Downloaded 63 times





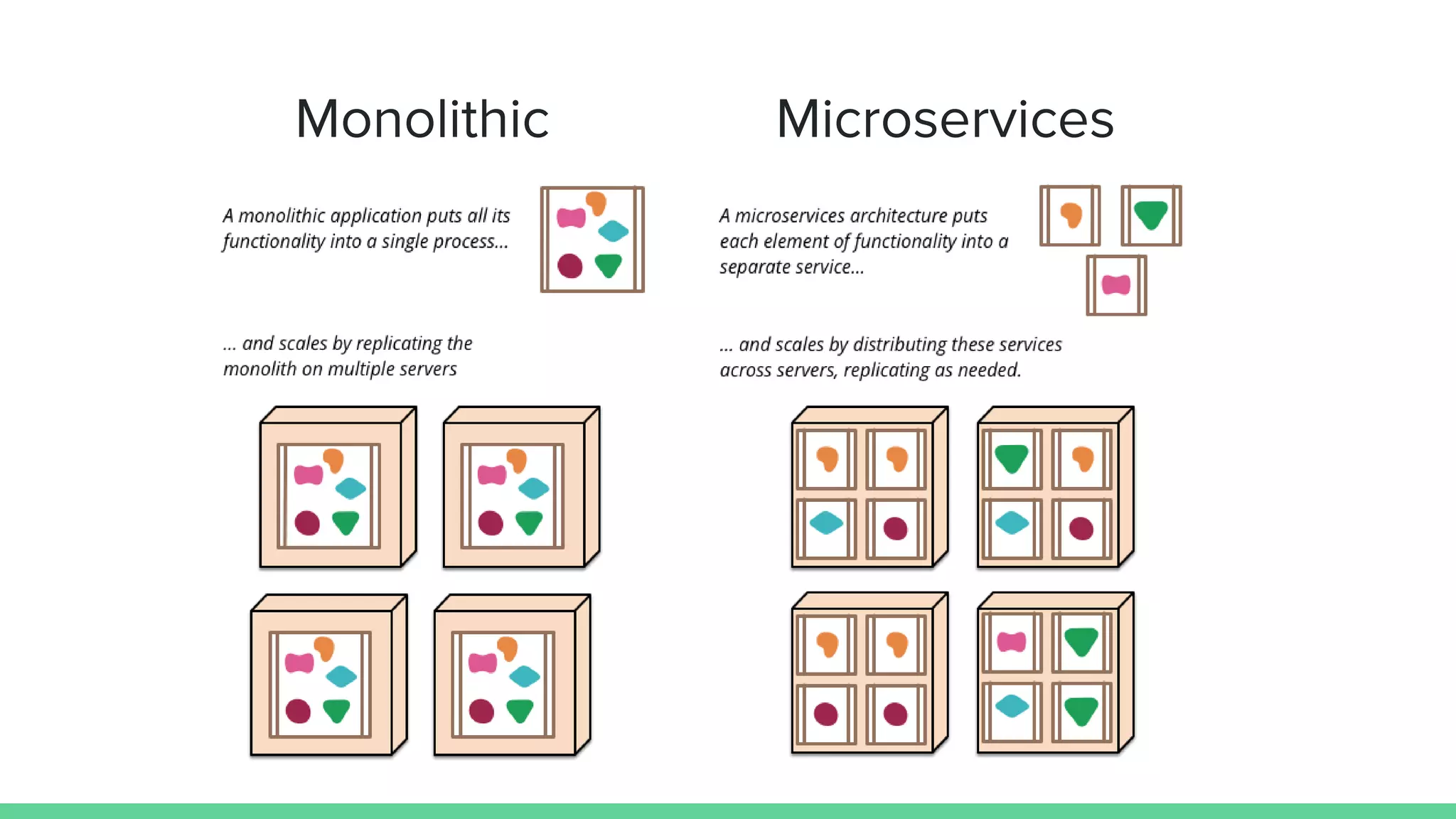


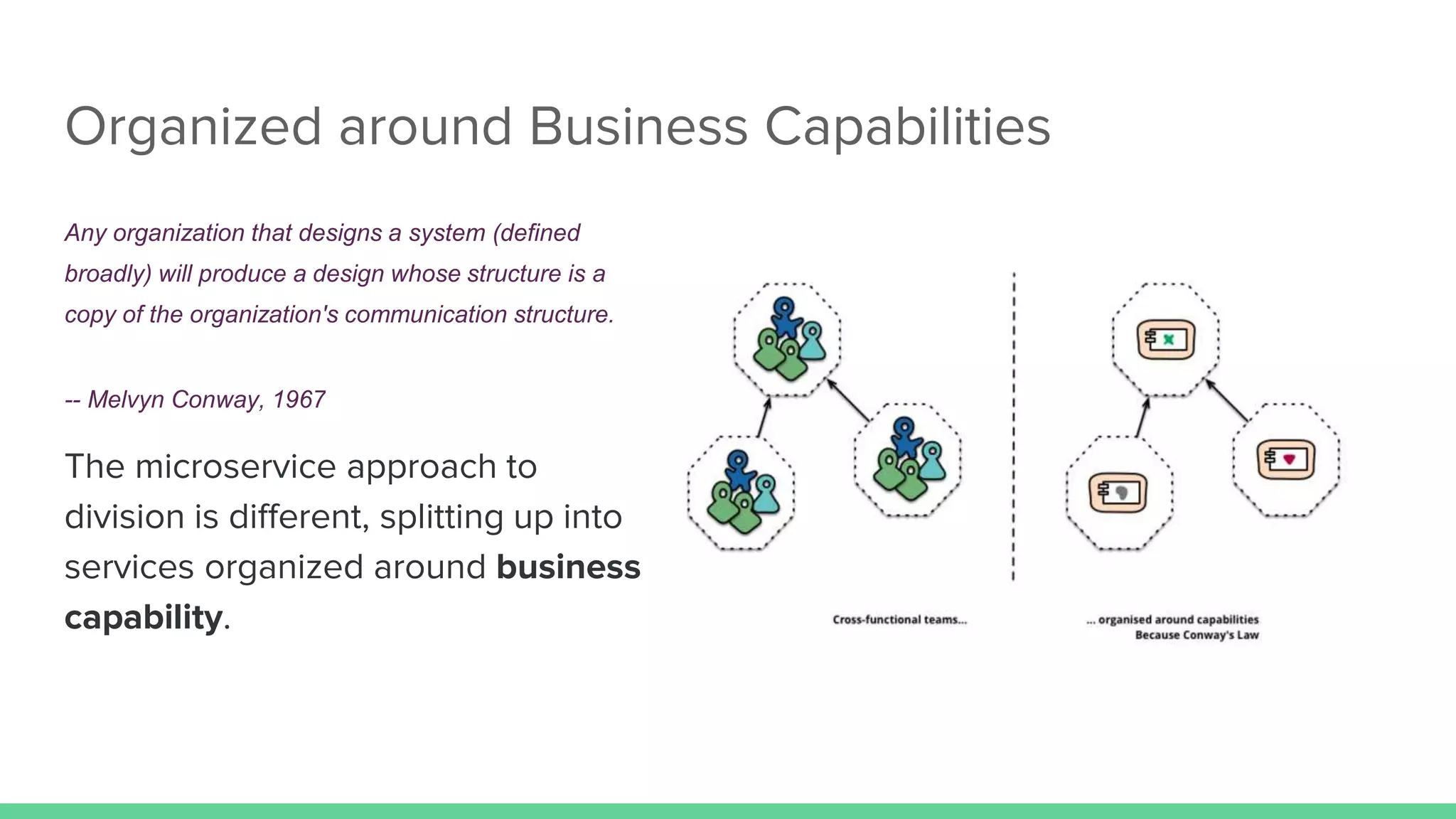




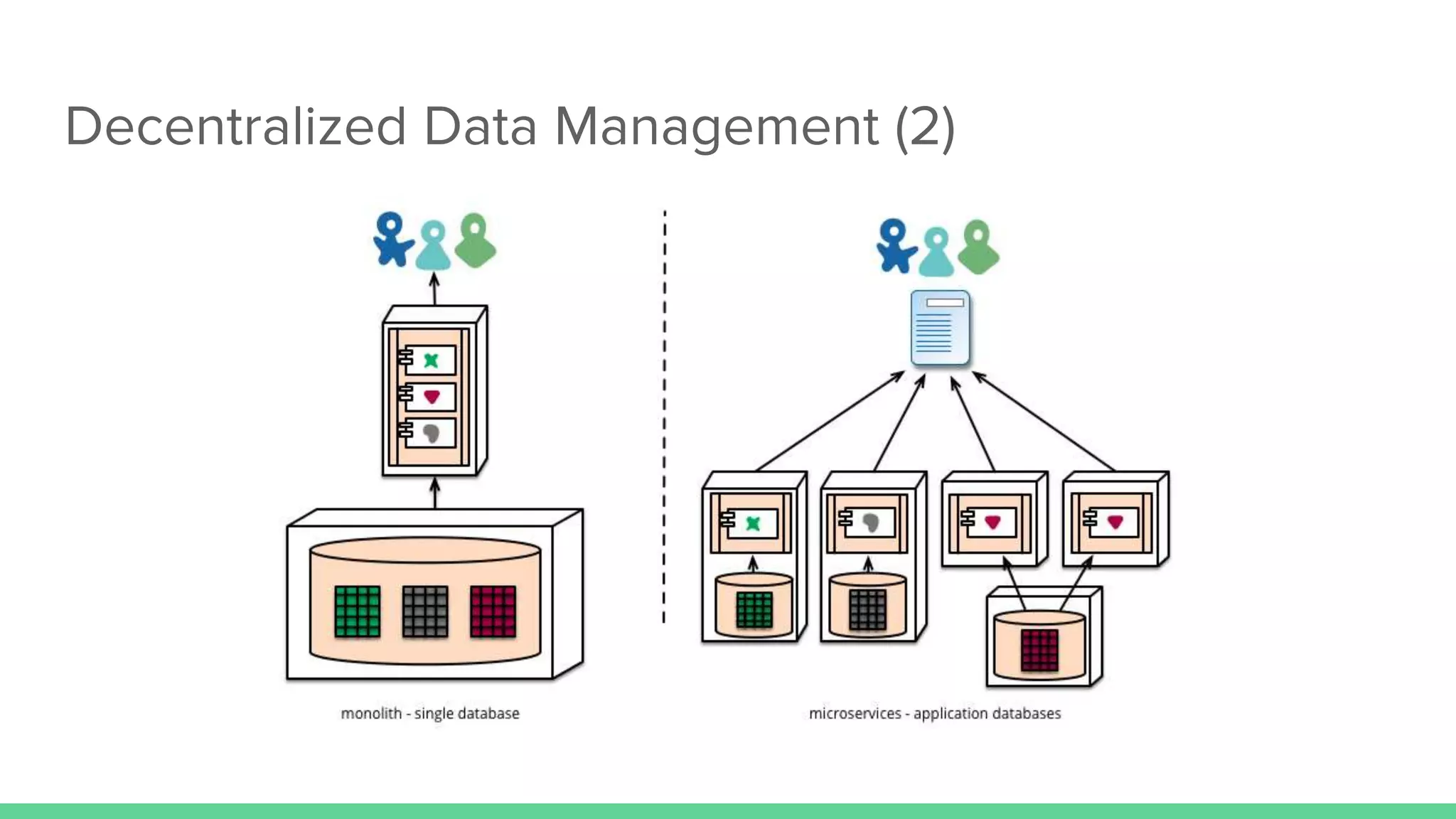
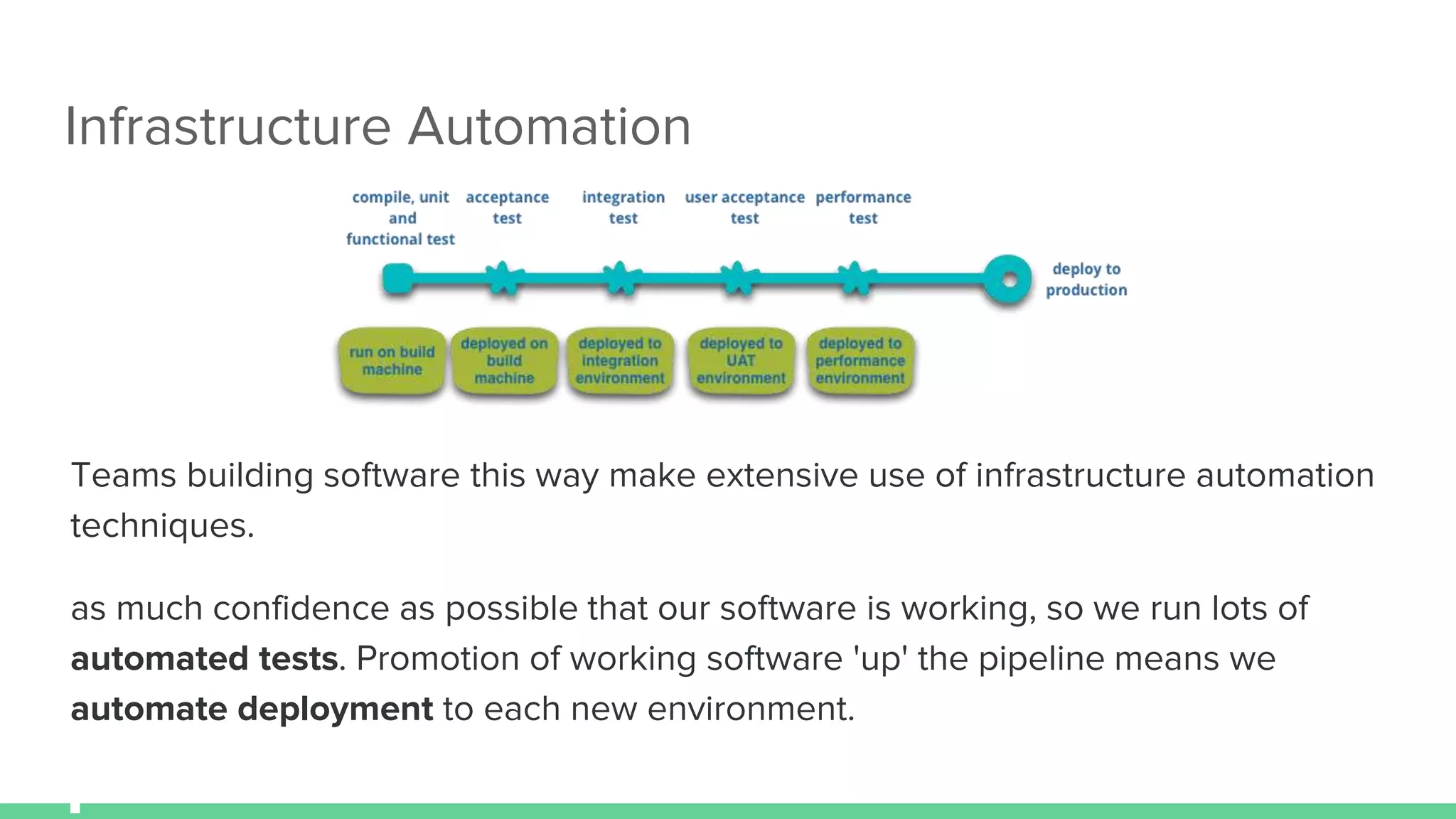








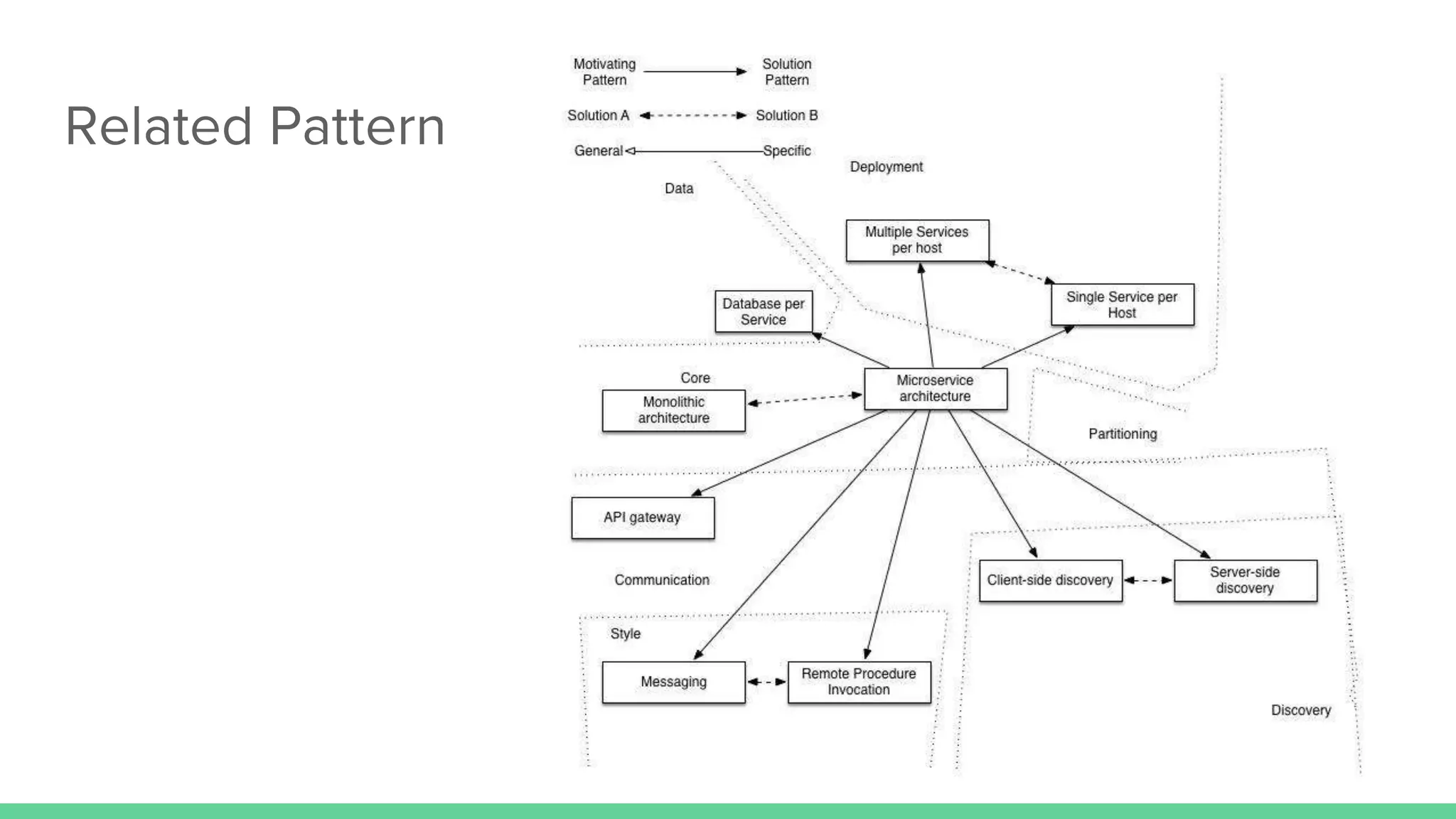
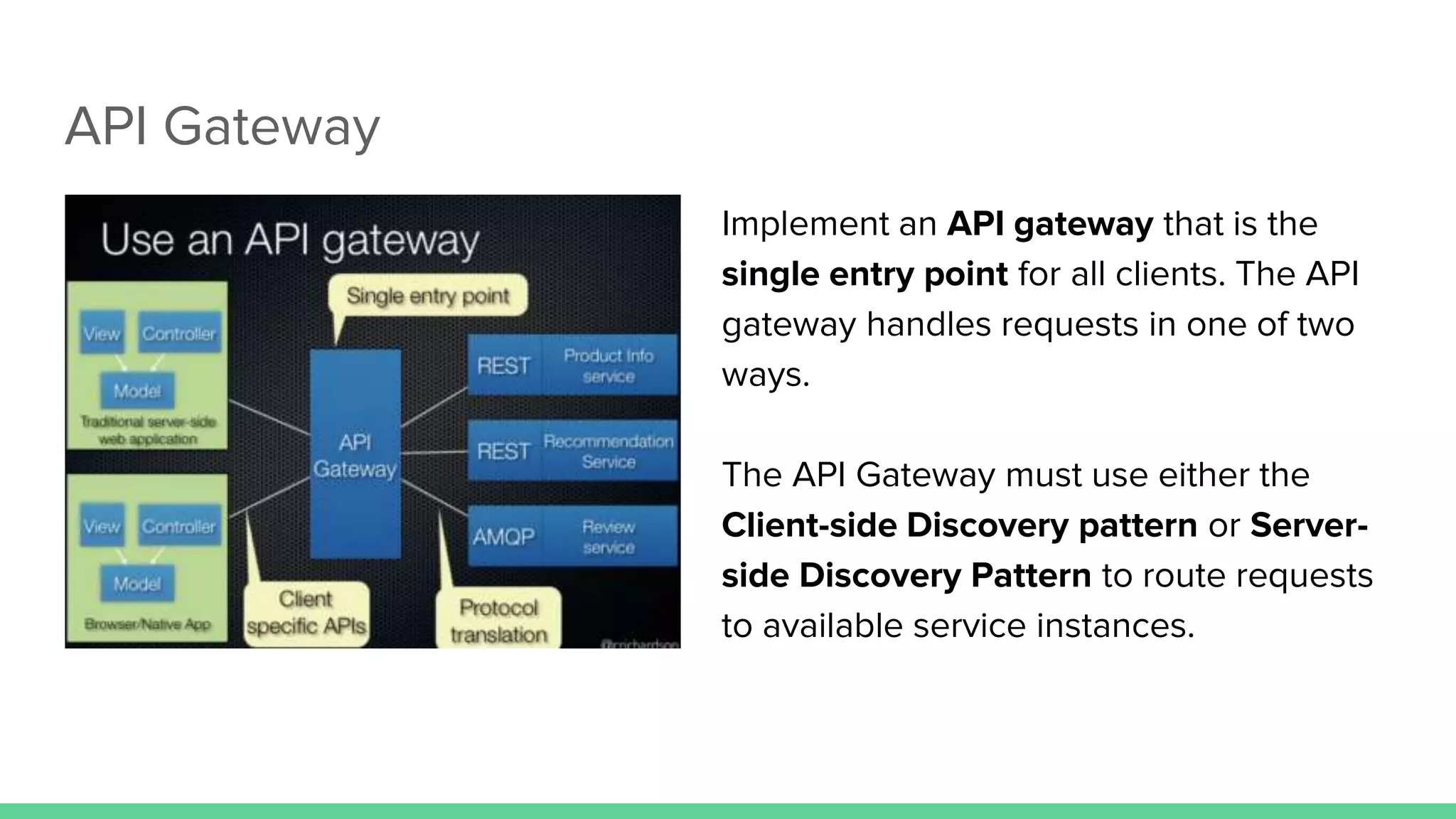

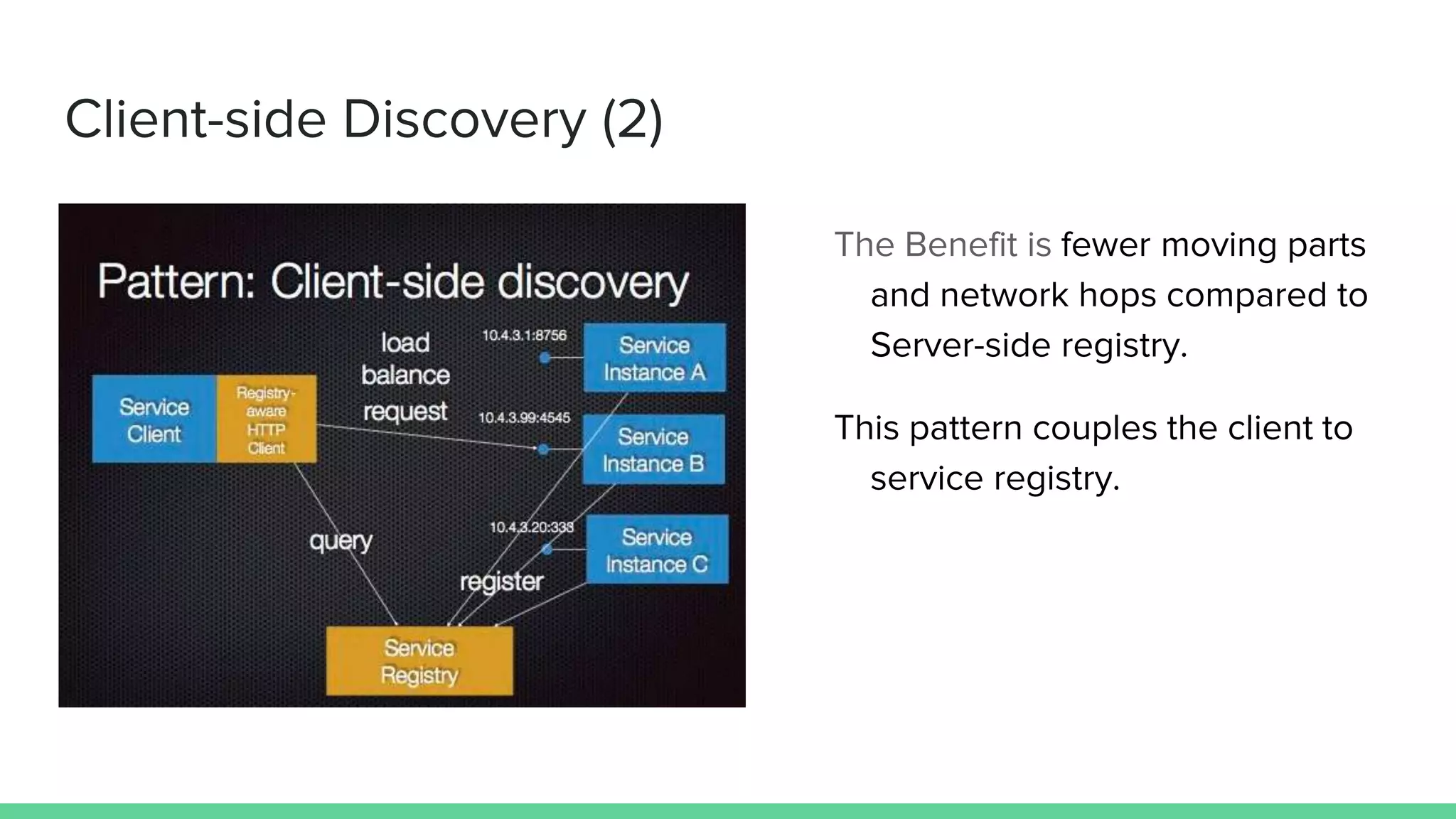
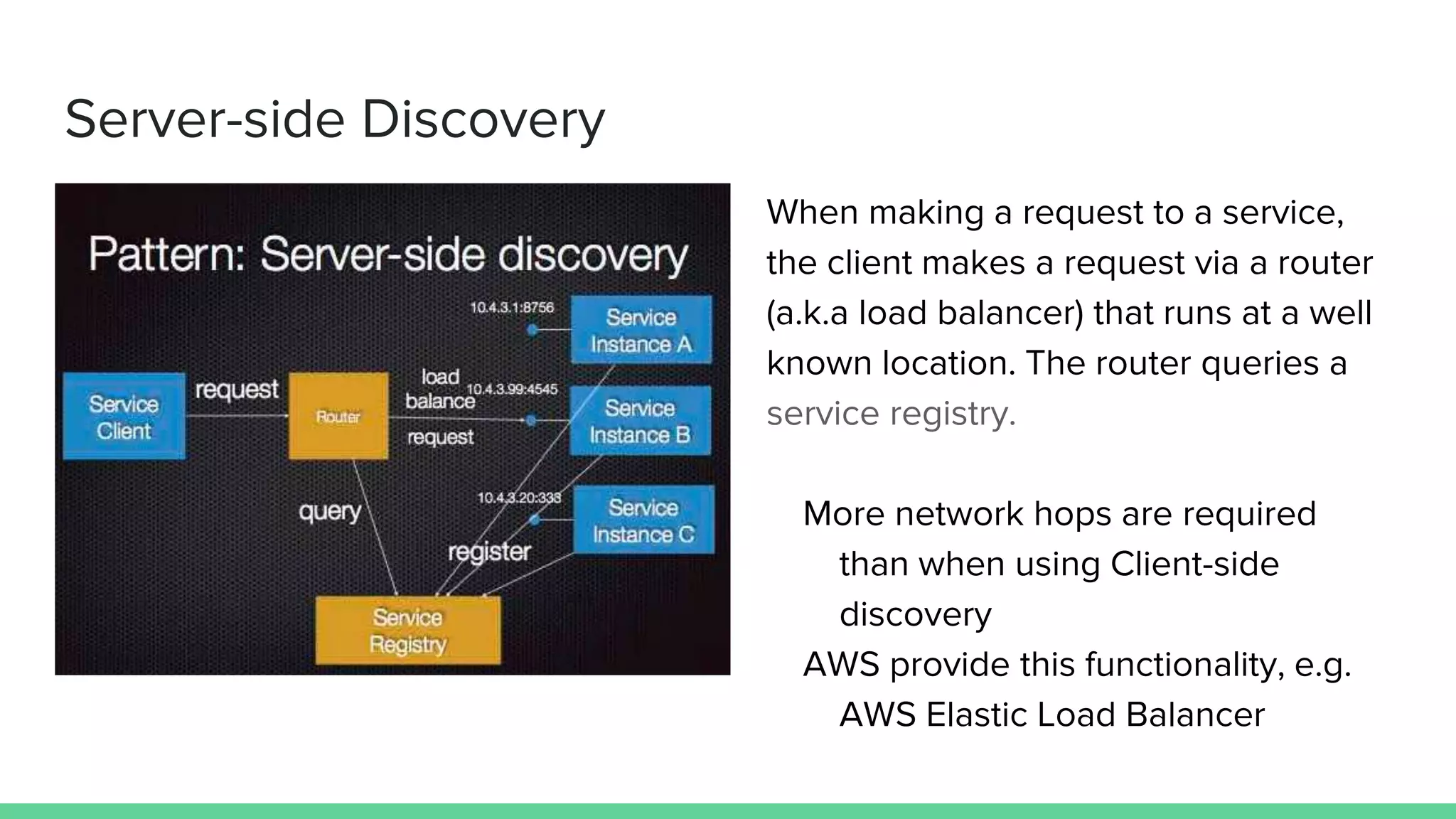






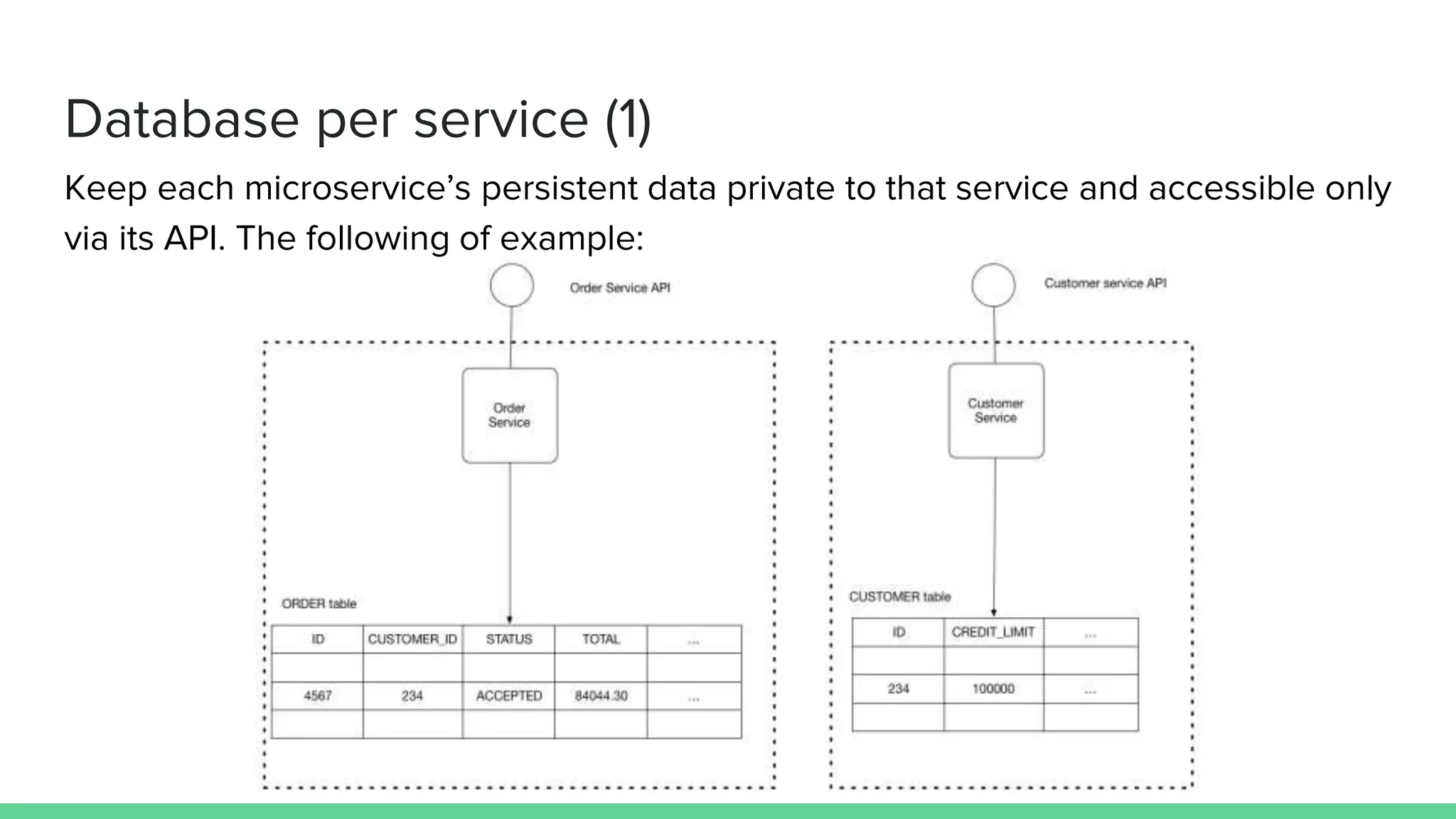


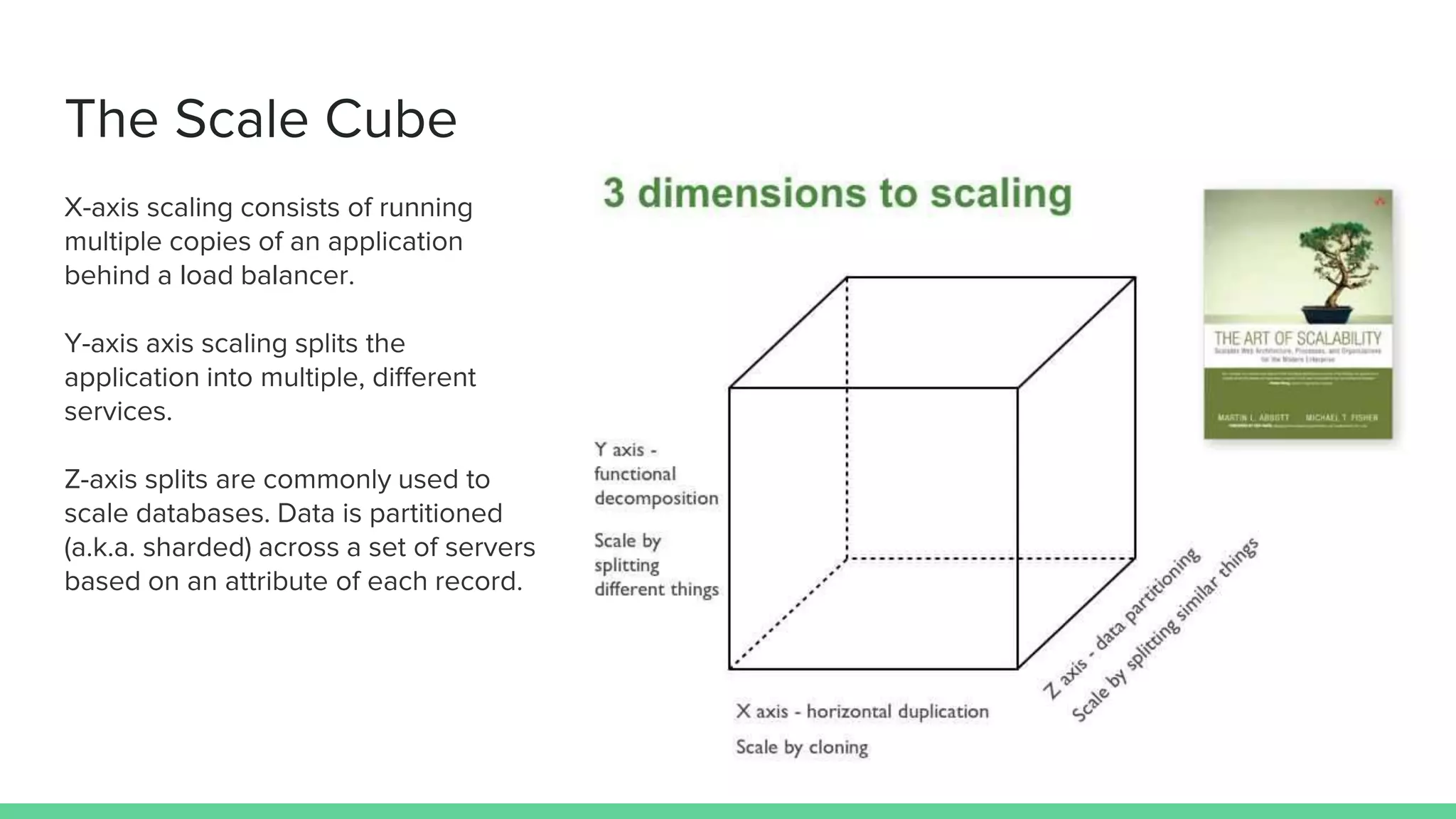

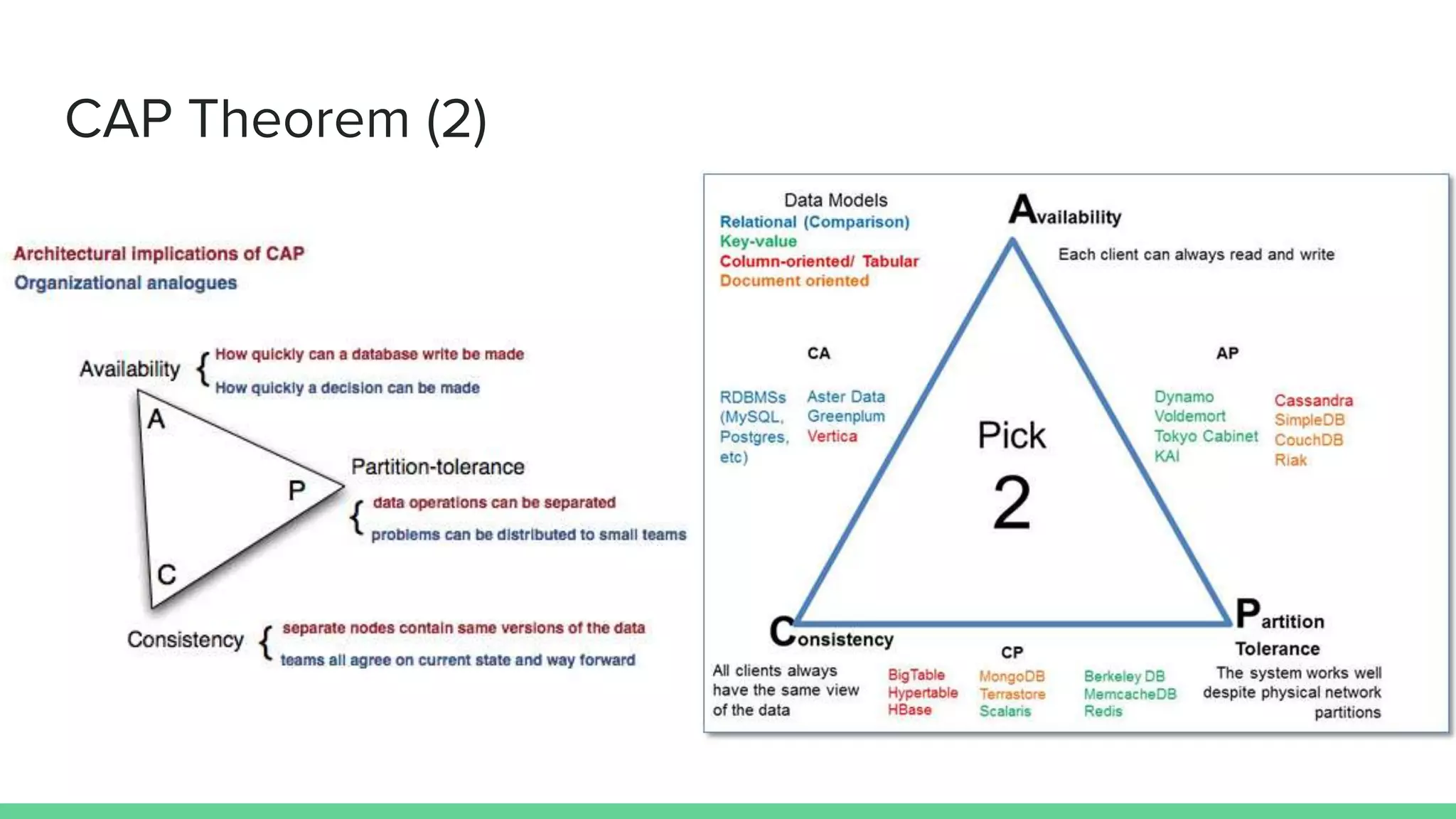


The document discusses microservices architecture, which is an approach to developing applications as a suite of small, independent services that communicate via lightweight mechanisms. It highlights the limitations of monolithic applications, such as challenges in scalability and frequent deployments, and outlines the characteristics, benefits, and principles of microservices, including decentralized governance, infrastructure automation, and fault isolation. Additionally, it covers various design patterns, such as API gateways and service registries, and emphasizes the importance of service independence and organization around business capabilities.





















































































