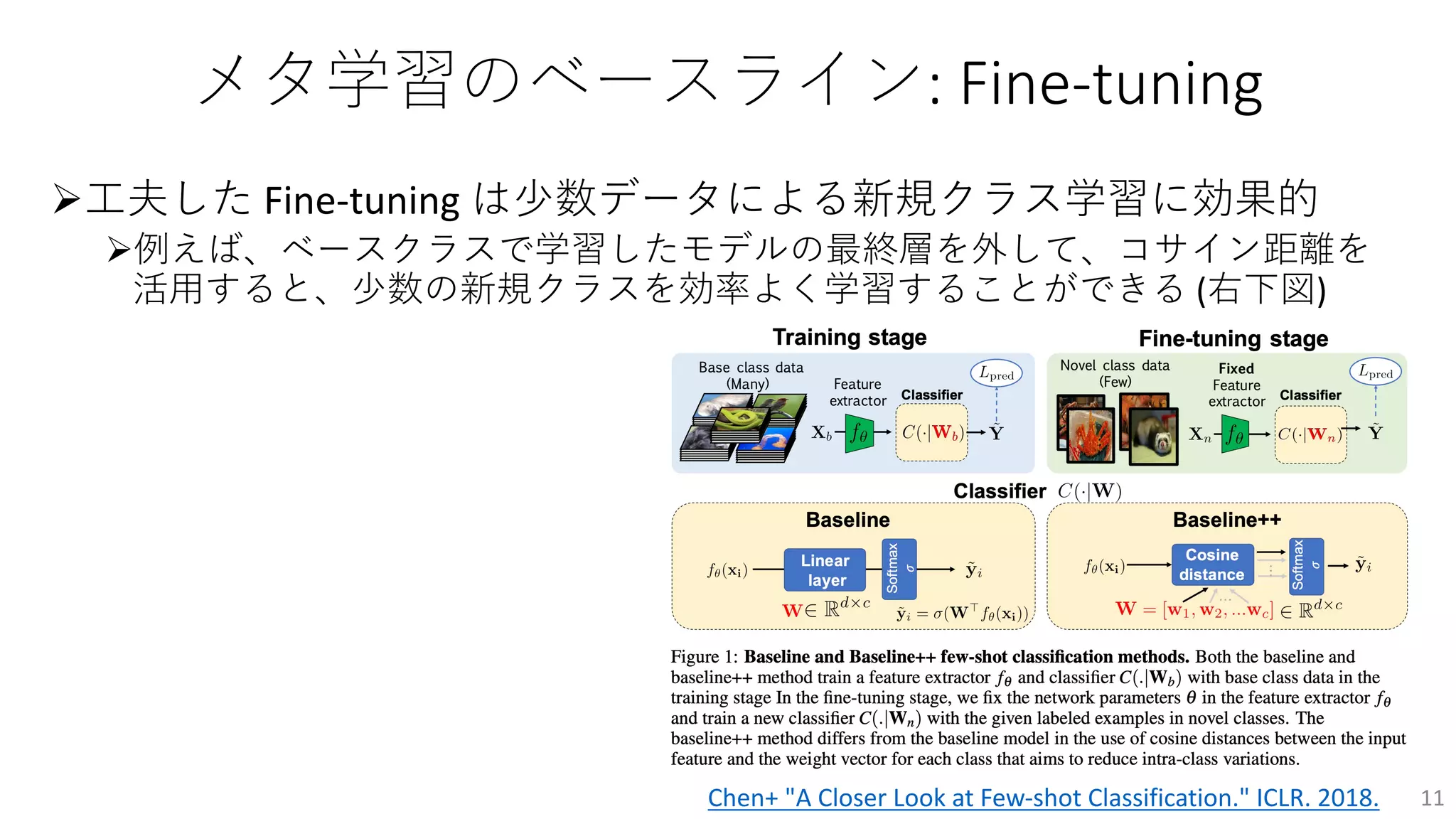
メタ学習がメイントピックの Slotlight
Ø理論
ØGeneralization Boundfor Meta-learning: An Information-Theoretic Analysis [Chen+]
ØBayesian decision-making under mis-specified priors with applications to meta-
learning [Simchowitz+]
Ø応⽤
ØLight Field Networks: Neural Scene Representations with Single-Evaluation Rendering
[Sitzmann+]
ØProperty-Aware Relation Networks for Few-Shot Molecular Property Prediction [Lee+]
ØNAS
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning [Lee+]
ØTask-Adaptive Neural Network Search with Meta-Contrastive Learning [Jeong+]
理論だけでなく、実世界アプリケーションを⾒据えた研究が増加
28
29.
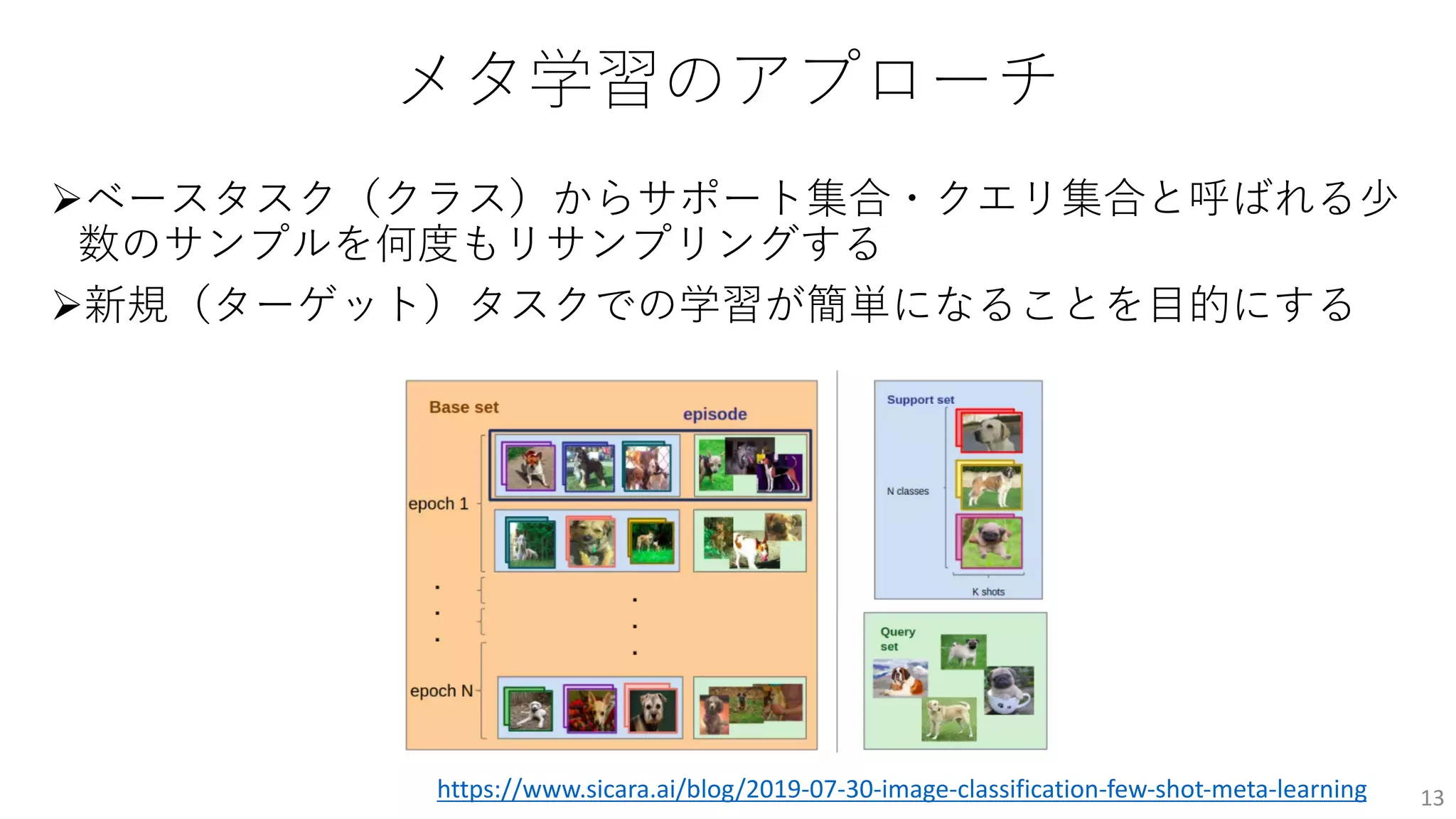
個⼈的注⽬論⽂
ØTask-Adaptive Neural NetworkSearch with Meta-Contrastive Learning
Øアーキテクチャに加えて最適なモデルパラメータも探索する
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning
[Lee+]
Øハードウェア最適なニューラルアーキテクチャ探索をメタ学習として解く
ØTwo Sides of Meta-Learning Evaluation: In vs. Out of Distribution
Ø既存のメタ学習ベンチマークの偏りを指摘
29
Hardware-adaptive Efficient LatencyPrediction for
NAS via Meta-Learning [Lee+]
ØNASはハードウェアを拘束条件に含めるべき
Øメモリ量、遅延、電⼒消費など
Ø現実世界には数え切れないほどのデバイスがある
ØそれぞれにNASで最適化するのは計算量的に⼤変
Øメタ学習の問題として、未知のデバイスにアーキテクチャを最適化!
35
35.
Hardware-adaptive Efficient LatencyPrediction for
NAS via Meta-Learning [Lee+]
Ø提案⼿法: Hardware-adaptive Efficient Latency Predictor (HELP)
Ø少ないサンプル数からハードウェア固有の遅延を予測する問題に帰着
36
Two Sides ofMeta-Learning Evaluation:
In vs. Out of Distribution [Setlur+]
Øメタ学習⼿法の評価⽅法は2つに⼤分される
ØIn-distribution (ID): ターゲットタスクが同じタスク分布にある
ØOut-of-distribution (OOD): ターゲットタスクが異なるタスク分布にある
Ø既存のメタ学習⼿法、メタ学習評価⽅法の問題点
Ø⼤半のメタ学習評価⽅法は OOD
Øほとんどのメタ学習⼿法は OOD で性能向上する⼀⽅、ID だとむしろ下がる
38
38.
Two Sides ofMeta-Learning Evaluation:
In vs. Out of Distribution [Setlur+]
Øベンチマーク改善のための提案
Ø評価時により多くの新規クラスを利⽤すること
Øより多くのベースクラスで学習すること
39
39.
NeurIPS2021 メタ学習のまとめ
Ø理論的な研究はもちろん、実⽤・応⽤を重視した研究が注⽬
Ø近い研究分野(NASなど)と絡めた研究が多数 spotlightに採択
Øメタ学習のベンチマーク、問題設定に問題提起をする論⽂も
Ø議論がかなり深まりつつある分野となっている
ØTask-Adaptive Neural Network Search with Meta-Contrastive Learning
Øアーキテクチャに加えて最適なモデルパラメータも探索する
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning [Lee+]
Øハードウェア最適なニューラルアーキテクチャ探索をメタ学習として解く
ØTwo Sides of Meta-Learning Evaluation: In vs. Out of Distribution
Ø既存のメタ学習ベンチマークの偏りを指摘
40







![メタ学習の分類学
Øメタ学習実現のためのアプローチ(Optimizer, Representation, Objective)
Ø⽬的(Application)
15
[Hospedales+] "Meta-Learning in Neural Networks: A Survey." IEEE TPAMI (2021).](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-15-2048.jpg)


![代表的なメタ学習の⼿法
ØMAML [Finn+, ICML2017]
Ø勾配ベースの⼿法
ØFine-tuningした際にテスト性能が⾼くなるようなモデルパラメータを勾配法
ØNeural process [Gordon+, ICLR2019]
Øブラックボックス適応の⼿法
Ø各タスクへのfine-tuningをNNでモデル化して勾配計算を避ける
ØProtoNet [Snell+, NeurIPS2017]
Øモデルベースの⼿法
Øタスク特化モデル(Fine-tuning)に勾配計算が容易なモデルを利⽤
18](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-18-2048.jpg)
![MAML [Finn+, NeurIPS2017]
Ø引⽤5000+
ØFine-tuning後の性能が⾼くなるように事前学習⽤モデルのパラメータ
を更新
Ø+: メモリ
19
Fine-tuning
←タスク共通パラメータ初期化
← サンプリング
←タスク共通パラメータ更新](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-19-2048.jpg)
![MAML [Finn+, NeurIPS2017]
ØJ
Ø任意の微分可能なモデルをメタ学習できる
ØL
Øメモリ計算量が Fine-tuning の
ステップ数に⽐例して線形に増加する
ØFine-tuning のステップ数を⼤きくするのは
難しい
Ø初期値から数ステップ以内の
勾配降下で⽬的タスクに適合しなければ
いけない
Ø勾配の計算がとにかく⼤変
20
Fine-tuning
←タスク共通パラメータ初期化
← サンプリング
←タスク共通パラメータ更新](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-20-2048.jpg)
![Neural process [Gordon+, ICLR2019]
Ø各タスクへのfine-tuningをNNでモデル化して勾配計算を避ける
Øラベル付きサポート集合 𝒟" = { 𝒙#, 𝑦# } から ニュラールネット: ℎ を⽤いて
特徴量 r% = ℎ(𝒙#, 𝑦#)を計算
Øサポート集合の平均 r = Σ
& 𝒙!,)!
|𝒟"|
Øタスク表現 r と特徴量 𝒙 から Fine-tuning されたニューラルネットに相当する𝑔
を⽤いて予測 6
𝑦 = 𝑔(𝒙, 𝒓) を得る
21
https://www.kecl.ntt.co.jp/as/members/iwata/ibisml2021.pdf](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-21-2048.jpg)
![Neural process [Gordon+, ICLR2019]
ØJ
Ø勾配の勾配を計算しなくてよい
ØDNN で Fine-tuning をモデル化している
Ø勾配ベースの⼿法と⽐べて、数ステップの勾配降下で⽬的タスクにたどり着かなければい
けない、という制限はない
ØL
Øそもそも Fine-tuning のモデル化は単純な教師あり学習より複雑
Ø学習がうまく進まないことがある
Ø例えサポート集合(train)に含まれるサンプルでも正しく予測できない場合あり
22](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-22-2048.jpg)
![ProtoNet [Snell+, NeurIPS’2017]
Øタスク特化モデルに勾配計算が容易なモデルを利⽤
23
タスク特化
モデル
タスク共通
モデル
Fine-tuning有
混合正規分布
Fine-tuning無
DNN
各クラスの平均値をサポート集合で計算
クエリ集合に対する損失を計算](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-23-2048.jpg)
![ProtoNet [Snell+, NeurIPS2017]
ØJ
ØFine-tuning のために勾配計算を繰り返す必要なし
Ø微分の計算が軽い
Ø過学習しにくい
ØL
Ø表現⼒に劣る
Øタスク特化部分(⾮DNN)の
表現⼒に依存する
24
タスク特化
モデル
タスク共通
モデル
Fine-tuning有
混合正規分布
Fine-tuning無
DNN](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-24-2048.jpg)
![メタ学習の代表的な⼿法と課題 のまとめ
ØMAML [Finn+, ICML2017]
Ø勾配ベースの⼿法
ØFine-tuningした際にテスト性能が⾼くなるようなモデルパラメータを勾配法
ØNeural process [Gordon+, ICLR2019]
Øブラックボックス適応の⼿法
Ø各タスクへのfine-tuningをNNでモデル化して勾配計算を避ける
ØProtoNet [Snell+, NeurIPS2017]
Øモデルベースの⼿法
Øタスク特化モデル(Fine-tuning)に勾配計算が容易なモデルを利⽤
25](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-25-2048.jpg)


![メタ学習がメイントピックの Slotlight
Ø理論
ØGeneralization Bound for Meta-learning: An Information-Theoretic Analysis [Chen+]
ØBayesian decision-making under mis-specified priors with applications to meta-
learning [Simchowitz+]
Ø応⽤
ØLight Field Networks: Neural Scene Representations with Single-Evaluation Rendering
[Sitzmann+]
ØProperty-Aware Relation Networks for Few-Shot Molecular Property Prediction [Lee+]
ØNAS
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning [Lee+]
ØTask-Adaptive Neural Network Search with Meta-Contrastive Learning [Jeong+]
理論だけでなく、実世界アプリケーションを⾒据えた研究が増加
28](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-28-2048.jpg)
![個⼈的注⽬論⽂
ØTask-Adaptive Neural Network Search with Meta-Contrastive Learning
Øアーキテクチャに加えて最適なモデルパラメータも探索する
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning
[Lee+]
Øハードウェア最適なニューラルアーキテクチャ探索をメタ学習として解く
ØTwo Sides of Meta-Learning Evaluation: In vs. Out of Distribution
Ø既存のメタ学習ベンチマークの偏りを指摘
29](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-29-2048.jpg)
![Task-Adaptive Neural Network Search with
Meta-Contrastive Learning [Jeong+, NeurIPS’21]
Ø既存のNAS⼿法の問題点
Ø計算コストが膨⼤
Øネットワークアーキテクチャは最適化するが、パラメータは決定しない
ØNASでアーキテクチャを最適化した後、パラメータは別途学習により最適化する必要あり
Ø⽬的
Ø最適なネットワークアーキテクチャだけでなく、
メタ学習的に最適な初期重みも得られないだろうか?
30](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-30-2048.jpg)
![Task-Adaptive Neural Network Search with
Meta-Contrastive Learning [Jeong+, NeurIPS’21]
Ø⽬的
Ø最適なネットワークアーキテクチャだけでなく、
メタ学習的に最適な初期重みも得られないだろうか?
31](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-31-2048.jpg)
![Task-Adaptive Neural Network Search with
Meta-Contrastive Learning [Jeong+, NeurIPS’21]
Ø提案⼿法
Ø関係ないデータセットで学習したネットワークとの類似度を最⼩化しつつ、
⽬的ネットワークとデータセットの類似度を最⼤化するようメタ学習する
ØModel Zoo の構築と Retrieval の⼆段階
32](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-32-2048.jpg)
![Task-Adaptive Neural Network Search with
Meta-Contrastive Learning [Jeong+, NeurIPS’21]
Øパラメータ効率、FLOPS効率が改善する
33](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-33-2048.jpg)
![Hardware-adaptive Efficient Latency Prediction for
NAS via Meta-Learning [Lee+]
ØNASはハードウェアを拘束条件に含めるべき
Øメモリ量、遅延、電⼒消費など
Ø現実世界には数え切れないほどのデバイスがある
ØそれぞれにNASで最適化するのは計算量的に⼤変
Øメタ学習の問題として、未知のデバイスにアーキテクチャを最適化!
35](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-34-2048.jpg)
![Hardware-adaptive Efficient Latency Prediction for
NAS via Meta-Learning [Lee+]
Ø提案⼿法: Hardware-adaptive Efficient Latency Predictor (HELP)
Ø少ないサンプル数からハードウェア固有の遅延を予測する問題に帰着
36](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-35-2048.jpg)
![Hardware-adaptive Efficient Latency Prediction for
NAS via Meta-Learning [Lee+]
Ø少サンプルでも適切に遅延時間を予測することができる
37](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-36-2048.jpg)
![Two Sides of Meta-Learning Evaluation:
In vs. Out of Distribution [Setlur+]
Øメタ学習⼿法の評価⽅法は2つに⼤分される
ØIn-distribution (ID): ターゲットタスクが同じタスク分布にある
ØOut-of-distribution (OOD): ターゲットタスクが異なるタスク分布にある
Ø既存のメタ学習⼿法、メタ学習評価⽅法の問題点
Ø⼤半のメタ学習評価⽅法は OOD
Øほとんどのメタ学習⼿法は OOD で性能向上する⼀⽅、ID だとむしろ下がる
38](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-37-2048.jpg)
![Two Sides of Meta-Learning Evaluation:
In vs. Out of Distribution [Setlur+]
Øベンチマーク改善のための提案
Ø評価時により多くの新規クラスを利⽤すること
Øより多くのベースクラスで学習すること
39](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-38-2048.jpg)
![NeurIPS2021 メタ学習のまとめ
Ø理論的な研究はもちろん、実⽤・応⽤を重視した研究が注⽬
Ø近い研究分野(NASなど)と絡めた研究が多数 spotlight に採択
Øメタ学習のベンチマーク、問題設定に問題提起をする論⽂も
Ø議論がかなり深まりつつある分野となっている
ØTask-Adaptive Neural Network Search with Meta-Contrastive Learning
Øアーキテクチャに加えて最適なモデルパラメータも探索する
ØHardware-adaptive Efficient Latency Prediction for NAS via Meta-Learning [Lee+]
Øハードウェア最適なニューラルアーキテクチャ探索をメタ学習として解く
ØTwo Sides of Meta-Learning Evaluation: In vs. Out of Distribution
Ø既存のメタ学習ベンチマークの偏りを指摘
40](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-39-2048.jpg)



![Efficiently Identifying Task Groupings for
Multi-Task Learning [Fifty+, NeurIPS21]
ØMulti-task learning において、単⼀のモデルで考えうる全てのタスクを
学習すると性能が下がってしまう。故に、⼀緒に学習するのに適した
タスクを発⾒する必要がある。
Ø本論⽂の⼿法では、 Computer Visionの taskonomyのようなデータセッ
トに対して、どのタスクとどのタスクを共に学習するとよいか⼀度の
学習のみで選ぶ⽅法を提案する。実験により、性能が上がると⽰され
た。
45](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-44-2048.jpg)
![MAML [Finn+, NeurIPS2017]
ØMAML を改良した勾配ベースの⼿法が数多く提案されている
Øモデルパラメータ更新の⽅法を変えている
46
https://sites.google.com/mit.edu/aaai2021metalearningtutorial/home](https://image.slidesharecdn.com/neurips21-220311054324/75/NeurIPS2021-83-2022-3-7-AI-NeurIPS2021-AI-1-45-2048.jpg)



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network](https://cdn.slidesharecdn.com/ss_thumbnails/maml-181024060235-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)