Downloaded 49 times












![Pig examples
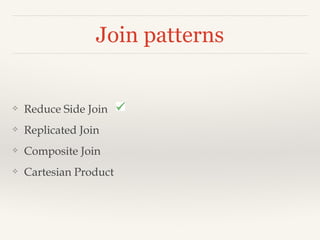
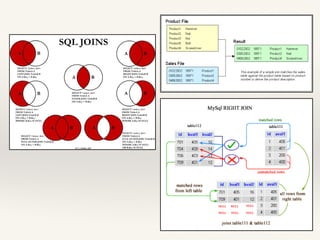
- - Inner Join:
A = JOIN comments BY userID, users BY userID;
- - Outer Join:
A = JOIN comments BY userID [LEFT | RIFGT| FULL] OUTER , users BY userID;
- - Binning:
SPLIT data INTO
eights IF col1 == 8,
bigs IF col1 > 8,
smalls IF (col1 < 8 and col1 > 0 );
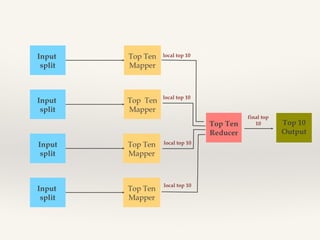
- - Top Ten:
B = ORDER A BY col4 DESC’
C = limit B 10;
- - Filtering:
b = FILTER a BY value < 3;](https://image.slidesharecdn.com/mapreducedesignpatterns-140303100944-phpapp02/85/MapReduce-Design-Patterns-25-320.jpg)

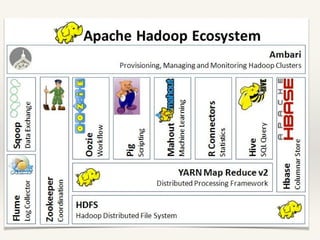
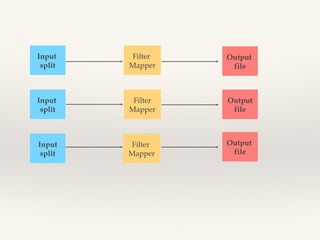
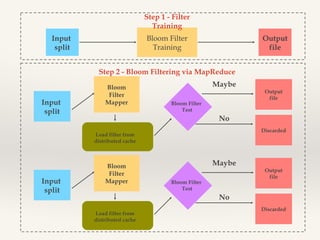
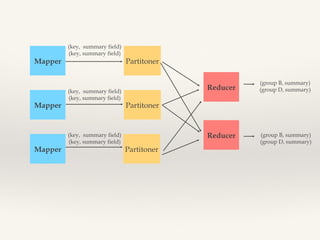
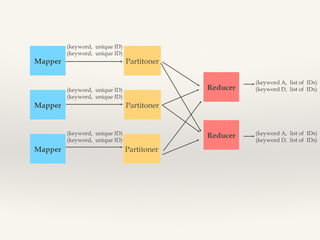
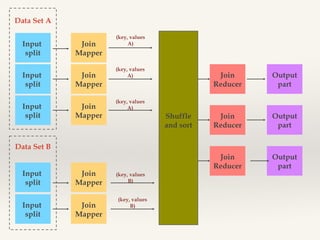
This document discusses MapReduce design patterns. It describes the core MapReduce components including the mapper, reducer, and shuffle and sort. It then outlines several common MapReduce patterns such as filtering, summarization, joins, data organization, and input/output. Specific filtering patterns like bloom filtering and top-N are explained in more detail.






















































