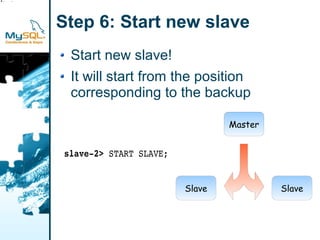
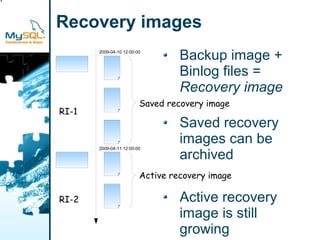
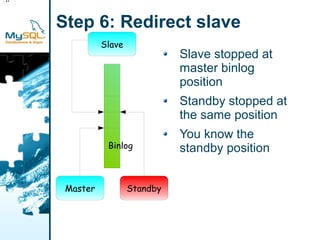
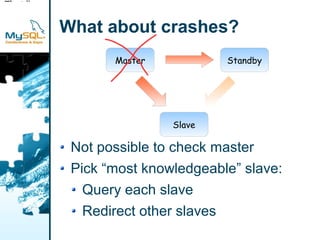
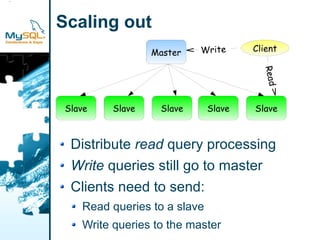
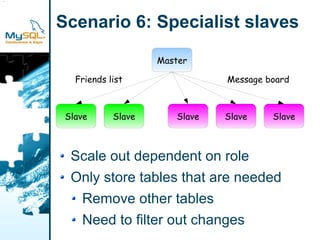
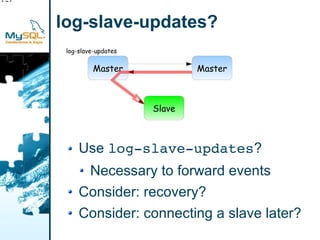
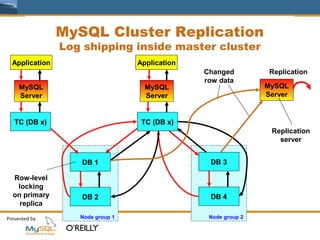
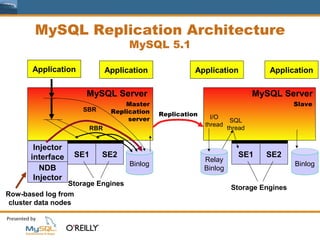
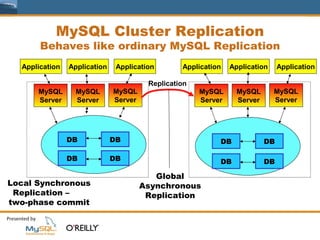
This document provides an overview of MySQL replication including basic concepts, terminology, and configuration steps. It discusses four replication scenarios: 1) setting up a single slave for backups and reporting; 2) adding a new slave by bootstrapping from an existing slave; 3) performing point-in-time recovery using binary logs; and 4) promoting a slave to a standby master for maintenance. Key aspects covered include configuring replication, taking backups, synchronizing slave positions, and switching over connections during a failover.














![Step 1: Fix my.cnf
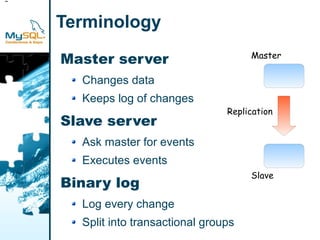
Master my.cnf Slave my.cnf
[mysqld] [mysqld]
tmpdir = /tmp tmpdir = /tmp
language =.../share/english language = .../share/english
pidfile =.../run/master.pid pidfile = .../run/slave.pid
datadir = .../data datadir = .../data
serverid = 1 serverid = 2
port = 12000 port = 12001
logbin = .../log/masterbin socket = /tmp/mysqld.sock
socket = /tmp/master.sock basedir = ...
basedir = ... relaylogindex =...
relaylog = ...](https://image.slidesharecdn.com/replicationtutorialpresentation-110722035258-phpapp01/85/Replication-tutorial-presentation-19-320.jpg)























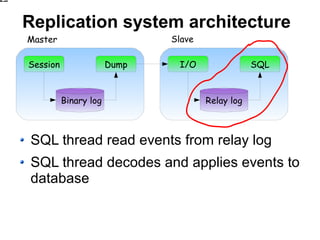
![Step 1: Configure standby
Configure standby to log replicated
events
logslaveupdates
[mysqld]
...
logslaveupdates](https://image.slidesharecdn.com/replicationtutorialpresentation-110722035258-phpapp01/85/Replication-tutorial-presentation-45-320.jpg)

















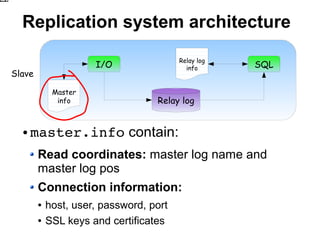
![Step 2: Edit my.cnf
[mysqld] [mysqld]
... ...
replicatedotable=user replicatedotable=user
replicatedotable=friend replicatedotable=message
Friends slave Message board slave
Add slave filtering rules to my.cnf
Multiple options for multiple rules](https://image.slidesharecdn.com/replicationtutorialpresentation-110722035258-phpapp01/85/Replication-tutorial-presentation-68-320.jpg)











































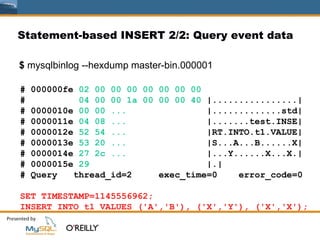























![[오픈소스컨설팅] 프로메테우스 모니터링 살펴보고 구성하기](https://cdn.slidesharecdn.com/ss_thumbnails/oscprometheus-190422050231-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































