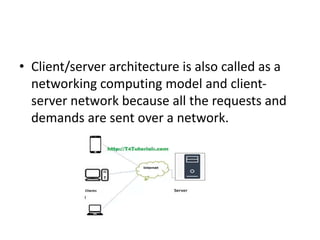
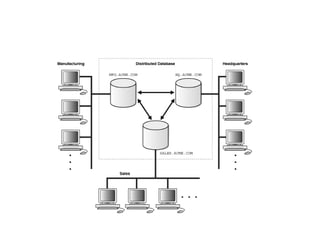
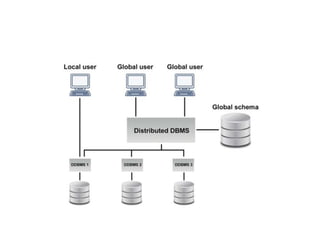
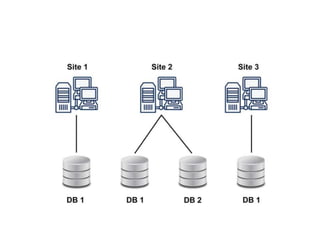
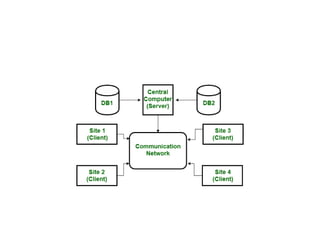
The document discusses client-server database architecture. Some key points:
- In client-server architecture, multiple clients connect to a central server which provides services to the clients. The server processes clients' requests and returns results.
- The architecture divides applications into presentation, logic, and data tiers. The presentation tier handles the user interface. The logic tier controls application functions. The data tier stores and retrieves data from the database.
- Advantages include centralized data control and scalability. Disadvantages are potential single point of failure if the server fails and increased hardware/software costs.