Downloaded 10 times



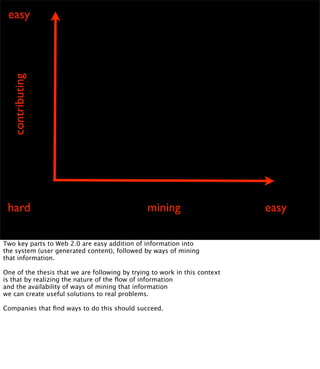
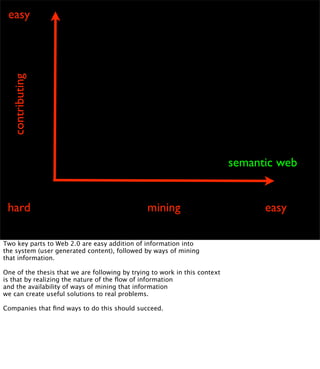
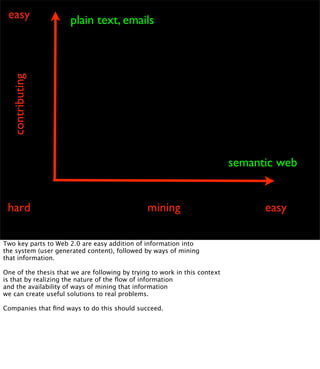
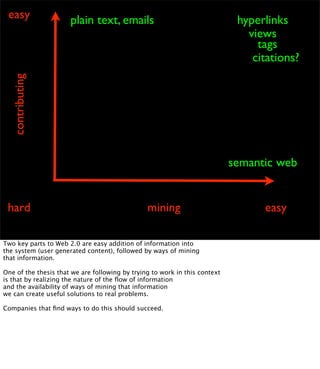
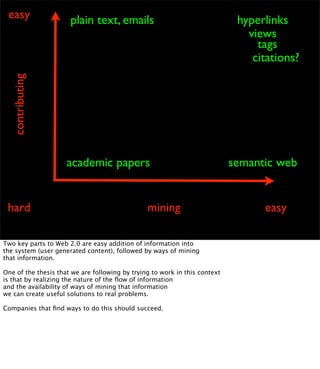
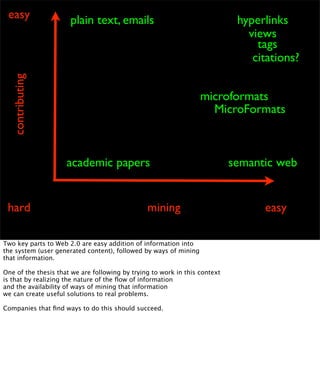





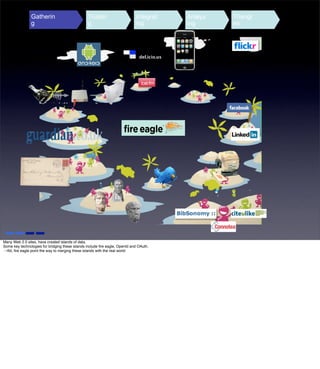


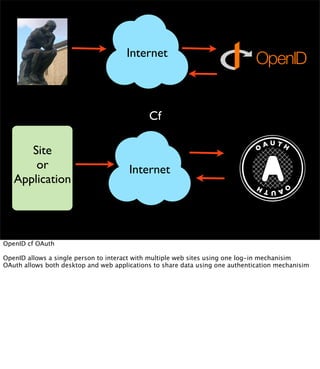


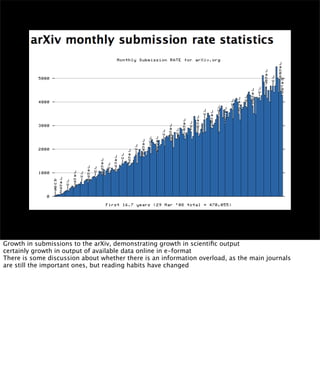








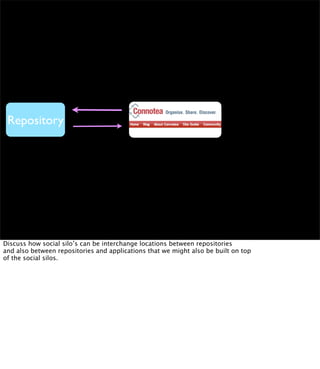
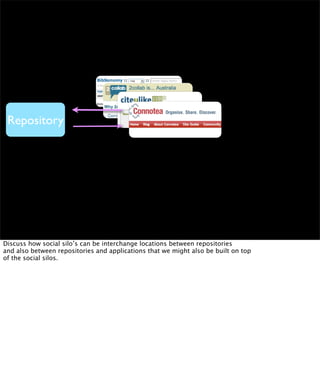
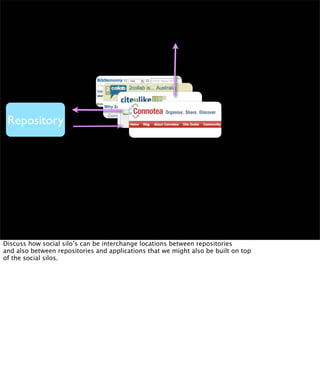
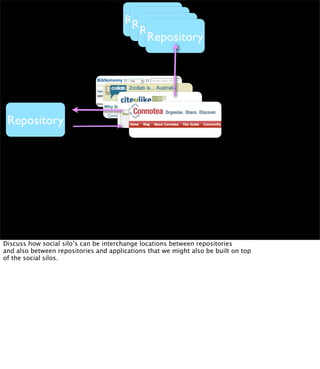
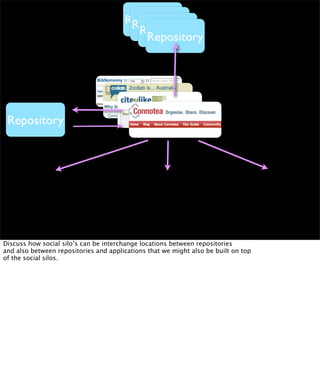
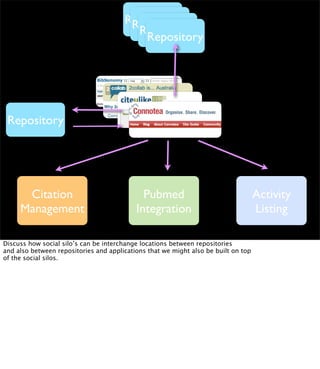
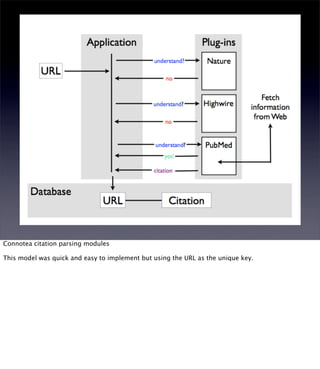

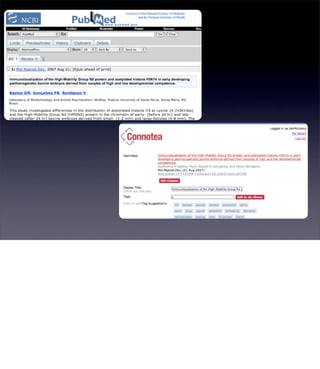
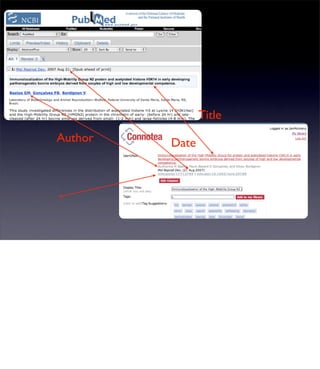
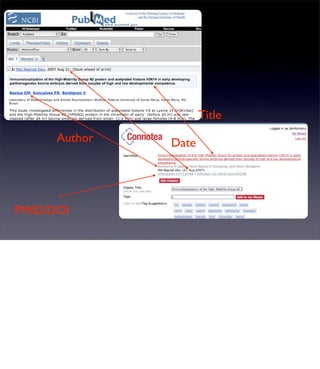
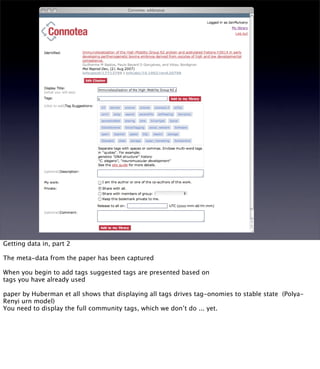
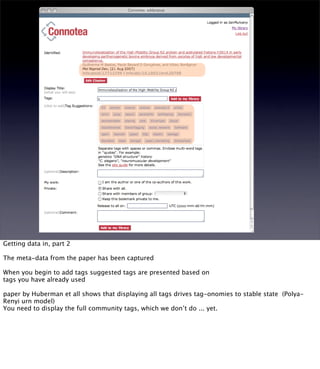
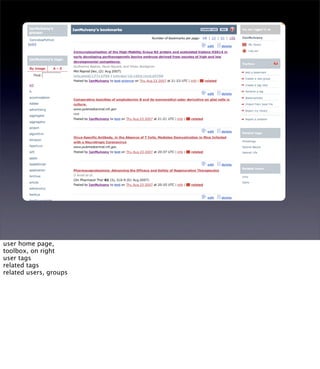
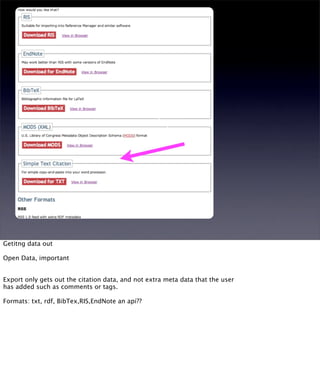
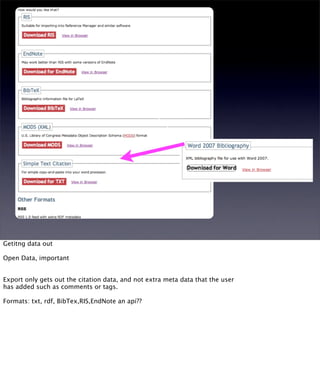



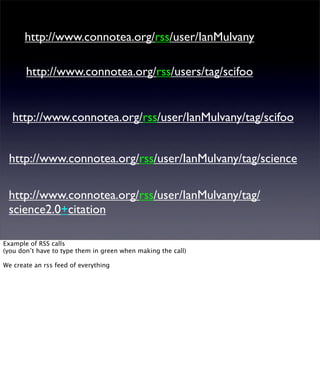
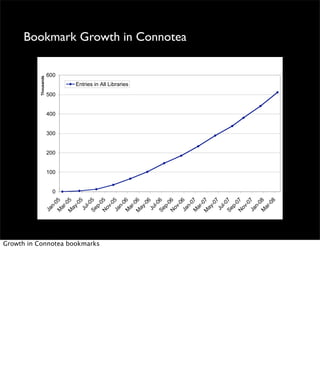


The document discusses the evolution of web technologies from Web 1.0 to Web 2.0, emphasizing the shift from centrally controlled information (e.g., Britannica) to user-generated content (e.g., Wikipedia) and the importance of easy information contribution and mining. It highlights the role of various tools and technologies that facilitate data sharing and integration across platforms, as well as the significance of semantic web technologies for understanding and analyzing information flows. The discourse also touches upon the potential for creating useful solutions to real problems by leveraging user-generated content and innovative data mining strategies.










































































