The tutorial on self-motivated agents emphasizes improving exploration in reinforcement learning (RL) through memory-driven curiosity to enhance learning efficiency. It highlights the challenges and strategies in RL, including advanced topics like language-guided exploration and causal discovery. The authors, from Deakin University, aim to address practical issues in RL applications by incorporating memory-based exploration techniques.





![5
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction 👈 [We are here]
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes,
including a 20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven
Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-5-320.jpg)

![7
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Key components and frameworks 👈 [We are here]
Classic exploration
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-7-320.jpg)



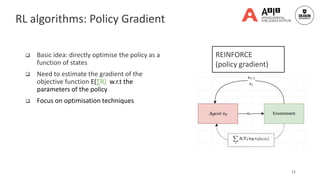
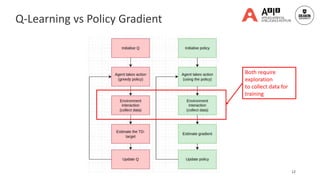
![13
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Key components and frameworks
Classic exploration 👈 [We are here]
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-13-320.jpg)

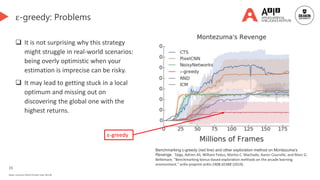





![21
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
Hard Exploration Problems 👈 [We are here]
Simple exploring solutions
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-21-320.jpg)



![25
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
Hard exploration problems
Simple exploring solutions 👈 [We are here]
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-25-320.jpg)




![30
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks 👈 [We are here]
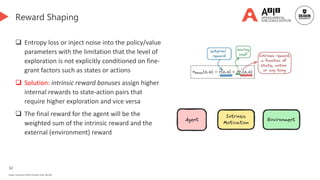
Reward shaping and the role of memory
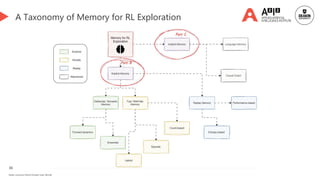
A taxonomy of memory-driven intrinsic exploration
Deliberate Memory for Surprise-driven Exploration
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-30-320.jpg)
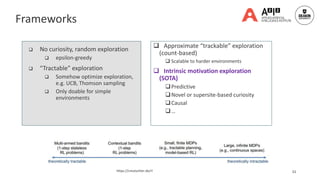


![37
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
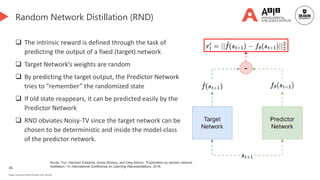
Forward dynamics prediction👈 [We are here]
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-37-320.jpg)





![43
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises👈 [We are here]
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-43-320.jpg)







![55
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement 👈 [We are here]
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-55-320.jpg)



![60
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break👈 [We are here]
RAM-like Memory for Novelty-based
Exploration
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-60-320.jpg)
![61
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
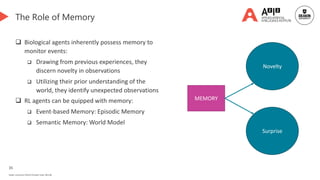
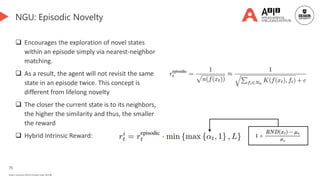
Count-based memory 👈 [We are here]
Episodic memory
Hybrid memory
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-61-320.jpg)
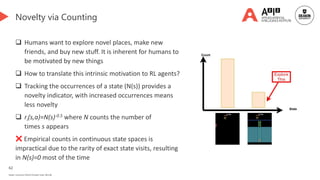



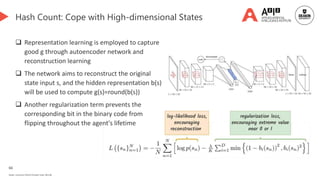
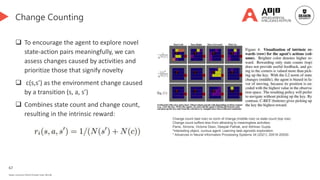
![68
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Count-based memory
Episodic memory👈 [We are here]
Hybrid memory
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-68-320.jpg)

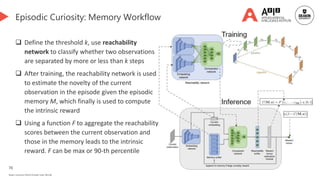


![73
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Count-based memory
Episodic memory
Hybrid memory 👈 [We are here]
Replay Memory
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-73-320.jpg)
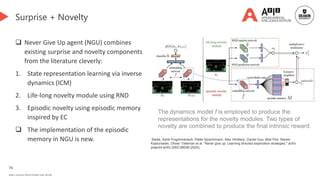


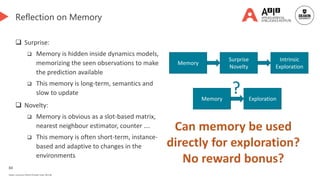
![85
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay 👈 [We are here]
Performance-based Replay
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-85-320.jpg)
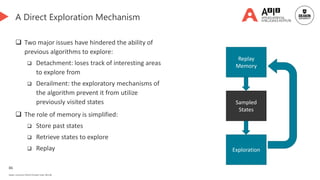



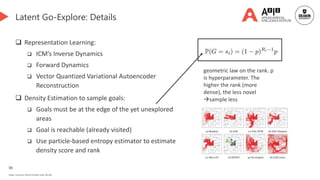
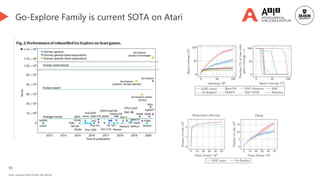
![92
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay👈 [We are here]
QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-92-320.jpg)

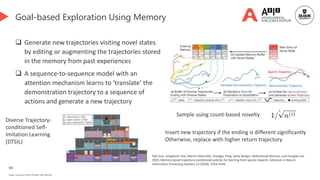



![100
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
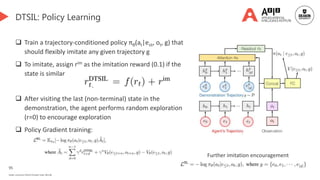
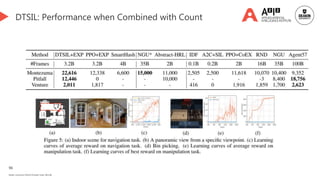
Language-guided exploration👈 [We are here]
Language-assisted RL
LLM-based exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-100-320.jpg)



![104
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Language-assisted RL 👈 [We are here]
LLM-based exploration
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-104-320.jpg)

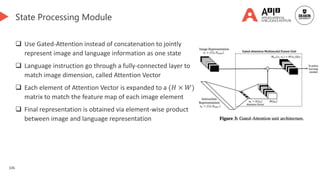



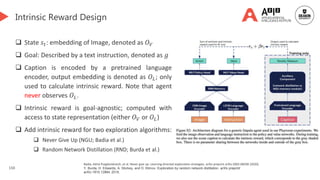


![114
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Language-assisted RL
LLM-based exploration👈 [We are here]
Causal discovery for exploration
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-114-320.jpg)








![123
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
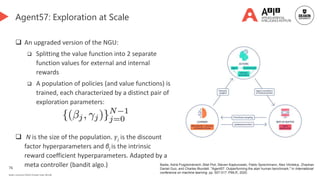
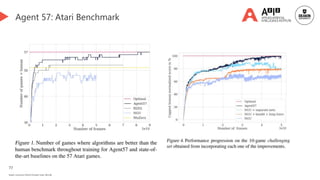
Causal discovery for exploration👈 [We are here]
Statistical approaches
Deep learning approaches
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-123-320.jpg)


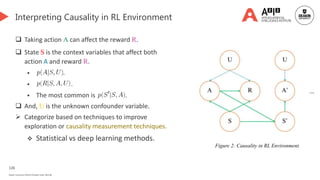
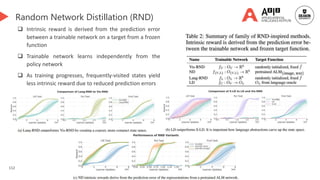
![127
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Statistical approaches👈 [We are here]
Deep learning approaches
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-127-320.jpg)

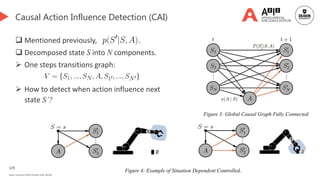
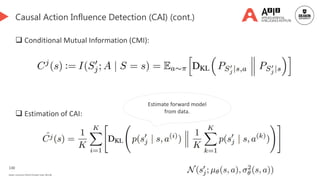

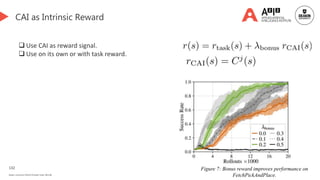


![135
Tutorial Outline
Part A: Reinforcement Learning Fundamentals and
Exploration Inefficiency (30 minutes)
Welcome and Introduction
Reinforcement Learning Basics
Exploring Challenges in Deep RL
QA and Demo
Part B: Surprise and Novelty (110 minutes, including a
20-minute break)
Principles and Frameworks
Deliberate Memory for Surprise-driven Exploration
Forward dynamics prediction
Advanced dynamics-based surprises
Ensemble and disagreement
Break
RAM-like Memory for Novelty-based
Exploration
Replay Memory
Novelty-based Replay
Performance-based Replay QA and Demo
Part C: Advanced Topics (60 minutes)
Language-guided exploration
Causal discovery for exploration
Statistical approaches
Deep learning approaches👈 [We are
here]
Closing Remarks
QA and Demo](https://image.slidesharecdn.com/aamastutorial-240511235803-0e379d27/85/Unlocking-Exploration-Self-Motivated-Agents-Thrive-on-Memory-Driven-Curiosity-135-320.jpg)