Downloaded 35 times




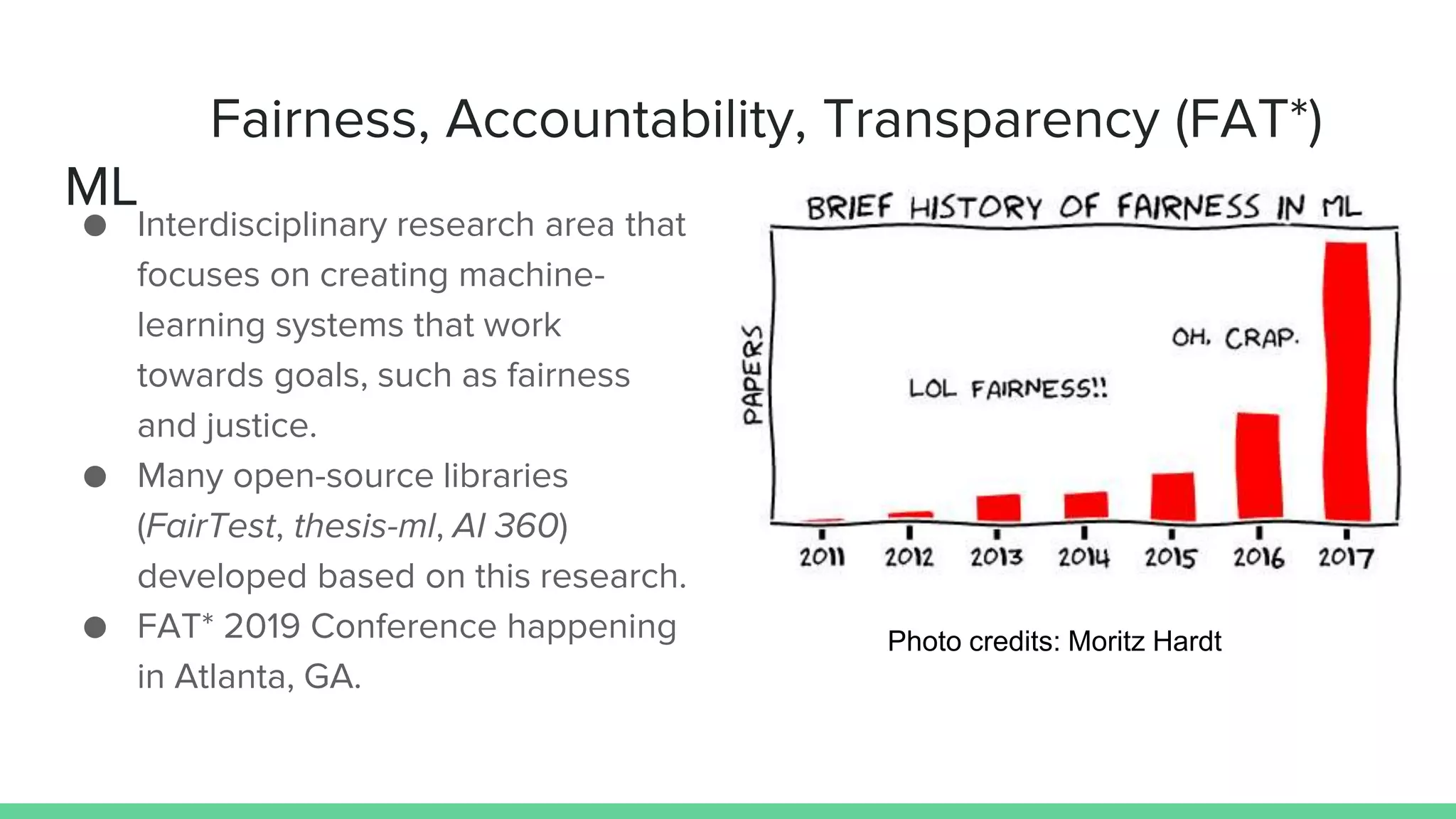





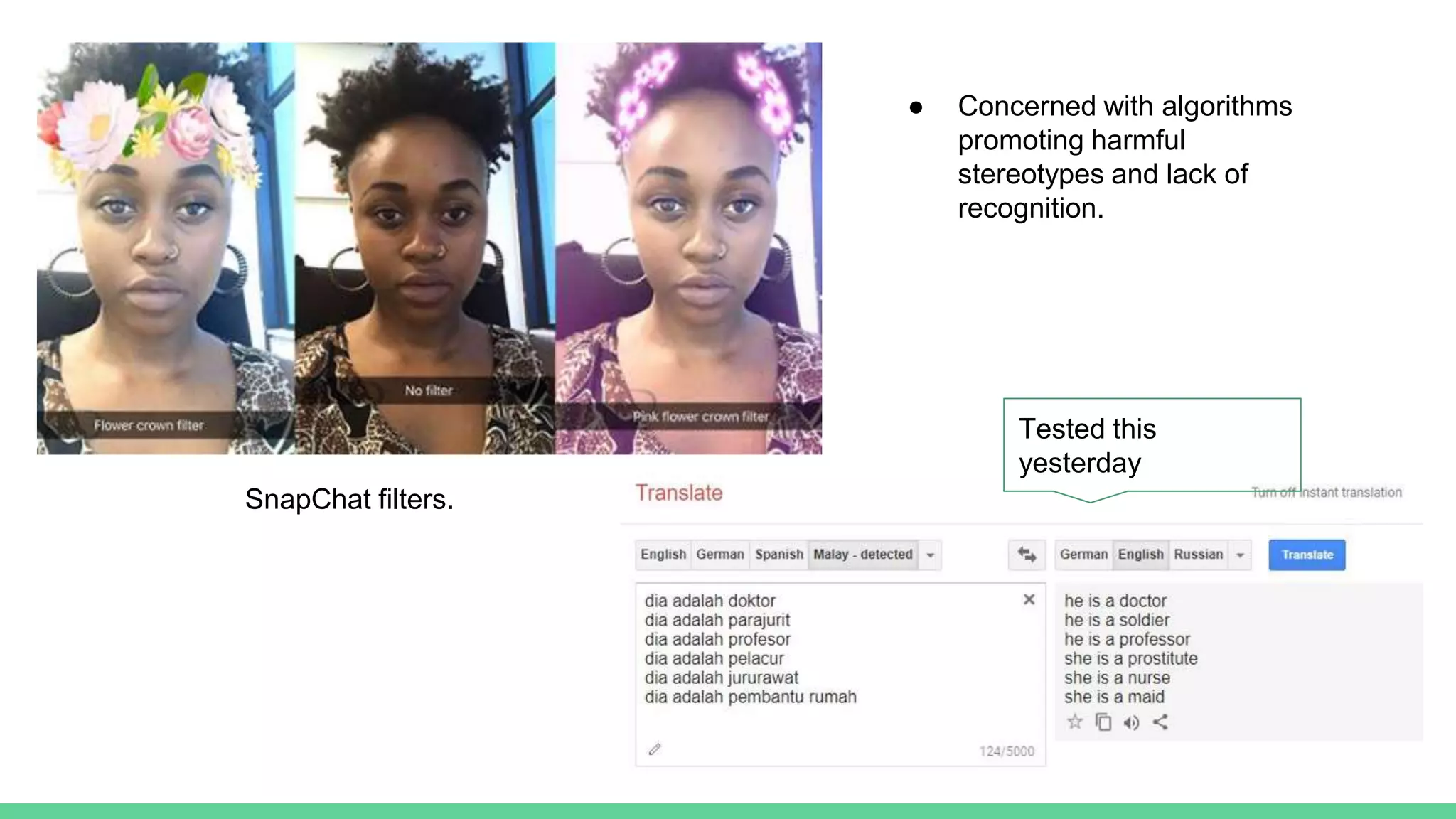




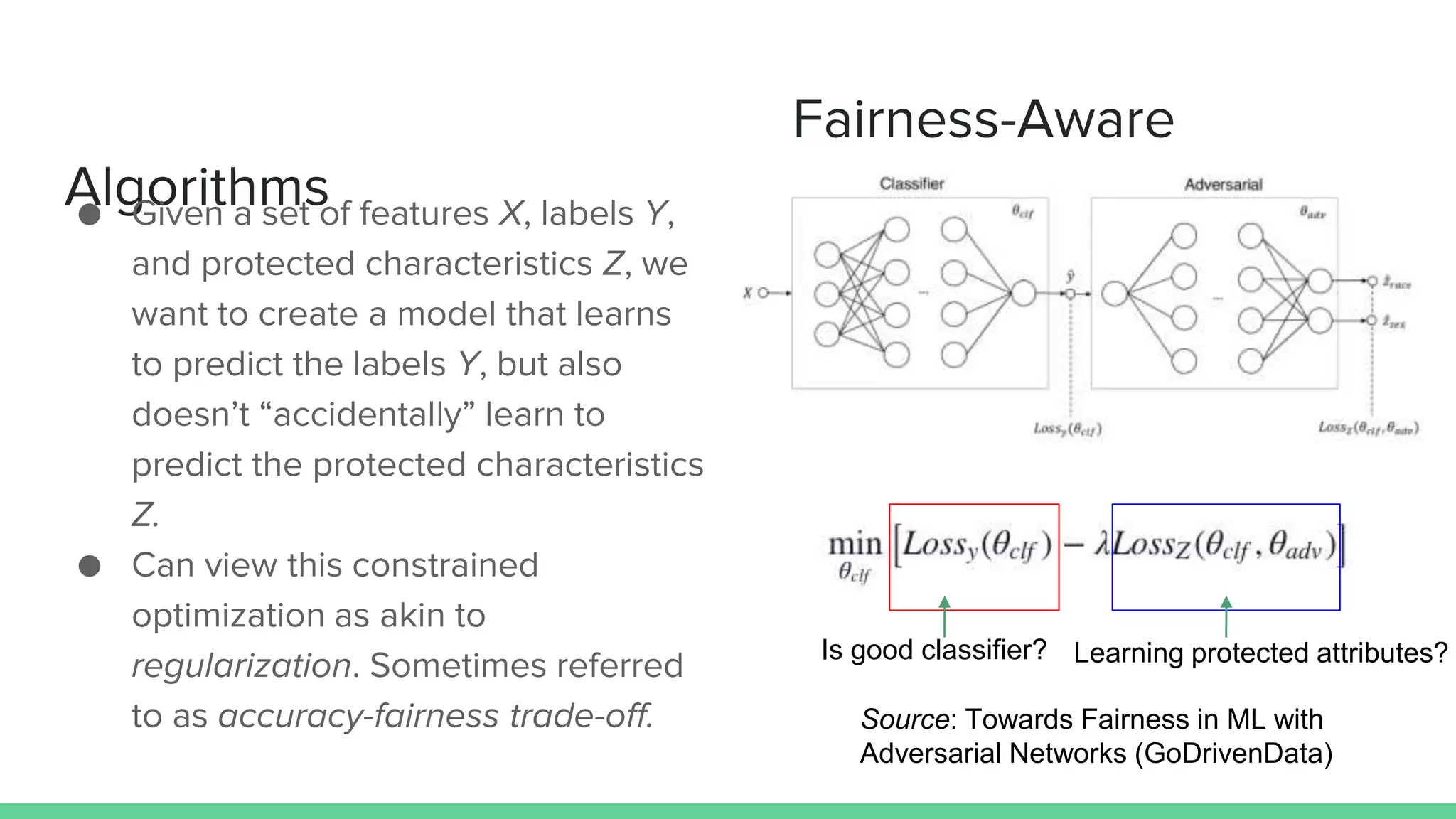
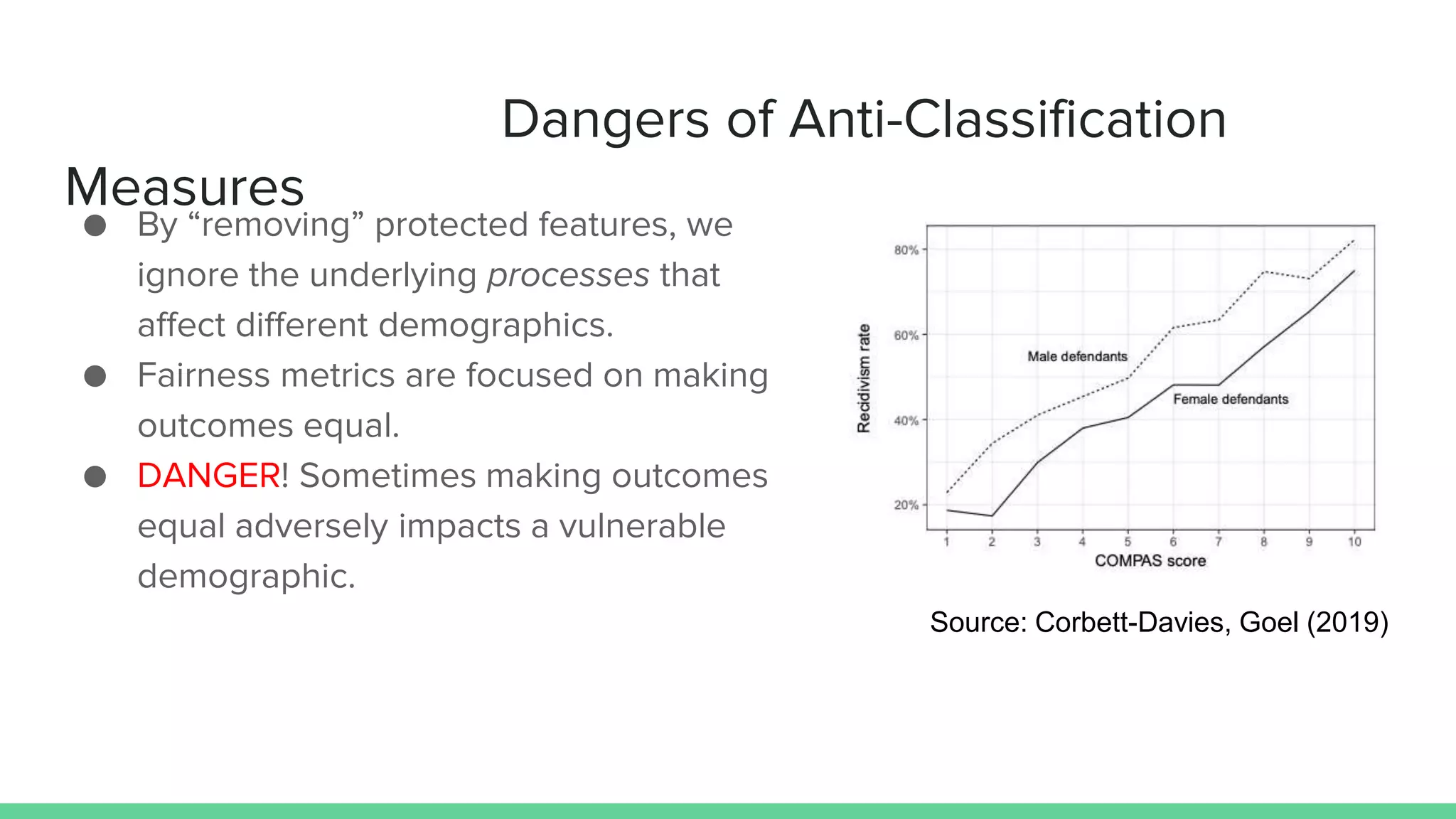
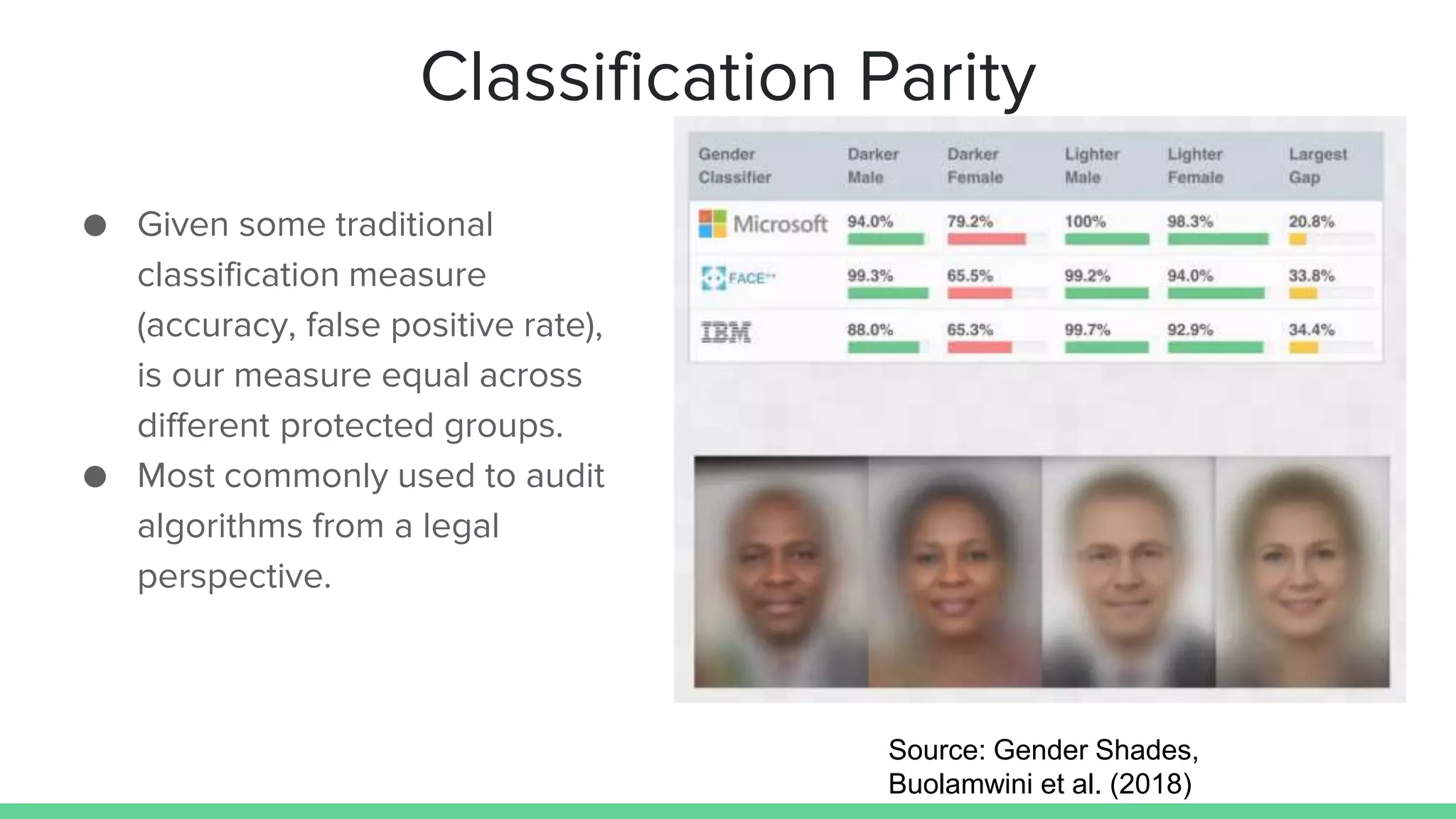













This document discusses various measures and challenges of achieving algorithmic fairness. It begins by defining algorithmic fairness and noting it is inherently a social concept. It then covers three main types of algorithmic biases: bias in allocation, representation, and weaponization. It outlines three families of fairness measures: anti-classification, classification parity, and calibration. It notes each approach has dangers and no single definition of fairness exists. The document concludes by discussing proposed standards for documenting datasets and models to improve algorithmic transparency and accountability.


































































