Download as PDF, PPTX



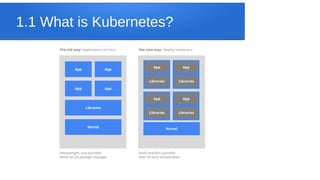
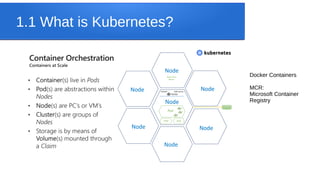






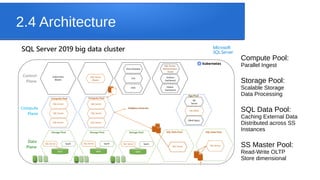



SQL Server Big Data Clusters allow for data exploration and analysis using SQL Server, Spark, HDFS, and Kubernetes. Key features include deploying clusters on any Kubernetes environment, management services for monitoring and high availability, and Polybase for querying external data stores via SQL. The architecture consists of compute, storage, and SQL pools distributed across SQL Server instances managed by Kubernetes. Azure Data Studio provides tools for working with relational and HDFS data on the clusters.












































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)















