Downloaded 18 times








![Challenges
• com.mongodb.MongoCommandException: Command
failed with error 112 (WriteConflict): 'WriteConflict' on server
exethanter.local:27017. The full response is { "errorLabels" :
["TransientTransactionError"], "operationTime" : {
"$timestamp" : { "t" : 1537701066, "i" : 3 } }, "ok" : 0.0, "errmsg"
: "WriteConflict", "code" : 112, "codeName" : "WriteConflict",
"$clusterTime" : { "clusterTime" : { "$timestamp" : { "t" :
1537701066, "i" : 3 } }, "signature" : { "hash" : { "$binary" :
"AAAAAAAAAAAAAAAAAAAAAAAAAAA=", "$type" : "00" },
"keyId" : { "$numberLong" : "0" } } } }
8](https://image.slidesharecdn.com/flowfest18-mongodb-181206102439/85/MongoDB-and-Machine-Learning-with-Flowable-8-320.jpg)


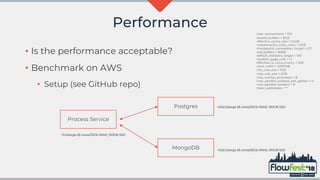
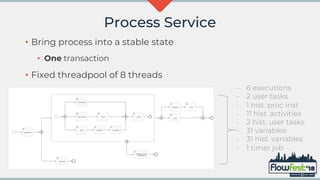
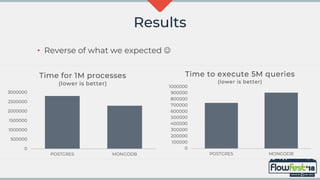






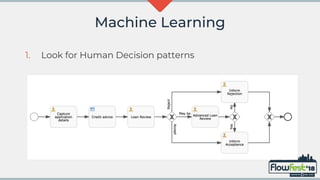
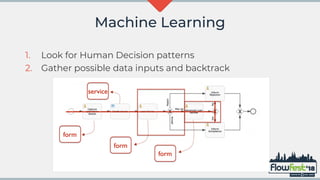

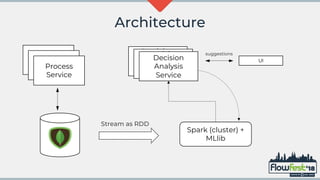
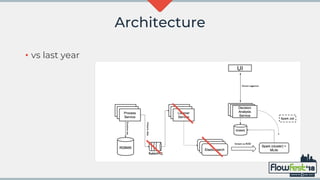



The document discusses the integration of MongoDB with Flowable, emphasizing transaction support and challenges in adopting a NoSQL approach compared to traditional relational databases. It highlights performance considerations and potential machine learning applications that leverage the data models in Flowable and MongoDB. The future of MongoDB transactions and their suitability for big data scenarios, particularly in processing decision patterns and optimizations, is also examined.




















































































