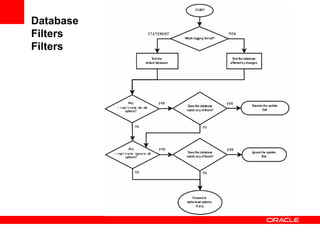
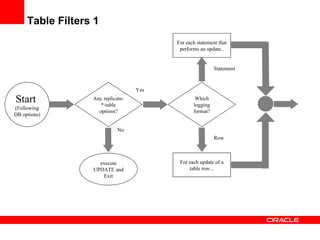
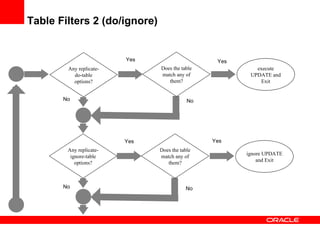
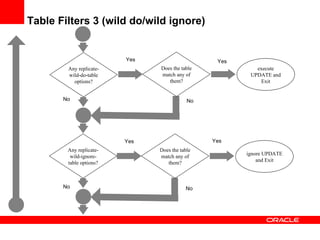
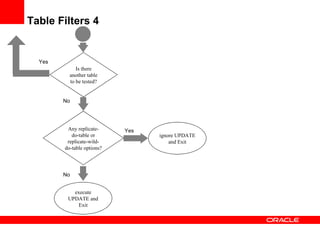
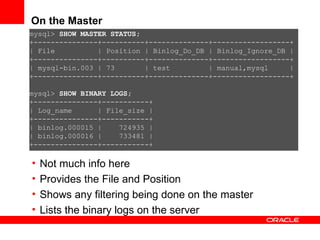
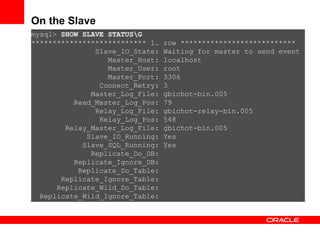
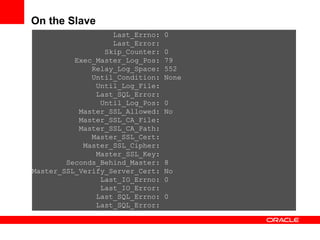
Replication with MySQL allows data changes on a master server to be replicated to slave servers. The master writes changes to its binary log which is used by slave servers to copy the changes and apply them to their own data. Replication can be used for scaling reads, data redundancy, analytics, and geographic distribution. It involves configuring servers, creating replication users, and starting the replication process on slaves. Filtering rules allow control over which databases, tables, or operations are replicated. Monitoring provides information on replication status, filters, binary logs, and any errors.


![Replication with MySQL 5.1 Ligaya Turmelle Senior Technical Support Engineer - MySQL [email_address] http://joind.in/1573 <Insert Picture Here>](https://image.slidesharecdn.com/replication-100521143218-phpapp01/85/MySQL-5-1-Replication-2-320.jpg)




















![mysql> CHANGE MASTER TO -> MASTER_HOST=' master_host_name ', -> MASTER_USER=' replication_user_name ', -> MASTER_PASSWORD=' replication_password ', -> [ MASTER_PORT = port_num,] -> MASTER_LOG_FILE=' recorded_log_file_name ', -> MASTER_LOG_POS= recorded_log_position, -> [MASTER_SSL = {0|1},] -> [MASTER_SSL_CA = ' ca_file_name ',] -> [MASTER_SSL_CAPATH = ' ca_directory_name ',] -> [MASTER_SSL_CERT = ' cert_file_name ',] -> [MASTER_SSL_KEY = ' key_file_name ',] -> [MASTER_SSL_CIPHER = ' cipher_list ',] -> [MASTER_SSL_VERIFY_SERVER_CERT = {0|1}] ;](https://image.slidesharecdn.com/replication-100521143218-phpapp01/85/MySQL-5-1-Replication-23-320.jpg)