The binary search algorithm allows for faster searching of an ordered array compared to linear search. It works by first examining the middle element of the array and eliminating half of the elements from further search based on whether the target value is less than or greater than the middle element. This process continues, halving the search space on each iteration, allowing binary search to have a time complexity of O(log n).
![Explanation of binary search algorithm
Suppose we are given a number of integers stored in an array A, and we want to locate a specific target integer K
in this array. If we do not have any information on how the integers are organized in the array, we have to
sequentially examine each element of the array. This is known as linear search and would have a time complexity
of O(n ) in the worst case. However, if the elements of the array are ordered, let us say in ascending order, and we
wish to find out the position of an integer target K in the array, we need not make a sequential search over the
complete array. We can make a faster search using the Binary search method. The basic idea is to start with an
examination of the middle element of the array. This
will lead to 3 possible situations:
If this matches the target K then search can terminate successfully by printing out the index of the element in the
array. On the other hand, if K<A[middle], then search can be limited to elements to the left of A[middle]. All
elements to the right of middle can be ignored. If it turns out that K >A[middle], then further search is limited to
elements to the right of A[middle]. If all elements are exhausted and the target is not found in the array, then the
method returns a special value such as –1. Here is one version of the Binary Search function:
int BinarySearch (int A[ ], int n, int K)
{
int L=0, Mid, R= n-1;
while (L<=R)
{
Mid = (L +R)/2;
if ( K= =A[Mid] )
return Mid;
else if ( K > A[Mid] )
L = Mid + 1;
else
R = Mid – 1 ;
}
return –1 ;
}
Let us now carry out an Analysis of this method to determine its time complexity. Since there are no “for” loops,
we can not use summations to express the total number of operations. Let us examine the operations for a specific
case, where the number of elements in the array n is 64. When n= 64 Binary Search is called to reduce size to n=32.
When n= 32 Binary Search is called to reduce size to n=16
When n= 16 Binary Search is called to reduce size to n=8
When n= 8 Binary Search is called to reduce size to n=4
When n= 4 Binary Search is called to reduce size to n=2
When n= 2 Binary Search is called to reduce size to n=1
Thus we see that Binary Search function is called 6 times ( 6 elements of the array were examined) for n =64. Note
6
that 64 = 2 . Also we see that the Binary Search function is called 5 times ( 5 elements of the array were examined)
5 k
for n = 32. Note that 32 = 2 . Let us consider a more general case where n is still a power of 2. Let us say n = 2 .
Following the above argument for 64 elements, it is easily seen that after k searches, the while loop is executed k
times and n reduces to size 1. Let us assume that each run of the while loop involves at most 5 operations. Thus
k
total number of operations: 5k. The value of k can be determined from the expression 2 = n. Taking log of both
sides k = log n. Thus total number of operations = 5 log n. We conclude from there that the time complexity of the
Binary search method is O(log n), which is much more efficient than the Linear Search method.
Show that clique problem is an NP complete problem
Clique Problem:-In computer science, the clique problem refers to any of the problems related to
finding particular complete sub graphs in a graph, i.e., sets of elements where each pair of elements is
connected. For example, the maximum clique problem arises in the following real-world setting.
Consider a social network, where the graph’s vertices represent people, and the graph’s edges represent
mutual acquaintance. To find a largest subset of people who all know each other, one can systematically
inspect all subsets, a process that is too time-consuming to be practical for social networks comprising](https://image.slidesharecdn.com/mcs-031-111210014302-phpapp02/85/Mcs-031-1-320.jpg)
![Explanation of binary search algorithm
Suppose we are given a number of integers stored in an array A, and we want to locate a specific target integer K
in this array. If we do not have any information on how the integers are organized in the array, we have to
sequentially examine each element of the array. This is known as linear search and would have a time complexity
of O(n ) in the worst case. However, if the elements of the array are ordered, let us say in ascending order, and we
wish to find out the position of an integer target K in the array, we need not make a sequential search over the
complete array. We can make a faster search using the Binary search method. The basic idea is to start with an
examination of the middle element of the array. This
will lead to 3 possible situations:
If this matches the target K then search can terminate successfully by printing out the index of the element in the
array. On the other hand, if K<A[middle], then search can be limited to elements to the left of A[middle]. All
elements to the right of middle can be ignored. If it turns out that K >A[middle], then further search is limited to
elements to the right of A[middle]. If all elements are exhausted and the target is not found in the array, then the
method returns a special value such as –1. Here is one version of the Binary Search function:
int BinarySearch (int A[ ], int n, int K)
{
int L=0, Mid, R= n-1;
while (L<=R)
{
Mid = (L +R)/2;
if ( K= =A[Mid] )
return Mid;
else if ( K > A[Mid] )
L = Mid + 1;
else
R = Mid – 1 ;
}
return –1 ;
}
Let us now carry out an Analysis of this method to determine its time complexity. Since there are no “for” loops,
we can not use summations to express the total number of operations. Let us examine the operations for a specific
case, where the number of elements in the array n is 64. When n= 64 Binary Search is called to reduce size to n=32.
When n= 32 Binary Search is called to reduce size to n=16
When n= 16 Binary Search is called to reduce size to n=8
When n= 8 Binary Search is called to reduce size to n=4
When n= 4 Binary Search is called to reduce size to n=2
When n= 2 Binary Search is called to reduce size to n=1
Thus we see that Binary Search function is called 6 times ( 6 elements of the array were examined) for n =64. Note
6
that 64 = 2 . Also we see that the Binary Search function is called 5 times ( 5 elements of the array were examined)
5 k
for n = 32. Note that 32 = 2 . Let us consider a more general case where n is still a power of 2. Let us say n = 2 .
Following the above argument for 64 elements, it is easily seen that after k searches, the while loop is executed k
times and n reduces to size 1. Let us assume that each run of the while loop involves at most 5 operations. Thus
k
total number of operations: 5k. The value of k can be determined from the expression 2 = n. Taking log of both
sides k = log n. Thus total number of operations = 5 log n. We conclude from there that the time complexity of the
Binary search method is O(log n), which is much more efficient than the Linear Search method.
Show that clique problem is an NP complete problem
Clique Problem:-In computer science, the clique problem refers to any of the problems related to
finding particular complete sub graphs in a graph, i.e., sets of elements where each pair of elements is
connected. For example, the maximum clique problem arises in the following real-world setting.
Consider a social network, where the graph’s vertices represent people, and the graph’s edges represent
mutual acquaintance. To find a largest subset of people who all know each other, one can systematically
inspect all subsets, a process that is too time-consuming to be practical for social networks comprising](https://image.slidesharecdn.com/mcs-031-111210014302-phpapp02/75/Mcs-031-1-2048.jpg)



![(2) When the matrices are sparse method tailored for sparse matrices are faster.
(3) Strassen's Algorithm is not quite as numerically stable as the native method.
(4) The sub matrices formed at the level of consume space.
Describe white path property of DFS
In a DFS forest of a (directed or undirected) graph G, vertex v is a descendant of vertex u if and only if at time s[u]
(just before u is colored Gray), there is a path from u to v that consists of only White vertices. Proof there are two
directions to prove.
(=⇒ Suppose that v is a descendant of u. So there is a path in the tree from u to v. (Of course this is also a path in
)
G.) All vertices w on this path are also descendants of u. So by the corollary above, they are colored Gray during
the interval [s[u], f[u]]. In other words, at time s[u] they are all White.
(⇐ Suppose that there is a White path from u to v at time s[u]. Let this path be v0 = u, v1, v2, . . . , vk−1, vk = v
=)
To show that v is a descendant of u, we will indeed show that all vi (for 0 ≤ i ≤ k) are descendants of u. (Note that
this path may not be in the DFS tree.) We prove this claim by induction on i.
Base case: i = 0, vi = u, so the claim is obviously true.
Induction step: Suppose that vi is a descendant of u. We show that vi+1 is also a descendant of u. By the corollary
above, this is equivalent to showing that
s[u] < s[vi+1] < f[vi+1] < f[u] i.e., vi+1 is colored Gray during the interval [s[u], f[u]]. Since vi+1 is White at time s[u],
we have s[u] < s[vi+1]. Now, since vi+1 is a neighbor of vi, vi+1 cannot stay White after vi is colored Black. In other
words, s[vi+1] < f[vi]. Apply the induction hypothesis: vi is a descendant of u so s[u] ≤ s[vi] < f[vi] ≤ f[u], we obtain
s[vi+1] < f[u]. Thus s[u] < s[vi+1] < f[vi+1] < f[u] by the Parenthesis Theorem. QED.
In a quick sort algorithm describe the situation when a given pair of elements will be compared to each other &
when they will not compared to each other
Even if pivots aren't chosen randomly, quicksort still requires only O(n log n) time averaged over all possible
permutations of its input. Because this average is simply the sum of the times over all permutations of the input
divided by n factorial, it's equivalent to choosing a random permutation of the input. When we do this, the pivot
choices are essentially random, leading to an algorithm with the same running time as randomized quicksort.
More precisely, the average number of comparisons over all permutations of the input sequence can be estimated
accurately by solving the recurrence relation:
Here, n − 1 is the number of comparisons the partition uses. Since the pivot is equally likely to fall anywhere in the
sorted list order, the sum is averaging over all possible splits.
This means that, on average, quicksort performs only about 39% worse than in its best case. In this sense it is
closer to the best case than the worst case. Also note that a comparison sort cannot use less
than log 2(n!) comparisons on average to sort n items and in case of large n, Stirling's
approximation yields , so quicksort is not much worse than an ideal
comparison sort. This fast average runtime is another reason for quicksort's practical dominance over other
sorting algorithms.
Among BDS & DFS which technique is used in ignorer traversal a Binary tree & how?
The BFS can be used in order traversal of a Binary tree. BFS is a little like hill climbing, in that it uses an evaluation
function & always chooses the next node to be that with the best score. However it is exhaustive in that it should
eventually try all possible paths. The BFS algorithm was developed to simulate the various client based spiders
developed in earlier studies & were used as benchmark for comparison. The genetic algorithm was adopted to
enhance the global optimal search capability of existing internet spider.
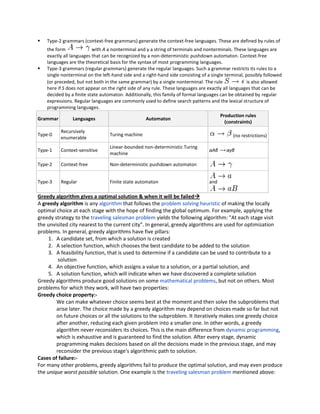
Define pumping lemma for context free grammar
In the theory of formal languages in computability theory, a pumping lemma or pumping argument states that, for
a particular language to be a member of a language class, any sufficiently long string in the language contains a
section, or sections, that can be removed, or repeated any number of times, with the resulting string remaining in
that language. The proofs of these lemmas typically require counting arguments such as the pigeonhole principle.
The two most important examples are the pumping lemma for regular languages and the pumping lemma for
context-free languages. Ogden's lemma is a second, stronger pumping lemma for context-free languages](https://image.slidesharecdn.com/mcs-031-111210014302-phpapp02/85/Mcs-031-6-320.jpg)

































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



