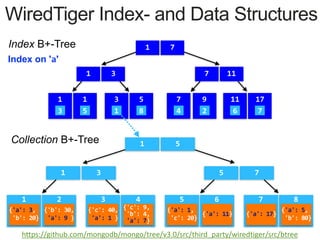
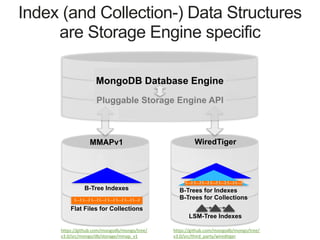
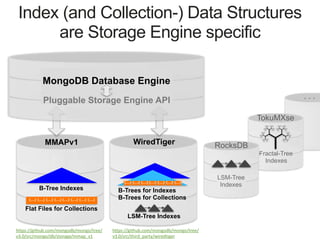
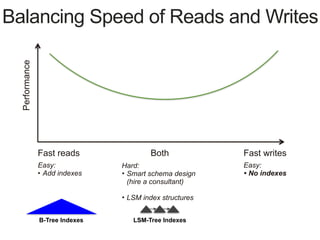
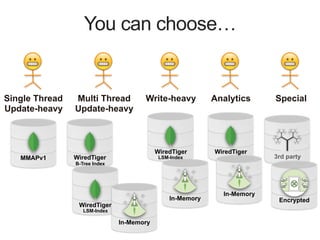
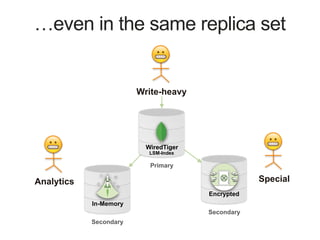
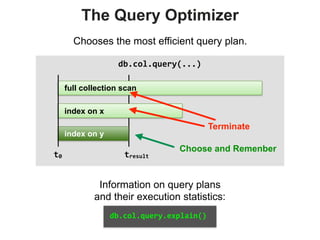
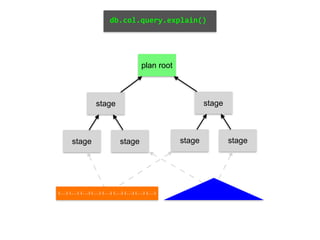
Downloaded 128 times






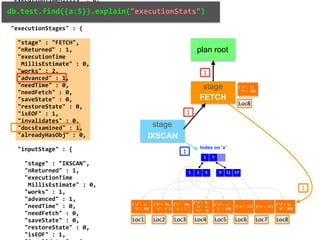
![db.test.find({a:5}).explain()
{
"queryPlanner" : {
[...],
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
}
}
}
},
[...]
}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-46-320.jpg)
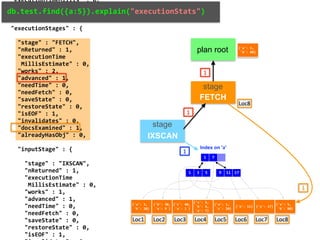
![db.test.find({a:5}).explain()
plan root
stage
FETCH
stage
IXSCAN
{
"queryPlanner" : {
[...],
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
}
}
}
},
[...]
}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-47-320.jpg)
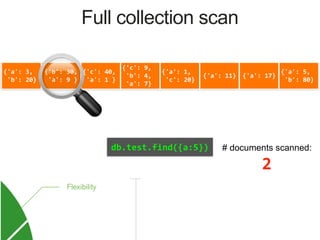
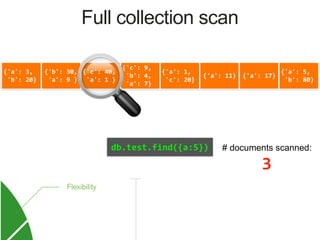
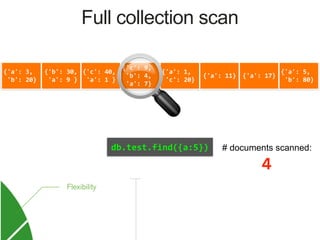
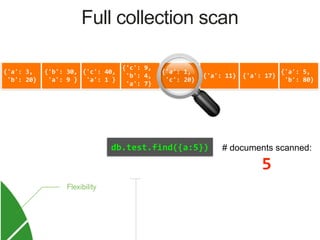
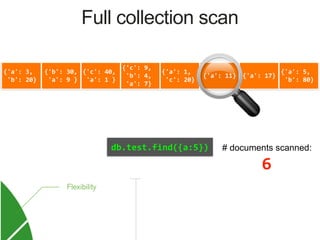
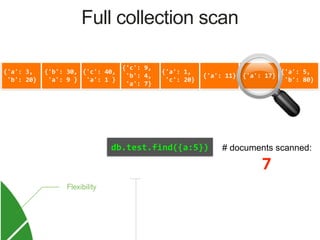
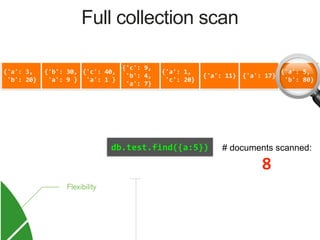
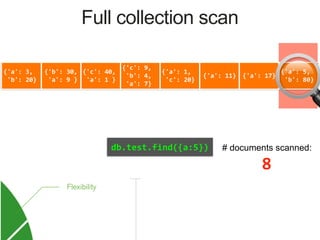
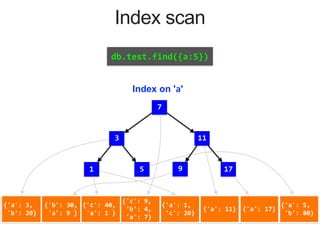
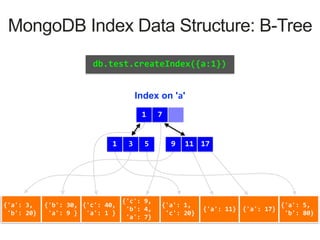
![{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
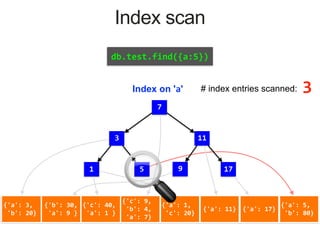
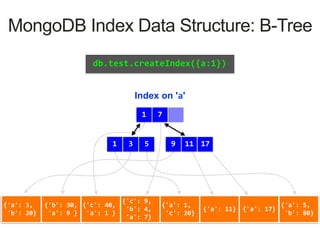
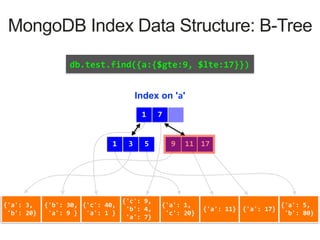
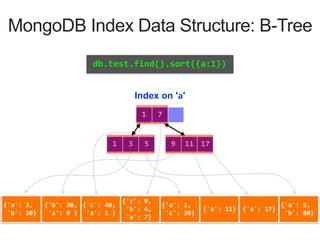
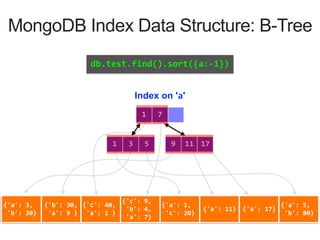
Index on 'a'
1 7
3 51 17119
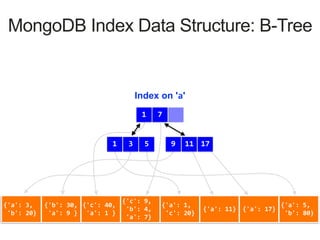
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})
db.test.find({a:5}).explain()
{
"queryPlanner" : {
[...],
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
}
}
}
},
[...]
}
stage
FETCH
plan root
stage
IXSCAN](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-48-320.jpg)

![{
[...],
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0,
"totalKeysExamined" : 1,
"totalDocsExamined" : 1,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 2,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
db.test.find({a:5}).explain("executionStats")db.test.find({a:5}).explain()
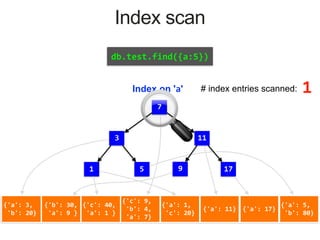
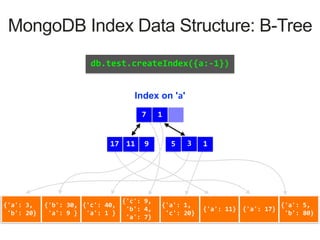
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
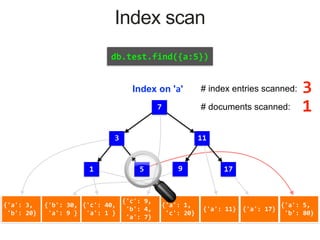
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})
stage
IXSCAN
stage
FETCH
plan root](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-50-320.jpg)
!["invalidates" : 0,
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 1,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
},
"keysExamined" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
db.test.find({a:5}).explain("executionStats")db.test.find({a:5}).explain()
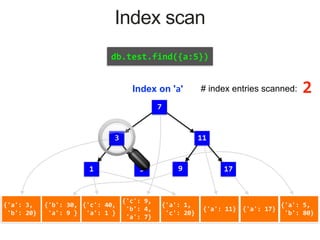
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
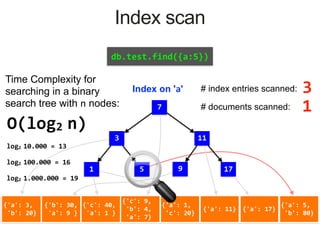
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})
stage
IXSCAN
stage
FETCH
plan root
1
1
Loc1 Loc6Loc3 Loc4 Loc5Loc2 Loc7 Loc8Loc8
!!](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-51-320.jpg)
!["invalidates" : 0,
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 1,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
},
"keysExamined" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
db.test.find({a:5}).explain("executionStats")db.test.find({a:5}).explain()
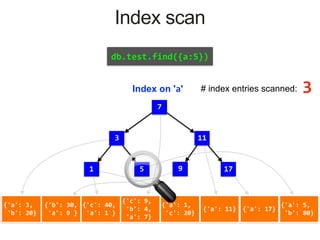
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})
stage
IXSCAN
stage
FETCH
plan root
1
1
Loc8
Loc1 Loc6Loc3 Loc4 Loc5Loc2 Loc7 Loc8](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-52-320.jpg)
!["invalidates" : 0,
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 1,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
},
"keysExamined" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
db.test.find({a:5}).explain("executionStats")db.test.find({a:5}).explain()
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})
stage
IXSCAN
stage
FETCH
plan root
1
1
Loc8
Loc1 Loc6Loc3 Loc4 Loc5Loc2 Loc7 Loc8](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-53-320.jpg)
!["docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 1,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
},
"keysExamined" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
}
Explain() method key metrics
# documents returned
How long did the query take
# index entries scanned
# documents scanned
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-56-320.jpg)
![Index used? Which one?
"docsExamined" : 1,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTime
MillisEstimate" : 0,
"works" : 1,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"a" : 5
},
"indexName" : "a_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"a" : [
"[5.0, 5.0]"
]
},
"keysExamined" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0
}
Explain() method key metrics
"IXSCAN"
"indexName" : "a_1"
# documents returned
How long did the query take
# index entries scanned
# documents scanned
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
Index on 'a'
1 7
3 51 17119
MongoDB Index Data Structure: B-Tree
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
db.test.createIndex({a:1})](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-57-320.jpg)

![United States Postal Service ZIP-Codes
db.zips.find() 29353 documents
media.mongodb.org/zips.json
{ "zip" : "01001", "city" : "AGAWAM", "loc" : [ -72.622739, 42.070206 ], "pop" : 15338, "state" : "MA" }
{ "zip" : "01002", "city" : "CUSHMAN", "loc" : [ -72.51564999999999, 42.377017 ], "pop" : 36963, "state" : "MA" }
{ "zip" : "01005", "city" : "BARRE", "loc" : [ -72.10835400000001, 42.409698 ], "pop" : 4546, "state" : "MA" }
{ "zip" : "01007", "city" : "BELCHERTOWN", "loc" : [ -72.41095300000001, 42.275103 ], "pop" : 10579, "state" : "MA" }
{ "zip" : "01008", "city" : "BLANDFORD", "loc" : [ -72.936114, 42.182949 ], "pop" : 1240, "state" : "MA" }
{ "zip" : "01010", "city" : "BRIMFIELD", "loc" : [ -72.188455, 42.116543 ], "pop" : 3706, "state" : "MA" }
{ "zip" : "01011", "city" : "CHESTER", "loc" : [ -72.988761, 42.279421 ], "pop" : 1688, "state" : "MA" }
{ "zip" : "01012", "city" : "CHESTERFIELD", "loc" : [ -72.833309, 42.38167 ], "pop" : 177, "state" : "MA" }
{ "zip" : "01013", "city" : "CHICOPEE", "loc" : [ -72.607962, 42.162046 ], "pop" : 23396, "state" : "MA" }
{ "zip" : "01020", "city" : "CHICOPEE", "loc" : [ -72.576142, 42.176443 ], "pop" : 31495, "state" : "MA" }
{ "zip" : "01022", "city" : "WESTOVER AFB", "loc" : [ -72.558657, 42.196672 ], "pop" : 1764, "state" : "MA" }
{ "zip" : "01026", "city" : "CUMMINGTON", "loc" : [ -72.905767, 42.435296 ], "pop" : 1484, "state" : "MA" }
{ "zip" : "01027", "city" : "MOUNT TOM", "loc" : [ -72.67992099999999, 42.264319 ], "pop" : 16864, "state" : "MA" }
{ "zip" : "01028", "city" : "EAST LONGMEADOW", "loc" : [ -72.505565, 42.067203 ], "pop" : 13367, "state" : "MA" }
{ "zip" : "01030", "city" : "FEEDING HILLS", "loc" : [ -72.675077, 42.07182 ], "pop" : 11985, "state" : "MA" }
{ "zip" : "01031", "city" : "GILBERTVILLE", "loc" : [ -72.19858499999999, 42.332194 ], "pop" : 2385, "state" : "MA" }
{ "zip" : "01032", "city" : "GOSHEN", "loc" : [ -72.844092, 42.466234 ], "pop" : 122, "state" : "MA" }
{ "zip" : "01033", "city" : "GRANBY", "loc" : [ -72.52000099999999, 42.255704 ], "pop" : 5526, "state" : "MA" }
{ "zip" : "01034", "city" : "TOLLAND", "loc" : [ -72.908793, 42.070234 ], "pop" : 1652, "state" : "MA" }
{ "zip" : "01035", "city" : "HADLEY", "loc" : [ -72.571499, 42.36062 ], "pop" : 4231, "state" : "MA" }](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-59-320.jpg)
![Question
Zip codes in New York City with population more than
100,000 ordered by population in descending order
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
{"zip" : "10021", "city" : "NEW YORK", "pop" : 106564, "state" : "NY" }
{"zip" : "10025", "city" : "NEW YORK", "pop" : 100027, "state" : "NY" }
{ "zip" : "99921", "city" : "CRAIG", "loc" : [ -133.117081, 55.47317 ], "pop" : 1398, "state" : "AK" }
{ "zip" : "99922", "city" : "HYDABURG", "loc" : [ -132.633175, 55.137406 ], "pop" : 891, "state" : "AK" }
{ "zip" : "99923", "city" : "HYDER", "loc" : [ -130.124915, 55.925867 ], "pop" : 116, "state" : "AK" }
{ "zip" : "99925", "city" : "KLAWOCK", "loc" : [ -133.055503, 55.552611 ], "pop" : 851, "state" : "AK" }
{ "zip" : "99926", "city" : "METLAKATLA", "loc" : [ -131.579001, 55.121491 ], "pop" : 1469, "state" : "AK" }
{ "zip" : "99927", "city" : "POINT BAKER", "loc" : [ -133.376372, 56.307858 ], "pop" : 426, "state" : "AK" }
{ "zip" : "99929", "city" : "WRANGELL", "loc" : [ -132.352918, 56.433524 ], "pop" : 2573, "state" : "AK" }
{ "zip" : "99950", "city" : "KETCHIKAN", "loc" : [ -133.18479, 55.942471 ], "pop" : 422, "state" : "AK" }](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-60-320.jpg)






![}
},
{
"pop" : {
"$gt" : 100000
}
}
]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 29353,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 29359,
"advanced" : 2,
"needTime" : 29355,
"needFetch" : 0,
"saveState" : 229,
"restoreState" : 229,
"isEOF" : 1,
"invalidates" : 0,
"sortPattern" : {
"pop" : -1
.explain("executionStats")
{...} {...} {...} {...} {...} {...} {...} {...} {...}
plan root
SORT
COLLSCAN
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Collection Scan!
No Index](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-67-320.jpg)
![}
},
{
"pop" : {
"$gt" : 100000
}
}
]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 29353,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 29359,
"advanced" : 2,
"needTime" : 29355,
"needFetch" : 0,
"saveState" : 229,
"restoreState" : 229,
"isEOF" : 1,
"invalidates" : 0,
"sortPattern" : {
"pop" : -1
.explain("executionStats")
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returnedplan root
SORT
COLLSCAN
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Collection Scan!
No Index](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-68-320.jpg)
![}
},
{
"pop" : {
"$gt" : 100000
}
}
]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 29353,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 29359,
"advanced" : 2,
"needTime" : 29355,
"needFetch" : 0,
"saveState" : 229,
"restoreState" : 229,
"isEOF" : 1,
"invalidates" : 0,
"sortPattern" : {
"pop" : -1
.explain("executionStats")
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
29353 documents scanned
plan root
SORT
COLLSCAN
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Collection Scan!
No Index](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-69-320.jpg)
![}
},
{
"pop" : {
"$gt" : 100000
}
}
]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 29353,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 29359,
"advanced" : 2,
"needTime" : 29355,
"needFetch" : 0,
"saveState" : 229,
"restoreState" : 229,
"isEOF" : 1,
"invalidates" : 0,
"sortPattern" : {
"pop" : -1
.explain("executionStats")
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
29353 documents scanned
plan root
SORT
COLLSCAN
In-Memory Sort!
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Collection Scan!
No Index](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-70-320.jpg)




!["pop": -1
},
"inputStage": {
"stage": "FETCH",
"filter": {
"$and": [
{
"city": {
"$eq": "NEW YORK"
}
},
{
"pop": {
"$gt": 100000
}
}
]
},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1
},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-75-320.jpg)
!["pop": -1
},
"inputStage": {
"stage": "FETCH",
"filter": {
"$and": [
{
"city": {
"$eq": "NEW YORK"
}
},
{
"pop": {
"$gt": 100000
}
}
]
},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1
},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-76-320.jpg)
![},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 6,
"totalKeysExamined": 1595,
"totalDocsExamined": 1595,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 1600,
"advanced": 2,
"needTime": 1596,
"needFetch": 0,
"saveState": 12,
"restoreState": 12,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-77-320.jpg)
![},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 6,
"totalKeysExamined": 1595,
"totalDocsExamined": 1595,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 1600,
"advanced": 2,
"needTime": 1596,
"needFetch": 0,
"saveState": 12,
"restoreState": 12,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
2 documents returned
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-78-320.jpg)
![},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 6,
"totalKeysExamined": 1595,
"totalDocsExamined": 1595,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 1600,
"advanced": 2,
"needTime": 1596,
"needFetch": 0,
"saveState": 12,
"restoreState": 12,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
2 documents returned
1595 index entries scanned
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-79-320.jpg)
![},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 6,
"totalKeysExamined": 1595,
"totalDocsExamined": 1595,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 1600,
"advanced": 2,
"needTime": 1596,
"needFetch": 0,
"saveState": 12,
"restoreState": 12,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
2 documents returned
1595 documents scanned
1595 index entries scanned
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-80-320.jpg)
![},
"indexName": "state_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
]
}
}
}
},
"rejectedPlans": []
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 6,
"totalKeysExamined": 1595,
"totalDocsExamined": 1595,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 1600,
"advanced": 2,
"needTime": 1596,
"needFetch": 0,
"saveState": 12,
"restoreState": 12,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
Single Field Index
db.zips.createIndex({state:1})
plan root
SORT
FETCH
IXSCAN
2 documents returned
1595 documents scanned
1595 index entries scanned
In-Memory Sort!
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-81-320.jpg)
![db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.createIndex({state:1})
NY NY NY NY NY NY NY NY NY NY NY NY NY NY NY OH OH OH OH OH OH OH OH OH O
NY TX
NY
NY OH OK OR
{ "state" : "NY", "city" : "NEW YORK", "pop" : 106564, "zip" : "10021", "loc" : [ -73.958805, 40.768476 ] }
{ "state" : "NY", "city" : "NORTH TARRYTOWN", "pop" : 20080, "zip" : "10591", "loc" : [ -73.859335, 41.078108 ] }
{ "state" : "NY", "city" : "YONKERS", "pop" : 19958, "zip" : "10703", "loc" : [ -73.885163, 40.951763 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 18913, "zip" : "10001", "loc" : [ -73.996705, 40.74838 ] }
{ "state" : "NY", "city" : "WHITE PLAINS", "pop" : 17843, "zip" : "10605", "loc" : [ -73.755247, 41.014053 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 84143, "zip" : "10002", "loc" : [ -73.987681, 40.715231 ] }
{ "state" : "NY", "city" : "WHITE PLAINS", "pop" : 13436, "zip" : "10606", "loc" : [ -73.778097, 41.024714 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 12465, "zip" : "10017", "loc" : [ -73.970661, 40.75172 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 100027, "zip" : "10025", "loc" : [ -73.968312, 40.797466 ] }
{ "state" : "NY", "city" : "EAST WHITE PLAIN", "pop" : 8899, "zip" : "10604", "loc" : [ -73.750727, 41.043295 ] }
{ "state" : "NY", "city" : "HASTINGS ON HUDS", "pop" : 8546, "zip" : "10706", "loc" : [ -73.875912, 40.99071 ] }
{ "state" : "NY", "city" : "WHITE PLAINS", "pop" : 8397, "zip" : "10601", "loc" : [ -73.765231, 41.032955 ] }
{ "state" : "NY", "city" : "PUTNAM VALLEY", "pop" : 7453, "zip" : "10579", "loc" : [ -73.85024, 41.372815 ] }](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-82-320.jpg)



![{
"queryPlanner": {
"winningPlan": {
"stage": "SORT",
"sortPattern": {
"pop": -1
},
"inputStage": {
"stage": "FETCH",
"filter": {
"pop": {
"$gt": 100000
}
},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1
},
"indexName": "state_1_city_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-86-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "SORT",
"sortPattern": {
"pop": -1
},
"inputStage": {
"stage": "FETCH",
"filter": {
"pop": {
"$gt": 100000
}
},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1
},
"indexName": "state_1_city_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-87-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "SORT",
"sortPattern": {
"pop": -1
},
"inputStage": {
"stage": "FETCH",
"filter": {
"pop": {
"$gt": 100000
}
},
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1
},
"indexName": "state_1_city_1",
"isMultiKey": false,
"direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-88-320.jpg)
!["direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 4,
"totalKeysExamined": 40,
"totalDocsExamined": 40,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 4,
"works": 45,
"advanced": 2,
"needTime": 41,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-89-320.jpg)
!["direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 4,
"totalKeysExamined": 40,
"totalDocsExamined": 40,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 4,
"works": 45,
"advanced": 2,
"needTime": 41,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-90-320.jpg)
!["direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 4,
"totalKeysExamined": 40,
"totalDocsExamined": 40,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 4,
"works": 45,
"advanced": 2,
"needTime": 41,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
40 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-91-320.jpg)
!["direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 4,
"totalKeysExamined": 40,
"totalDocsExamined": 40,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 4,
"works": 45,
"advanced": 2,
"needTime": 41,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
40 documents scanned
40 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-92-320.jpg)
!["direction": "forward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK
"]"
]
}
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 4,
"totalKeysExamined": 40,
"totalDocsExamined": 40,
"executionStages": {
"stage": "SORT",
"nReturned": 2,
"executionTimeMillisEstimate": 4,
"works": 45,
"advanced": 2,
"needTime": 41,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"sortPattern": {
"pop": -1
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1, city:1})
Compound Index on two fields
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
40 documents scanned
40 index entries scanned
In-Memory Sort!](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-93-320.jpg)
![{ "state" : "NY", "city" : "NEW YORK", "pop" : 57385, "zip" : "10023", "loc" : [ -73.982652, 40.77638 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 51224, "zip" : "10003", "loc" : [ -73.989223, 40.731253 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 46560, "zip" : "10011", "loc" : [ -73.99963, 40.740225 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 36602, "zip" : "10019", "loc" : [ -73.985834, 40.765069 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 28453, "zip" : "10026", "loc" : [ -73.953069, 40.801942 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 26365, "zip" : "10012", "loc" : [ -73.998284, 40.72553 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 106564, "zip" : "10021", "loc" : [ -73.958805, 40.768476 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 18913, "zip" : "10001", "loc" : [ -73.996705, 40.74838 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 84143, "zip" : "10002", "loc" : [ -73.987681, 40.715231 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 12465, "zip" : "10017", "loc" : [ -73.970661, 40.75172 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 100027, "zip" : "10025", "loc" : [ -73.968312, 40.797466 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 4834, "zip" : "10018", "loc" : [ -73.992503, 40.754713 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 393, "zip" : "10020", "loc" : [ -73.982347, 40.759729 ] }
ABERDEENOH
NEW YORKNYNEW YORKNYW YORK NEW YORKNY NEWARKNY
NEW YORKNY NEWARKNY
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.createIndex({state:1, city:1})](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-94-320.jpg)

![{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1,
"pop": 1
},
"indexName": "state_1_city_1_pop_1",
"isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-96-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1,
"pop": 1
},
"indexName": "state_1_city_1_pop_1",
"isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-97-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1,
"pop": 1
},
"indexName": "state_1_city_1_pop_1",
"isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-98-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1,
"pop": 1
},
"indexName": "state_1_city_1_pop_1",
"isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}?](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-99-320.jpg)
![{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": {
"state": 1,
"city": 1,
"pop": 1
},
"indexName": "state_1_city_1_pop_1",
"isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}?](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-100-320.jpg)
!["indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 2,
"totalKeysExamined": 2,
"totalDocsExamined": 2,
"executionStages": {
"stage": "FETCH",
"nReturned": 2,
"executionTimeMillisEstimate": 1,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"docsExamined": 2,
"alreadyHasObj": 0,
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-101-320.jpg)
!["indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 2,
"totalKeysExamined": 2,
"totalDocsExamined": 2,
"executionStages": {
"stage": "FETCH",
"nReturned": 2,
"executionTimeMillisEstimate": 1,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"docsExamined": 2,
"alreadyHasObj": 0,
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-102-320.jpg)
!["indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 2,
"totalKeysExamined": 2,
"totalDocsExamined": 2,
"executionStages": {
"stage": "FETCH",
"nReturned": 2,
"executionTimeMillisEstimate": 1,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"docsExamined": 2,
"alreadyHasObj": 0,
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
2 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-103-320.jpg)
!["indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 2,
"totalKeysExamined": 2,
"totalDocsExamined": 2,
"executionStages": {
"stage": "FETCH",
"nReturned": 2,
"executionTimeMillisEstimate": 1,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"docsExamined": 2,
"alreadyHasObj": 0,
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
2 documents scanned
2 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-104-320.jpg)
!["indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 2,
"totalKeysExamined": 2,
"totalDocsExamined": 2,
"executionStages": {
"stage": "FETCH",
"nReturned": 2,
"executionTimeMillisEstimate": 1,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
"docsExamined": 2,
"alreadyHasObj": 0,
IXSCAN
FETCH
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1}).explain("executionStats")
db.zips.createIndex({state:1,city:1,pop:1})
Compound Index on three fields
plan root
{...} {...} {...} {...} {...} {...} {...} {...} {...}
2 documents returned
2 documents scanned
2 index entries scanned
Index used for Sorting!](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-105-320.jpg)
![NEW YORKNY 106564NEW YORKNY 100027NEW YORKNY 8414374643
NEW YORKNY 51224 NEWARKNY
ADENAOH
{ "state" : "NY", "city" : "NEW YORK", "pop" : 106564, "zip" : "10021", "loc" : [ -73.958805, 40.768476 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 100027, "zip" : "10025", "loc" : [ -73.968312, 40.797466 ] }
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.createIndex({state:1,city:1,pop:1})
"direction": "backward",
"indexBounds": {
“state": "["NY", "NY"]",
"city":"["NEW YORK", "NEW YORK"]",
"pop":"[inf.0, 100000.0)"](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-106-320.jpg)
![NEW YORKNY 106564NEW YORKNY 100027NEW YORKNY 8414374643
NEW YORKNY 51224 NEWARKNY
ADENAOH
{ "state" : "NY", "city" : "NEW YORK", "pop" : 106564, "zip" : "10021", "loc" : [ -73.958805, 40.768476 ] }
{ "state" : "NY", "city" : "NEW YORK", "pop" : 100027, "zip" : "10025", "loc" : [ -73.968312, 40.797466 ] }
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.createIndex({state:1,city:1,pop:1})
"direction": "backward",
"indexBounds": {
“state": "["NY", "NY"]",
"city":"["NEW YORK", "NEW YORK"]",
"pop":"[inf.0, 100000.0)"](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-107-320.jpg)



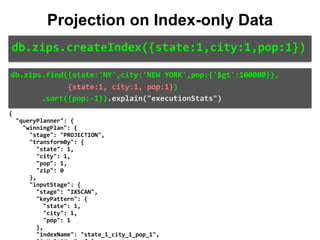

!["isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 0,
"totalKeysExamined": 2,
"totalDocsExamined": 0,
"executionStages": {
"stage": "PROJECTION",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}},
{state:1, city:1, pop:1})
.sort({pop:-1}).explain("executionStats")
Projection on Index-only Data
db.zips.createIndex({state:1,city:1,pop:1})
IXSCAN
PROJECTION
plan root](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-113-320.jpg)
!["isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 0,
"totalKeysExamined": 2,
"totalDocsExamined": 0,
"executionStages": {
"stage": "PROJECTION",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}},
{state:1, city:1, pop:1})
.sort({pop:-1}).explain("executionStats")
Projection on Index-only Data
db.zips.createIndex({state:1,city:1,pop:1})
IXSCAN
PROJECTION
plan root 2 documents returned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-114-320.jpg)
!["isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 0,
"totalKeysExamined": 2,
"totalDocsExamined": 0,
"executionStages": {
"stage": "PROJECTION",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}},
{state:1, city:1, pop:1})
.sort({pop:-1}).explain("executionStats")
Projection on Index-only Data
db.zips.createIndex({state:1,city:1,pop:1})
IXSCAN
PROJECTION
plan root 2 documents returned
2 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-115-320.jpg)
!["isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 0,
"totalKeysExamined": 2,
"totalDocsExamined": 0,
"executionStages": {
"stage": "PROJECTION",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}},
{state:1, city:1, pop:1})
.sort({pop:-1}).explain("executionStats")
Projection on Index-only Data
db.zips.createIndex({state:1,city:1,pop:1})
IXSCAN
PROJECTION
plan root 2 documents returned
0 documents scanned
2 index entries scanned](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-116-320.jpg)
!["isMultiKey": false,
"direction": "backward",
"indexBounds": {
"state": [
"["NY", "NY"]"
],
"city": [
"["NEW YORK", "NEW YORK"]"
],
"pop": [
"[inf.0, 100000.0)"
]
}
}
}
},
"executionStats": {
"executionSuccess": true,
"nReturned": 2,
"executionTimeMillis": 0,
"totalKeysExamined": 2,
"totalDocsExamined": 0,
"executionStages": {
"stage": "PROJECTION",
"nReturned": 2,
"executionTimeMillisEstimate": 0,
"works": 3,
"advanced": 2,
"needTime": 0,
"needFetch": 0,
"saveState": 0,
"restoreState": 0,
"isEOF": 1,
"invalidates": 0,
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}},
{state:1, city:1, pop:1})
.sort({pop:-1}).explain("executionStats")
Projection on Index-only Data
db.zips.createIndex({state:1,city:1,pop:1})
IXSCAN
PROJECTION
plan root 2 documents returned
0 documents scanned
2 index entries scanned
"Covered Query "](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-117-320.jpg)
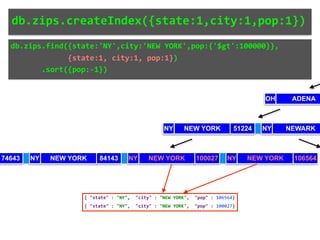
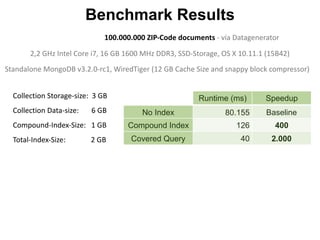



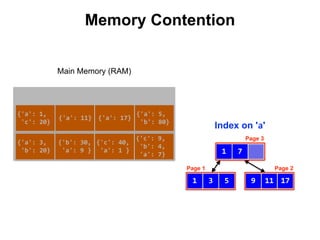
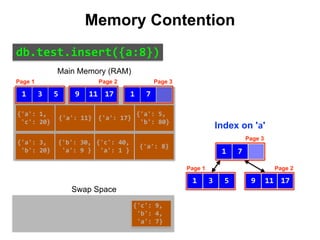
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 11}
{'a': 5,
'b': 80}
{'c': 40,
'a': 1 }
{'a': 17}
{'a': 8}
{'b': 30,
'a': 9 }
{'c': 9,
'b': 4,
'a': 7}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
17
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
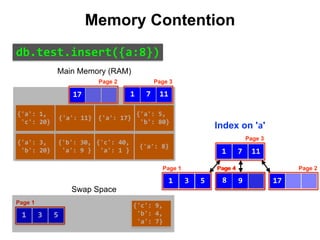
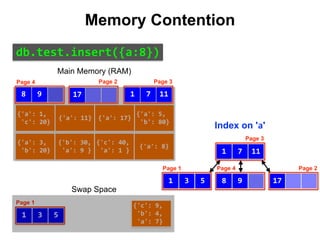
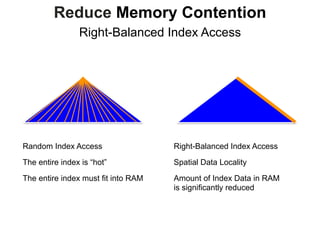
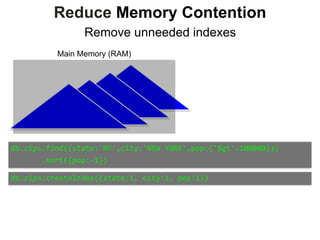
Reduce Memory Contention
Right-Balanced Index Access
db.test.insert([{a:18},{a:19}]) {'a': 18}
{'a': 19}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-136-320.jpg)
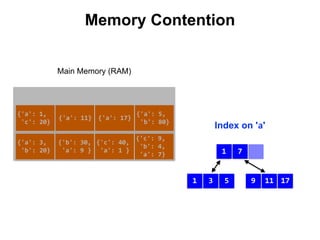
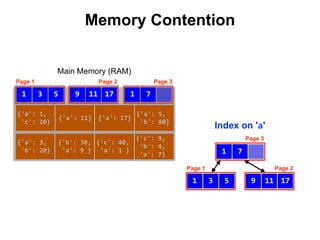
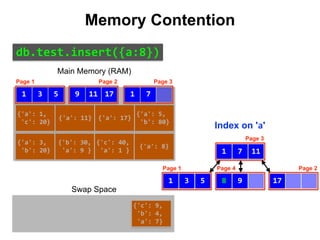
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 11}
{'a': 5,
'b': 80}
{'a': 17}
{'a': 8}
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
Index on 'a'
Main Memory (RAM)
3 51
Page 1
17
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
db.test.insert([{a:18},{a:19}]) {'a': 18}
{'a': 19}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-137-320.jpg)
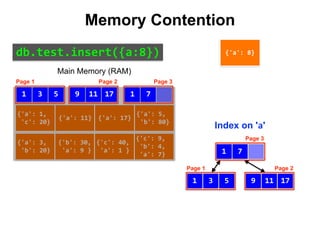
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 11}
{'a': 5,
'b': 80}
{'a': 17}
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
Index on 'a'
Main Memory (RAM)
3 51
Page 1
17
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
db.test.insert([{a:18},{a:19}])](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-138-320.jpg)
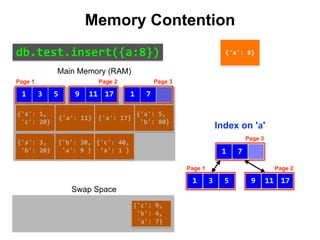
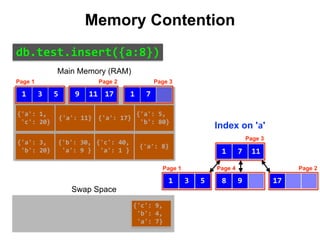
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 11}
{'a': 5,
'b': 80}
{'a': 17}
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
Index on 'a'
Main Memory (RAM)
3 51
Page 1
17
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18
18
db.test.insert([{a:18},{a:19}])](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-139-320.jpg)
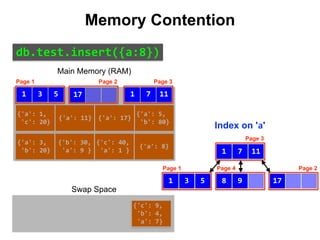
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 11}
{'a': 5,
'b': 80}
{'a': 17}
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
Index on 'a'
Main Memory (RAM)
3 51
Page 1
17
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18
18
19
19
db.test.insert([{a:18},{a:19}])](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-140-320.jpg)
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 11}
{'a': 5,
'b': 80}
{'a': 17}
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
Index on 'a'
Main Memory (RAM)
3 51
Page 1
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18 19
17 18 19
db.test.insert([{a:20},{a:21},{a:22}])
{'a': 22}
{'a': 21}
{'a': 20}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-141-320.jpg)
![{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}
{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Reduce Memory Contention
Right-Balanced Index Access
18 19
17 18 19
db.test.insert([{a:20},{a:21},{a:22}])
{'a': 22}
{'a': 21}
{'a': 20}
Swap Space](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-142-320.jpg)
![{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}
{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
11
Page 2
1 7
Page 3
Page 2
1 7
Page 3
98
Page 4
111798
Page 4
3 51
Page 1
Reduce Memory Contention
Right-Balanced Index Access
18 19
17 18 19
db.test.insert([{a:20},{a:21},{a:22}])
Swap Space](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-143-320.jpg)
![{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}
{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
db.test.insert([{a:20},{a:21},{a:22}])
98
Page 4](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-144-320.jpg)
![{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}
{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
98
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
Page 5
db.test.insert([{a:20},{a:21},{a:22}])](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-145-320.jpg)
![{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}
{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
98
Page 4
3 51
Page 1
Swap Space
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
Page 5
db.test.insert([{a:20},{a:21},{a:22}])](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-146-320.jpg)
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
Page 5
20
20
db.test.insert([{a:20},{a:21},{a:22}])
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}98
Page 4
3 51
Page 1
Swap Space](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-147-320.jpg)
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
Page 5
20 21
20 21
db.test.insert([{a:20},{a:21},{a:22}])
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}98
Page 4
3 51
Page 1
Swap Space](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-148-320.jpg)
![{'a': 3,
'b': 20}
{'a': 1,
'c': 20}
{'a': 8}{'a': 18} {'a': 19}
{'a': 22}{'a': 21}{'a': 20}
Index on 'a'
Main Memory (RAM)
3 51
Page 1
111 7
Page 3
Page 2
1 7
Page 3
98
Page 4
1117
Reduce Memory Contention
Right-Balanced Index Access
18 19
Page 2
Page 5
17 18 19
Page 5
20 21 22
20 21 22
db.test.insert([{a:20},{a:21},{a:22}])
{'c': 9,
'b': 4,
'a': 7}
{'c': 40,
'a': 1 }
{'b': 30,
'a': 9 }
{'a': 5,
'b': 80}{'a': 17}{'a': 11}98
Page 4
3 51
Page 1
Swap Space](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-149-320.jpg)
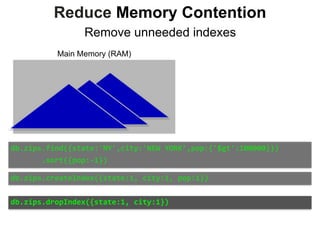
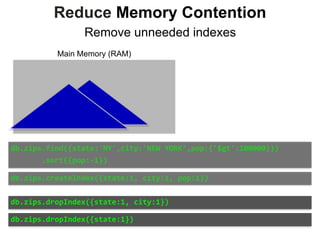
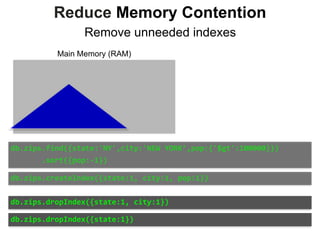
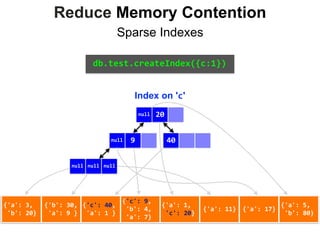
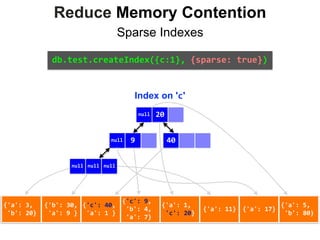
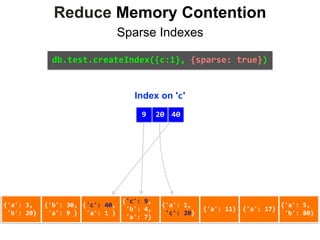
![Reduce Memory Contention
Sparse Indexes
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
Index on 'c'
{'a': 3,
'b': 20}
{'b': 30,
'a': 9 }
{'c': 40,
'a': 1 }
{'c': 9,
'b': 4,
'a': 7}
{'a': 1,
'c': 20}
{'a': 11} {'a': 17}
{'a': 5,
'b': 80}
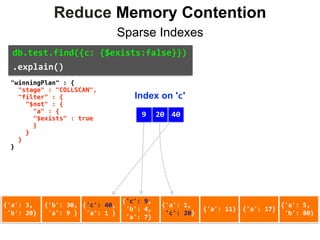
db.test.find({c: {$exists:false}})
.explain()
null 20
409null
null null null
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"indexBounds" : {
"c" : [
"[null, null]"
]
}
}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-156-320.jpg)









![db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
])
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-170-320.jpg)
![db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
])
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-171-320.jpg)
![db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
])
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-172-320.jpg)
![db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-173-320.jpg)
![{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
{
"waitedMS" : NumberLong(0),
"stages" : [
{
"$cursor" : {...}
},
{
"$group": {...}
},
{
"$sort" : {..."limit"...}
}
]
}
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-174-320.jpg)
![{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
Cursor
{
"waitedMS" : NumberLong(0),
"stages" : [
{
"$cursor" : {...}
},
{
"$group": {...}
},
{
"$sort" : {..."limit"...}
}
]
}
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-175-320.jpg)
![{
"waitedMS" : NumberLong(0),
"stages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-176-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-177-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-178-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-179-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
IXSCAN
PROJECTION
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-180-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
IXSCAN
PROJECTION
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Projection Optimization
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-181-320.jpg)
![aitedMS" : NumberLong(0),
tages" : [
{
"$cursor" : {
"fields" : {
"city" : 1,
"zip" : 0
},
"queryPlanner" : {
"winningPlan" : {
"stage" : "PROJECTION",
"transformBy" : {
"city" : 1,
"zip" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"indexName" : "state_1_city_1_pop_1",
"indexBounds" : {
"state" : [
"["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
IXSCAN
PROJECTION
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Projection Optimization
"Covered Query "
Aggregation Query: Three cities in CA with most zip codes](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-182-320.jpg)
!["["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
}
}
}
}
}
},
{
"$group" : {
"zip" : "$city",
"zipCodes" : {
"$sum" : {
"$const" : 1
}
}
}
},
{
"$sort" : {
"sortKey" : {
"zipCodes" : -1
},
"limit" : NumberLong(3)
}
}
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
IXSCAN
PROJECTION
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes
Projection Optimization
"Covered Query "](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-183-320.jpg)
!["["CA", "CA"]"
],
"city" : [
"[MinKey, MaxKey]"
],
"pop" : [
"[MinKey, MaxKey]"
]
}
}
}
}
}
},
{
"$group" : {
"zip" : "$city",
"zipCodes" : {
"$sum" : {
"$const" : 1
}
}
}
},
{
"$sort" : {
"sortKey" : {
"zipCodes" : -1
},
"limit" : NumberLong(3)
}
}
]
{ "zip" : "LOS ANGELES",
"zipCodes" : 56 }
{ "zip" : "SAN DIEGO",
"zipCodes" : 34 }
{ "zip" : "SAN JOSE",
"zipCodes" : 29 }
Group
Limit
Sort
IXSCAN
PROJECTION
Cursor
db.zipcodes.aggregate([
{ $match: { state : "CA" } },
{ $group: { _id: '$city', zipCodes: { $sum: 1 } } },
{ $sort: { zipCodes: -1 } },
{ $limit: 3 }
],{explain:true})
Aggregation Query: Three cities in CA with most zip codes
Projection Optimization
"Covered Query "
$sort + $limit Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-184-320.jpg)
![db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
])
Aggregation Pipeline and Sharded Collections](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-185-320.jpg)
![db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
])
Config
ServerConfig
ServerConfig
Server
Router
(mongos)
{...} {...} {...} {...} {...} {...} {...} {...}
shard1 shard2
Aggregation Pipeline and Sharded Collections](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-186-320.jpg)
![db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
])
Config
ServerConfig
ServerConfig
Server
Router
(mongos)
{...} {...} {...} {...} {...} {...} {...} {...}
shard1 shard2
Aggregation Pipeline and Sharded Collections
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-187-320.jpg)
![shard key: { "state" : 1 }
chunks: shard1 2, shard2 2
{ "state" : { "$minKey" : 1 } } -->>
{ "state" : "CT" } on : shard1
{ "state" : "CT" } -->>
{ "state" : "ME" } on : shard1
{ "state" : "ME" } -->>
{ "state" : "NJ" } on : shard2
{ "state" : "NJ" } -->>
{ "state" : { "$maxKey" : 1 } }
on : shard2
sh.status()
Config
ServerConfig
ServerConfig
Server
Router
(mongos)
{...} {...} {...} {...} {...} {...} {...} {...}
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
shard1 shard2
Aggregation Pipeline and Sharded Collections
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
])
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-188-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-189-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-190-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-191-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-192-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-193-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
< 2.6: mongos
< 3.2: primary shard
3.2: any shard](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-194-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {...}
}
],
"mergerPart": [
{
"$group": {...}
},
{
"$sort": {..."limit"...}
}
]
},
"shards": {
"shard1": {...},
"shard2": {...}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-195-320.jpg)
![{"splitPipeline": {
"shardsPart": [
{
"$group": {
"zip": {
"state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
],
"mergerPart": [
{
"$group": {
"zip": "$$ROOT._id",
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-196-320.jpg)
!["$group": {
"zip": {
"state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
],
"mergerPart": [
{
"$group": {
"zip": "$$ROOT._id",
"zipCodes": {
"$sum": "$$ROOT.zipCodes"
},
"$doingMerge": true
}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-197-320.jpg)
!["$group": {
"zip": {
"state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
],
"mergerPart": [
{
"$group": {
"zip": "$$ROOT._id",
"zipCodes": {
"$sum": "$$ROOT.zipCodes"
},
"$doingMerge": true
}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
$sort + $limit
Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-198-320.jpg)
![}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
"shards": {
"shard1": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
}
}
}
},
{
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
$sort + $limit
Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-199-320.jpg)
![}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
"shards": {
"shard1": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
}
}
}
},
{
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
$sort + $limit
Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-200-320.jpg)
![}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
"shards": {
"shard1": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
}
}
}
},
{
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
Cursor
COLLSCAN
{...} {...} {...} {...} {...} {...} {...} {...}
Cursor
COLLSCAN
$sort + $limit
Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-201-320.jpg)
![}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
},
"shards": {
"shard1": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
}
}
}
},
{
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
Cursor
COLLSCAN
{...} {...} {...} {...} {...} {...} {...} {...}
Cursor
COLLSCAN
Projection
Optimization
$sort + $limit
Coalescence](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-202-320.jpg)
!["shard1": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
}
}
}
},
{
"$group": {
"zip": {
"state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
]
},
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
Cursor
COLLSCAN
{...} {...} {...} {...} {...} {...} {...} {...}
Cursor
COLLSCAN
$sort + $limit
Coalescence
Projection
Optimization](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-203-320.jpg)
!["state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
]
},
"shard2": {
"stages": [
{
"$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
},
}
}
},
{
"$group": {
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
Cursor
COLLSCAN
{...} {...} {...} {...} {...} {...} {...} {...}
Cursor
COLLSCAN
$sort + $limit
Coalescence
Projection
Optimization](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-204-320.jpg)
!["$cursor": {
"fields": {
"city": 1,
"state": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"inputStage": {
"stage": "COLLSCAN",
}
},
}
}
},
{
"$group": {
"zip": {
"state": "$state",
"city": "$city"
},
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
}
]
}
}
}
db.zipcodes.aggregate([
{ $group:{_id:{state:'$state', city:'$city'}, zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{"zip": {"state": "TX", "city": "HOUSTON"},
"zipCodes" : 93 }
{"zip": {"state": "CA", "city": "LOS ANGELES"},
"zipCodes" : 56 }
{"zip": {"state": "PA", "city": "PHILADELPHIA"},
"zipCodes" : 48 }
shard1 shard2
Aggregation Pipeline and Sharded Collections
Group Group
Limit
Sort
Group
Cursor
COLLSCAN
{...} {...} {...} {...} {...} {...} {...} {...}
Cursor
COLLSCAN
$sort + $limit
Coalescence
Projection
Optimization](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-205-320.jpg)
![db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
])
shard1 shard2
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-206-320.jpg)
![db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
shard1
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
shard2
shard1 shard2
Sharded Cluster - Targeted Query Routing](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-207-320.jpg)
![db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-208-320.jpg)
![{
"splitPipeline": null,
"shards": {
"shard1": {
"stages": [
{
"$cursor": {
"query": {
"state": "CA"
},
"fields": {
"city": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"stage": "PROJECTION",
"transformBy": {
"city": 1,
db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-209-320.jpg)
![eline": null,
{
": {
es": [
$cursor": {
"query": {
"state": "CA"
},
"fields": {
"city": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"stage": "PROJECTION",
"transformBy": {
"city": 1,
"zip": 0
},
"inputStage": {
"stage": "IXSCAN",
"indexName": "state_1_city_1_pop_1",
"indexBounds": {
"state": [
"["CA", "CA"]"
],
"city": [
"[MinKey, MaxKey]"
],
"pop": [
"[MinKey, MaxKey]"
db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-210-320.jpg)
![eline": null,
{
": {
es": [
$cursor": {
"query": {
"state": "CA"
},
"fields": {
"city": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"stage": "PROJECTION",
"transformBy": {
"city": 1,
"zip": 0
},
"inputStage": {
"stage": "IXSCAN",
"indexName": "state_1_city_1_pop_1",
"indexBounds": {
"state": [
"["CA", "CA"]"
],
"city": [
"[MinKey, MaxKey]"
],
"pop": [
"[MinKey, MaxKey]"
db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-211-320.jpg)
![eline": null,
{
": {
es": [
$cursor": {
"query": {
"state": "CA"
},
"fields": {
"city": 1,
"zip": 0
},
"queryPlanner": {
"winningPlan": {
"stage": "PROJECTION",
"transformBy": {
"city": 1,
"zip": 0
},
"inputStage": {
"stage": "IXSCAN",
"indexName": "state_1_city_1_pop_1",
"indexBounds": {
"state": [
"["CA", "CA"]"
],
"city": [
"[MinKey, MaxKey]"
],
"pop": [
"[MinKey, MaxKey]"
db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor
IXSCAN
PROJECTION
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-212-320.jpg)
!["["CA", "CA"]"
],
"city": [
"[MinKey, MaxKey]"
],
"pop": [
"[MinKey, MaxKey]"
]
}
}
}
}
}
},
{
"$group": {
"zip": "$city",
"zipCodes": {
"$sum": {
"$const": 1
}
}
}
},
{
"$sort": {
"sortKey": {
"zipCodes": -1
},
"limit": NumberLong(3)
}
}
]
db.zipcodes.aggregate([
{ $match : { state : "CA" } },
{ $group:{_id:'$city', zipCodes: { $sum: 1 }}},
{ $sort : { zipCodes:-1} },
{ $limit : 3 }
], {explain:true})
{ "zip" : "LOS ANGELES", "zipCodes" : 56 }
{ "zip" : "SAN DIEGO", "zipCodes" : 34 }
{ "zip" : "SAN JOSE", "zipCodes" : 29 }
Sharded Cluster - Targeted Query Routing
shard1 shard2
Group
Limit
Sort
Cursor
IXSCAN
PROJECTION
"ME" -->>
"$maxKey"
"$minKey" -->>
"ME"](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-213-320.jpg)


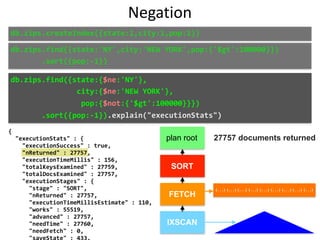




!["alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 27757,
"executionTimeMillisEstimate" : 40,
"works" : 27759,
"advanced" : 27757,
"needTime" : 2,
"needFetch" : 0,
"saveState" : 433,
"restoreState" : 433,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"state" : 1,
"city" : 1,
"pop" : 1
},
"indexName" : "state_1_city_1_pop_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"state" : [
"[MinKey, "NY")",
"("NY", MaxKey]"
],
"city" : [
"[MinKey, "NEW YORK")",
"("NEW YORK", MaxKey]"
],
"pop" : [
"[MinKey, 100000.0]",
"(inf.0, MaxKey]"
]
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.find({state:{$ne:'NY'},
city:{$ne:'NEW YORK'},
pop:{$not:{'$gt':100000}}})
.sort({pop:-1}).explain("executionStats")
27757 documents returned
27759 documents scanned
27757 index entries scanned
In-Memory Sort!
db.zips.createIndex({state:1,city:1,pop:1})
Negation
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-221-320.jpg)
!["alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 27757,
"executionTimeMillisEstimate" : 40,
"works" : 27759,
"advanced" : 27757,
"needTime" : 2,
"needFetch" : 0,
"saveState" : 433,
"restoreState" : 433,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"state" : 1,
"city" : 1,
"pop" : 1
},
"indexName" : "state_1_city_1_pop_1",
"isMultiKey" : false,
"direction" : "forward",
"indexBounds" : {
"state" : [
"[MinKey, "NY")",
"("NY", MaxKey]"
],
"city" : [
"[MinKey, "NEW YORK")",
"("NEW YORK", MaxKey]"
],
"pop" : [
"[MinKey, 100000.0]",
"(inf.0, MaxKey]"
]
db.zips.find({state:'NY',city:'NEW YORK',pop:{'$gt':100000}})
.sort({pop:-1})
db.zips.find({state:{$ne:'NY'},
city:{$ne:'NEW YORK'},
pop:{$not:{'$gt':100000}}})
.sort({pop:-1}).explain("executionStats")
27757 documents returned
27759 documents scanned
27757 index entries scanned
In-Memory Sort!
db.zips.createIndex({state:1,city:1,pop:1})
Negation
plan root
SORT
FETCH
IXSCAN
{...} {...} {...} {...} {...} {...} {...} {...} {...}](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-222-320.jpg)

![mongod Log Files
Sun Jun 29 06:35:37.646 [conn2]
query test.docs query:
{ parent.company: "22794",
parent.employeeId: "83881" }
ntoreturn:1 ntoskip:0 nscanned:
806381 keyUpdates:0 numYields: 5
locks(micros) r:2145254
nreturned:0 reslen:20 1156ms
date and time thread
operation
namespace
n…
counters
lock
times
duration
number of
yields](https://image.slidesharecdn.com/indexingandperformancetuning-151105193914-lva1-app6892/85/MongoDB-Days-UK-Indexing-and-Performance-Tuning-225-320.jpg)








The document emphasizes the importance of indexes as a major factor for performance tuning in MongoDB, detailing how different query methods affect document scanning. It discusses various operations such as index scans and full collection scans, illustrating the performance implications of using an index on a specified field. The document also touches on time complexity for searching through data structures like lists and binary search trees.



















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































