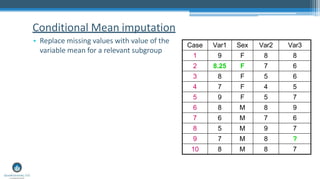
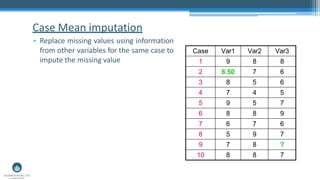
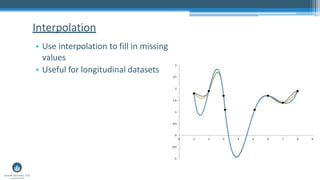
Missing data is a common challenge in data analysis. Methods for handling missing data aim to minimize bias, maximize use of available information, and accurately estimate uncertainty. There are two main categories of methods: deletion methods which remove cases or variables with missing data, and imputation methods which substitute values for the missing data. Multiple imputation, which generates multiple plausible values for the missing data, is now considered the best practice for handling missing data.