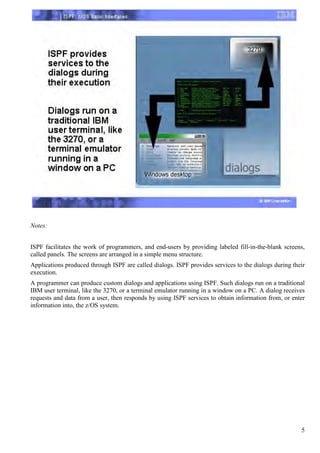
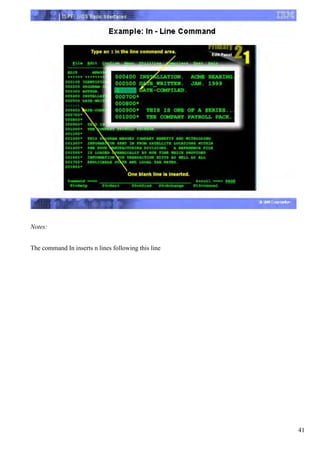
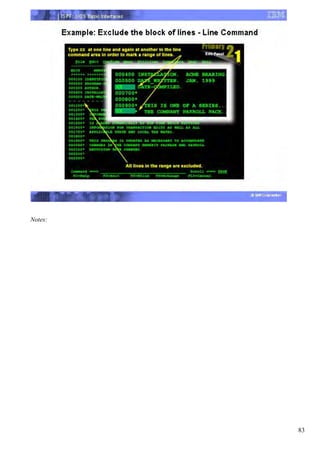
The document provides an overview of the Interactive System Productivity Facility (ISPF) and the Time Sharing Option (TSO) mainframe operating system. ISPF is a development toolset for z/OS that facilitates programming and end-user work by providing labeled screens and services to create dialog applications. TSO is IBM's mainframe time-sharing system, and ISPF can be seen as an extension to TSO that provides additional interactive processing capabilities. Upon completing the course, users will understand how to navigate ISPF, work with data sets, submit and monitor background jobs, and more.