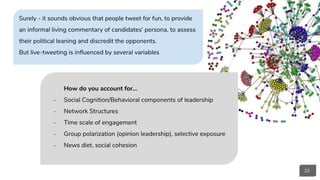
Download as PDF, PPTX





















![37 3
7
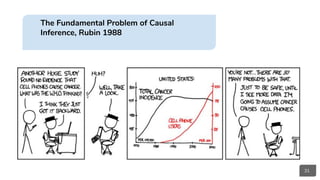
“A causal structure entails a probability model, but it
contains additional information not contained in the
latter. Causal reasoning [...] denotes the process of
drawing conclusions from a causal model, similar to
the way probability theory allows us to reason about
the outcomes of random experiments. However, since
causal models contain more information than
probabilistic ones do, causal reasoning is more
powerful than probabilistic reasoning, because causal
reasoning allows us to analyze the effect of
interventions or distribution changes.”
3737](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-37-320.jpg)


![Predictive Analysis: Causal Inference
What caused A to agree/disagree with B? Can we build a model to forecast
and retrieve rhetorical behaviors, causal reasoning, and alignments?
40
Descriptive Analysis: LIWC + NLP
Lexical Analysis:
● Linguistic Inquiry Word
Count [LIWC]
● NLTK: Words Count &
Frequency
Semantic Analysis:
● Comparison between text
corpora:
○ Softcossim
○ KL divergence
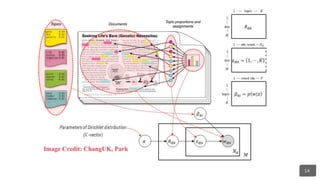
● Topic Modeling:
○ Latent Semantic
Analysis
○ Latent Dirichlet
Allocation
● Sentiment Analysis
● Word Embeddings:
○ Word2Vec
○ GloVe
○ FastText
● Sentence Embeddings:
○ FastText
○ Doc2Vec
○ Sent2Vec
4
0
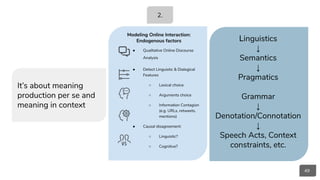
Causal Reasoning:
● Structural Equation Models
● Chain Graphs
○ Direct Acyclic Graphs
(DAGs)
Natural Language Understanding:
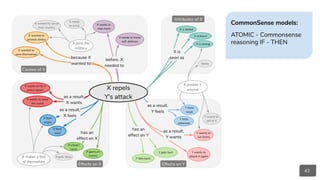
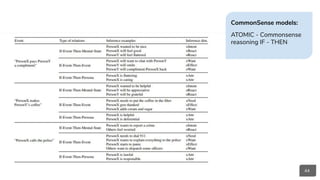
● CommonSense Inference
(semantic entailment):
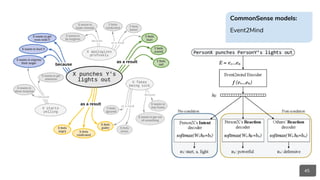
○ Event2Mind
○ A TOMIC
○ SWAG
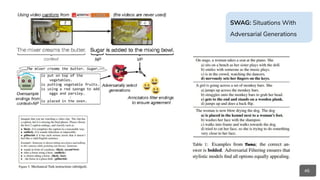
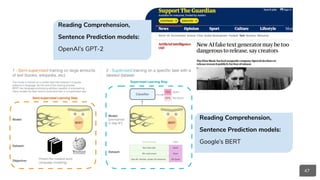
● Reading Comprehension,
Sentence Prediction:
○ Google’s BERT
○ OpenAI’s GPT-2
○ ELMo
4040](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-40-320.jpg)




![53 5
3
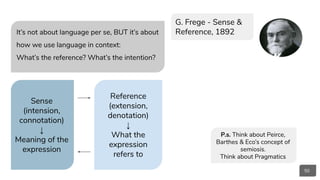
P. Grice - Maxims,
1975
● Quantity: In answer to "Tell me about him!":
He has a nice personality. [≠ informative]
● Quality: In response to something stupid someone did:
That was brilliant! [≠ true]
● Relation: In response to "Can I go out and play?":
Did you finish your homework? [≠ pertinent]
● Manner: A wedding ring should be tight, after all, it's purpose is
to limit your circulation. [≠ unambiguous]
How do we assess sarcasm,
irony and other weird
psychopathic manipulations ?
5353](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-53-320.jpg)




![65
Descriptive Analysis: LIWC + NLP
Lexical Analysis:
● Linguistic Inquiry Word
Count [LIWC]
● NLTK: Words Count &
Frequency
Semantic Analysis:
● Comparison between text
corpora:
○ Softcossim
○ KL divergence
● Topic Modeling:
○ Latent Semantic
Analysis
○ Latent Dirichlet
Allocation
● Sentiment Analysis
● Word Embeddings:
○ Word2Vec
○ GloVe
○ FastText
● Sentence Embeddings:
○ FastText
○ Doc2Vec
○ Sent2Vec
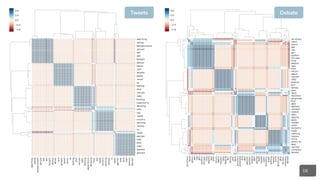
Predictive Analysis: Causal Inference
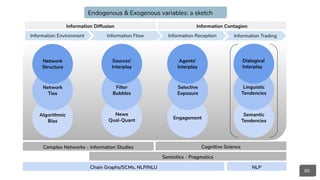
Network Interferences: Information Diffusion & Contagion
Causal Reasoning:
● Structural Equation Models
● Chain Graphs
○ Direct Acyclic Graphs
(DAGs)
Natural Language Understanding:
● CommonSense Inference
(semantic entailment):
○ Event2Mind
○ A TOMIC
○ SWAG
● Reading Comprehension,
Sentence Prediction:
○ Google’s BERT
○ OpenAI’s GPT-2
○ ELMo
Pragmatic Distortion:
○ Linguistic Ambiguity
(e.g. lexical
constraints)
○ Semantic Ambiguity
(e.g. speech acts,
sense and reference,
Implicatures, etc.))
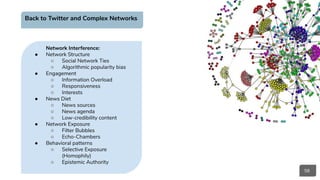
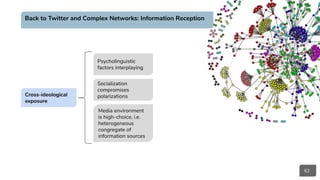
Network Interference:
● Network Structure
○ Social Network Ties
● Engagement
○ Attention
○ Responsiveness
○ Interests
● News Diet
○ News sources
○ News agenda
● Network Exposure
○ Filter Bubbles
○ Echo-Chambers
● Behavioral patterns
○ Selective Exposure
(Homophily)
○ Epistemic Authority
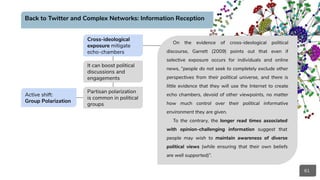
What caused A to agree/disagree with B? Can we build a model to forecast
and retrieve rhetorical behaviors, causal reasoning, and alignments?
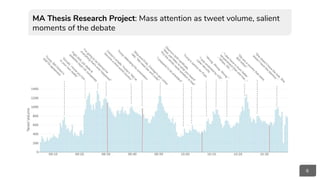
What caused A to agree/disagree with B? Can we build a model to forecast and retrieve rhetorical behaviors, causal
reasoning, and alignments quantifying all the network interferences that do shape information diffusion and contagion?
6
5
6565](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-65-320.jpg)



![71 7
1
● Frege, G., 1892. On sense and meaning. Translations from the philosophical writings of Gottlob Frege, 3, pp.56-78.
● Lenci, A., 2008. Distributional semantics in linguistic and cognitive research. Italian journal of linguistics, 20(1), pp.1-31.
● Erk, K., 2016. What do you know about an alligator when you know the company it keeps?. Semantics and Pragmatics, 9, pp.17-1.
● Nannini, L., 2019. Analyzing semantic contagion of mass entrainment in tweets produced during 2016 U.S. first presidential debate. [online]
Google Docs. Available at: https://docs.google.com/document/d/15iUWQeGP_y3h0zupZ1xxdMPN66eLau4xWgRS13lCQIc/edit?usp=sharing
● Pennebaker, J.W., Boyd, R.L., Jordan, K. and Blackburn, K., 2015. The development and psychometric properties of LIWC2015.
● Faasse, K., Chatman, C.J. and Martin, L.R., 2016. A comparison of language use in pro-and anti-vaccination comments in response to a high
profile Facebook post. Vaccine, 34(47), pp.5808-5814.
● Mitra, T., Counts, S. and Pennebaker, J.W., 2016, March. Understanding anti-vaccination attitudes in social media. In Tenth International AAAI
Conference on Web and Social Media.
● Bojanowski, P., Grave, E., Joulin, A. and Mikolov, T., 2017. Enriching word vectors with subword information. Transactions of the Association for
Computational Linguistics, 5, pp.135-146.
● Darling, W.M., 2011, December. A theoretical and practical implementation tutorial on topic modeling and gibbs sampling. In Proceedings of the
49th annual meeting of the association for computational linguistics: Human language technologies (pp. 642-647).
● Ramage, D., Dumais, S. and Liebling, D., 2010, May. Characterizing microblogs with topic models. In Fourth international AAAI conference on
weblogs and social media.
● Ritter, A., Cherry, C. and Dolan, B., 2010, June. Unsupervised modeling of twitter conversations. In Human Language Technologies: The 2010
Annual Conference of the North American Chapter of the Association for Computational Linguistics (pp. 172-180). Association for Computational
Linguistics.
● Coppersmith, G., Dredze, M. and Harman, C., 2014, June. Quantifying mental health signals in Twitter. In Proceedings of the workshop on
computational linguistics and clinical psychology: From linguistic signal to clinical reality (pp. 51-60).
● Bowman, S.R., Angeli, G., Potts, C. and Manning, C.D., 2015. A large annotated corpus for learning natural language inference. arXiv preprint
arXiv:1508.05326.
● Lopez-Paz, D., Muandet, K., Schölkopf, B. and Tolstikhin, I., 2015, June. Towards a learning theory of cause-effect inference. In International
Conference on Machine Learning (pp. 1452-1461).
● Ogburn, E.L., Shpitser, I., and Lee, Y., 2018. Causal inference, social networks, and chain graphs. arXiv preprint arXiv:1812.04990.
7171](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-71-320.jpg)
![72 7
2
● Bhattacharya, R., Malinsky, D. and Shpitser, I., 2019. Causal Inference Under Interference And Network Uncertainty. arXiv preprint arXiv:1907.00221.
● Gray, V. 2019.. How a 16-year-old got us to care about climate change. [online] Pulsar Platform. Available at:
https://www.pulsarplatform.com/blog/2019/how-a-16-year-old-got-us-to-care-about-climate-change/?fbclid=IwAR2AMbSIzPuFD5_6mqSxMPboNk
7bWRu_8YLRLsdemBGa0yQ7DvWFyXw4VUc [Accessed 27 Sep. 2019].
● Kang, G.J., Ewing-Nelson, S.R., Mackey, L., Schlitt, J.T., Marathe, A., Abbas, K.M. and Swarup, S., 2017. Semantic network analysis of vaccine
sentiment in online social media. Vaccine, 35(29), pp.3621-3638.
● Pinto, J. C. L., & Chahed, T. 2014. Modeling Multi-topic Information Diffusion in Social Networks Using Latent Dirichlet Allocation and Hawkes
Processes. 2014 Tenth International Conference on Signal-Image Technology and Internet-Based Systems, 339–346
● Romero, D. M., Meeder, B., & Kleinberg, J. 2011. Differences in the Mechanics of Information Diffusion Across Topics: Idioms, Political Hashtags,
and Complex Contagion on Twitter. Proceedings of the 20th International Conference on World Wide Web, 695–704. New York, NY, USA: ACM.
● Yang, J., & Leskovec, J. 2010. Modeling Information Diffusion in Implicit Networks. 2010 IEEE International Conference on Data Mining, 599–608.
● Kafeza, E., Kanavos, A., Makris, C., & Vikatos, P. 2014. Predicting Information Diffusion Patterns in Twitter. Artificial Intelligence Applications and
Innovations, 79–89. Springer Berlin Heidelberg.
● Aral, M. (n.d.). Sundararajan (2009) Aral, S., Muchnik, L., & Sundararajan, A.(2009). Distinguishing influence-based contagion from
homophily-driven diffusion in dynamic networks. Proceedings of the National Academy of Sciences, 106(51), 21544–21549.
● Yardi, S., & Boyd, D. (2010). Dynamic Debates: An Analysis of Group Polarization Over Time on Twitter. Bulletin of Science, Technology & Society,
30(5), 316–327.
● Kossinets, G., & Watts, D. J. (2009). Origins of Homophily in an Evolving Social Network. The American Journal of Sociology, 115(2), 405–450.
● Wojcieszak, M. E., & Mutz, D. C. (2009). Online Groups and Political Discourse: Do Online Discussion Spaces Facilitate Exposure to Political
Disagreement? The Journal of Communication, 59(1), 40–56.
● Centola, D., & Macy, M. (2007). Complex Contagions and the Weakness of Long Ties. The American Journal of Sociology, 113(3), 702–734.
● Speriosu, M., Sudan, N., Upadhyay, S., & Baldridge, J. (2011). Twitter Polarity Classification with Label Propagation over Lexical Links and the
Follower Graph. Proceedings of the First Workshop on Unsupervised Learning in NLP, 53–63. Stroudsburg, PA, USA: Association for
Computational Linguistics.
● Sunstein, C. R. (2002). The law of group polarization. The Journal of Political Philosophy.
● Weeks, B.E., Ksiazek, T.B. and Holbert, R.L., 2016. Partisan enclaves or shared media experiences? A network approach to understanding
citizens’ political news environments. Journal of Broadcasting & Electronic Media, 60(2), pp.248-268.
7272](https://image.slidesharecdn.com/lucanannini-symposium11thoct-191016130246/85/Modeling-Causal-Reasoning-in-Complex-Networks-through-NLP-an-Introduction-72-320.jpg)

The document discusses the modeling of causal reasoning in complex networks through natural language processing (NLP), focusing on how communication influences the perception of causal features and the interpretation of linguistic ambiguity. It highlights challenges in causal inference and the role of linguistic, cognitive, and network variables in understanding social media interactions. A significant portion also covers the application of NLP techniques, including topic modeling, sentiment analysis, and the use of machine learning to analyze discourse, particularly in contexts like the vaccination debate on social media.































































