Verilerin dijital ortamdasaklanmaya başlanması ile
birlikte, yeryüzündeki bilgi miktarının her 20 ayda bir
iki katına çıktığı günümüzde, veri tabanlarının sayısı da
benzer, hatta daha yüksek bir oranda artmaktadır.
Akıllı veri işleme metodu olan veri madenciliği, dünya
üzerinde artan veri miktarının etkili bir biçimde
kullanılmasının neredeyse tek çözümü olarak
görünmektedir. Bu gelişme diğer alanlarda olduğu gibi
tıp alanında da ilgi odağı haline gelmiştir. Özellikle tıp
alanındaki verinin büyüklüğü ve hayati önem taşıması
bu alandaki uygulamaları daha da önemli kılmaktadır.
3.
Tıpta birçok alanda aşırı veri birikmesinin en yoğun
yaşandığı alanlardan birisi de tıbbi verilerdir.
Özellikle günümüzde artık neredeyse tüm tıbbi
cihazların dijital hale gelmesi bu sonucu doğal hale
getirmiştir.
Kağıt üzerinde veri toplanan klasik hastane bilgi
sistemlerinden farklı olarak buradaki verilerden
yararlanmak her ne kadar çok daha kolay gibi görünse
de, aslında diğer alanlardaki veriler gibi bunların da
bireysel çalışmalarla işlenmesi ve yorumlanması
imkansız hale gelmiştir.
4.
Tıp alanında verimadenciliği uygulamalarına örnek
olarak;
antipsikotik ilaçların kalp kası hastalıkları üzerine etkisi
solunum fonksiyon testlerinin analizi
genetik bozuklukların tespiti
ilaç yan etkilerinin tanımlanması
gibi çeşitli çalışmaları sayabiliriz.
5.
Veri madenciliği; belirli bir alanda ve belirli bir amaç için
toplanan veriler arasındaki gizli kalmış ilişkilerin ortaya
konulmasıdır.
Bunun yanında, geleceğe dönük kararlar almamızda bize fikir
verir.
Veri madenciliği, disiplinler arası doğasından dolayı istatistik,
veri tabanları, makine öğrenmesi, bilgi toplama, görselleştirme,
paralel ve dağıtık hesaplama gibi birçok disiplinden yardım alır.
6.
Data Mining Aşamaları;
Uygulama Alanın Ortaya Konulması
Veri Ambarının Oluşturulması
Modelin Kurulması ve Değerlendirilmesi
Şablonların ve İlişkilerin Yorumlanması
7.
Veri Madenciliğindeki Problemler;
Veri madenciliği girdi olarak ham veriyi sağlamak
üzere veri tabanlarına dayanır.
Bu da veri tabanlarının dinamik, eksiksiz, geniş
ve net veri içermemesi durumunda sorunlar
doğurur. Diğer sorunlar da verinin konu ile
uyumsuzluğundan doğabilir.
Sınıflandırmak gerekirse başlıca sorunlar
şunlardır :
8.
Sınırlı Bilgi : Veri tabanları genel olarak veri madenciliği dışındaki amaçlar için
tasarlanmışlardır. Bu yüzden, öğrenme görevini kolaylaştıracak bazı özellikler
bulunmayabilir.
Gürültü ve Eksik Değerler : Veri özellikleri ya da sınıflarındaki hatalara gürültü
adı verilir. Veri tabanlarındaki eksik bilgi ve bu yanlışlardan dolayı veri
madenciliği amacına tam olarak ulaşmayabilir. Bu bilgi yanlışlığı, ölçüm
hatalarından, ya da öznel yaklaşımdan olabilir.
Belirsizlik : Yanlışlıkların şiddeti ve verideki gürültünün derecesi ile ilgilidir. Veri
tahmini bir keşif sisteminde önemli bir husustur.
Ebat, güncellemeler ve konu dışı sahalar : Veri tabanlarındaki bilgiler, veri
eklendikçe ya da silindikçe değişebilir. Veri madenciliği perspektifinden
bakıldığında, kuralların hala aynı kalıp kalmadığı ve istikrarlılığı problemi ortaya
çıkar. Öğrenme sistemi, kimi verilerin zamanla değişmesine ve keşif sisteminin
verinin zamansızlığına karşın zaman duyarlı olmalıdır.
9.
Tıbbi Verinin Oluşturulması;
Tıbbi veriler üzerinde çalışma yapmak bu verileri iyi tanımakla
mümkündür.
Tıp alanında belirli bir standardın olmayışı ve varolan standartlar
arasında tam bir uyumun olmaması nedeniyle, bu alanında bir veri
ambarının oluşturulması oldukça zor bir işlemdir.
Bunun yanı sıra tıp alanındaki terimlerin hem karışık hem de
birbirine yaklaşık olması da veri ambarı oluşumunu negatif yönde
etkilemektedir.
Tıp alanındaki veri genellikle farklı kaynaklarda toplanmaktadır.
Örneğin hastanın laboratuar ile ilgili verileri ile hastanın teşhis
bilgileri farklı kaynaklarda ve farklı şekillerde tutulmaktadır.
10.
Tıpta Veri MadenciliğiUygulama Alanları;
A.Kusiak ve arkadaşları tarafından akciğer deki tümörün iyi huylu
olup olmadığına dair, karar destek amaçlı bir çalışma yapılmıştır.
İstatistiklere göre Amerika da 160.000 den fazla akciğer kanseri
vakasının olduğu ve bunların %90’ının öldüğü belirlenmiştir. Bu
bağlamda bu tümörün erken ve doğru olarak teşhisi önem
kazanmaktadır. Noninvaziv testler ile elde edilen bilgi sayesinde
%40-60 oranında doğru teşhis konabilmektedir. İnsanlar kanser
olup olmadıklarından emin olmak için biyopsi yaptırmayı tercih
etmektedirler. Biyopsi gibi invaziv testler hem maliyeti yüksek
hem çeşitli riskler taşımaktadır. Faklı yerlerde ve farklı
zamanlarda kliniklerde toplanan invaziv test verileri arasında
yapılan veri madenciliği çalışmaları teşhiste %100 oranında
doğruluk sağlamıştır.
11.
Başka bir çalışma ise Kore Tıbbi Sigorta Kurumu
tarafından hazırlanan bir veri tabanı üzerinde yapılan
yüksek tansiyon ile ilgili bir çalışmadır. Bu çalışma 1998
yılına ait 127,886 kayıt üzerinde yapılmıştır. İlk aşamada
yüksek tansiyona sahip 9,103 kayıt üzerinde, daha sonra
aynı sayıda yüksek tansiyonu olmayan kayıtlar üzerinde
çalışılmıştır. Bu örnek 13,689 kayıttan oluşan öğrenme ve
4,588 kayıttan oluşan test setine bölünerek modelin eğitimi
yapılmıştır. Bu çalışmalar sonuçunda yüksek tansiyon
tahmininde etkili değerler urinary protein, kan glikozu,
kolesterol değerleridir. Yaşam koşullarının (diyet, alınan tuz
miktarı, alkol, tütün gibi) hiçbirinin tahminde etkili
olmadığı ayrıca grafiksel değerlerde de yalnızca yaşın etkili
olduğu saptanmıştır.
12.
WEKA;
WEKA bir proje olarak başlayıp bugün dünya üzerinde birçok
insan tarafından kullanılmaya başlanan bir Veri Madenciliği
uygulaması geliştirme programıdır.
Java platformu üzerinde geliştirilmiş açık kodlu bir
programdır.
WEKA ’nın içerisinde Veri İşleme, Veri Sınıflandırma, Veri
Kümeleme, Veri İlişkilendirme özellikleri mevcuttur.
Projenin amacına göre uygun algoritma veya algoritmalar
seçilerek veriler üzerine uygulanmakta ve en doğru sonucu
veren algoritma seçilebilmektedir.
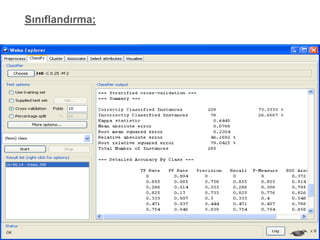
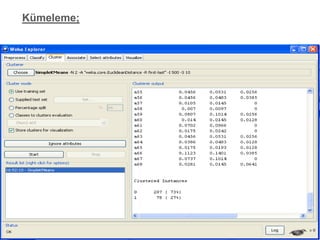
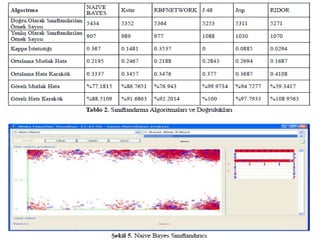
13.
Her bir verimadenciliği algoritmasının WEKA’ daki
kullanımına ilişkin örnek uygulaması;
Bu uygulamalar esnasında kullanılacak veri kümesi 285
adet örnek mide kanseri verisi içermekte olup 9 sınıf ve
7 adeti nümerik kalanları ise kategorik olmak üzere 68
niteliğe sahiptir. Veritabanı içerisinde 970 adet kayıp veri
bulunmakta olup bütün veritabanı içerisinde %5’lik bir
belirsizlik söz konusudur.
Son olarak şunu söyleyebiliriz; Data Mining
özellikle insan sağlığı ile ilgili olduğu için tıbbi
kullanımı ile oldukça önemli bir uygulama alanı
bulacaktır. Bu konuda önemini son yıllarda giderek
artan çalışmalar ile de ortaya koymaya başlamıştır.