































![• Cache indexes in MySQL/InnoDB:
• Increase innodb_buffer_pool_size
• Used for both data and indexes
• Cache indexes in MySQL/MyISAM:
• Increase key_buffer_size
• LOAD INDEX INTO CACHE TableName
[INDEX IndexName];](https://image.slidesharecdn.com/mentoryourindexes-100921135033-phpapp01/75/Mentor-Your-Indexes-34-2048.jpg)









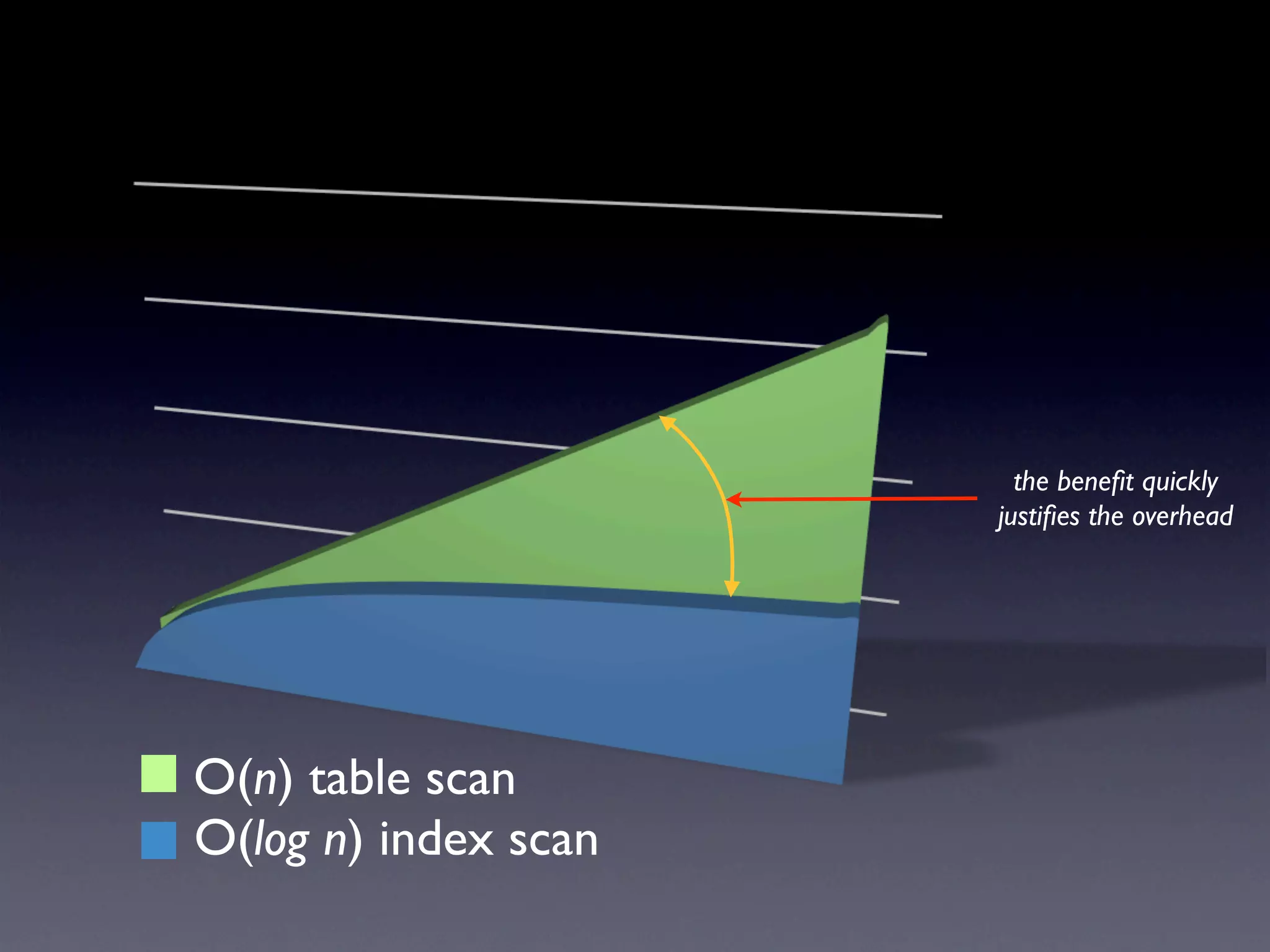
The document discusses best practices for indexing in databases to optimize query performance, including common mistakes like creating unnecessary or redundant indexes. It emphasizes the importance of profiling queries, analyzing optimization plans, and maintaining indexes periodically to ensure efficient data retrieval. The author, Bill Karwin, encourages understanding data and queries to effectively mentor database indexes and improve performance.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














