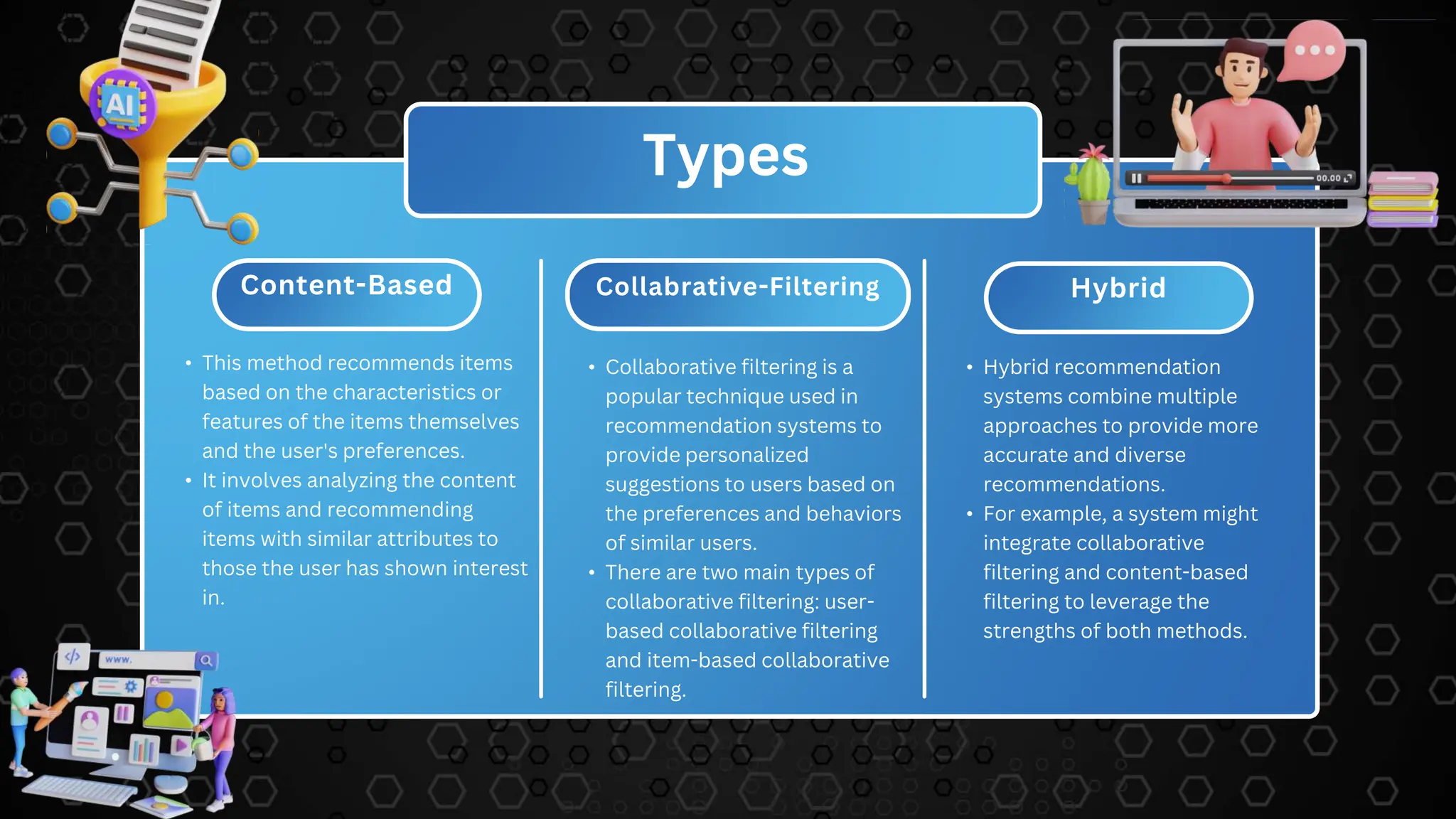
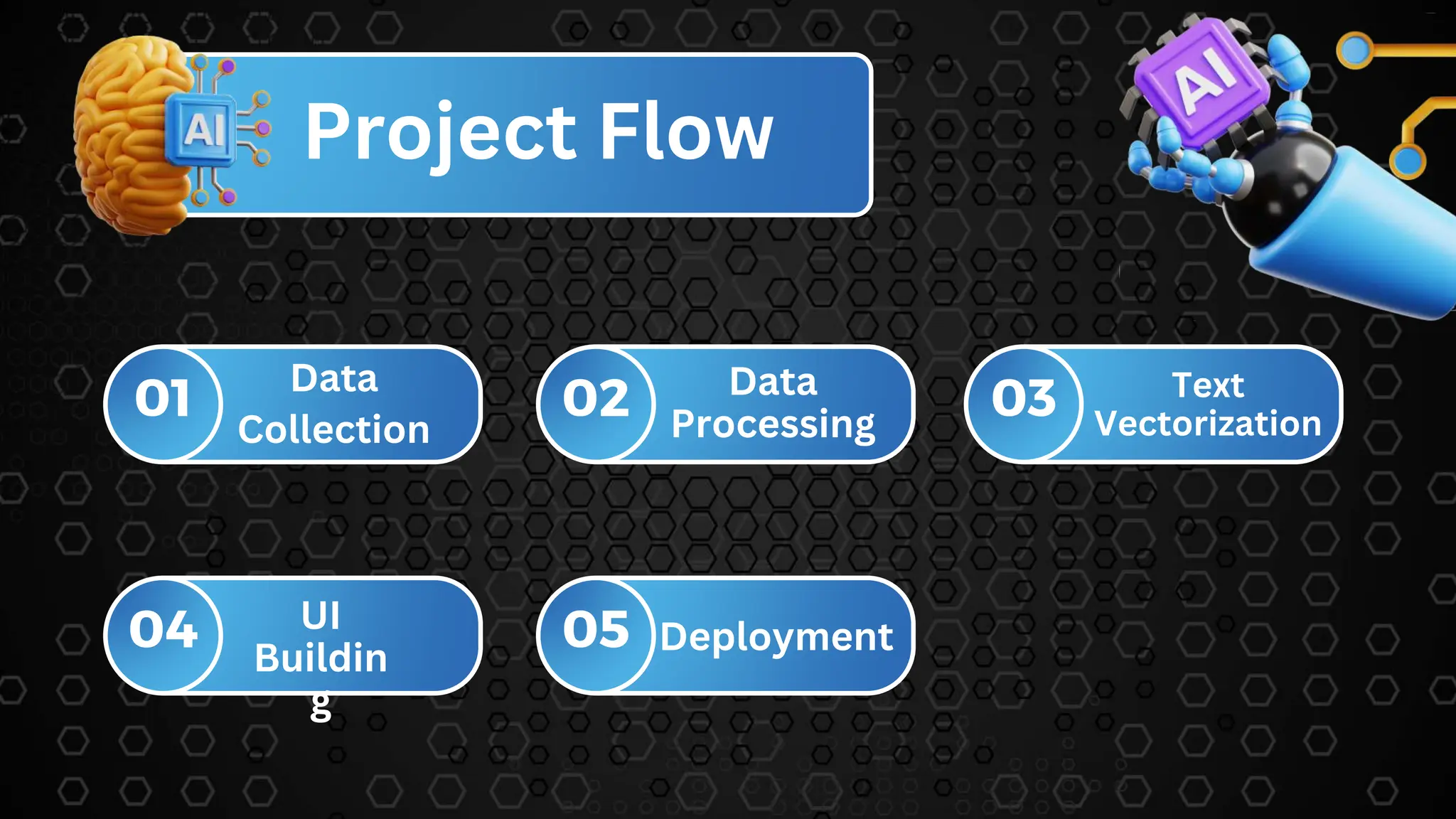
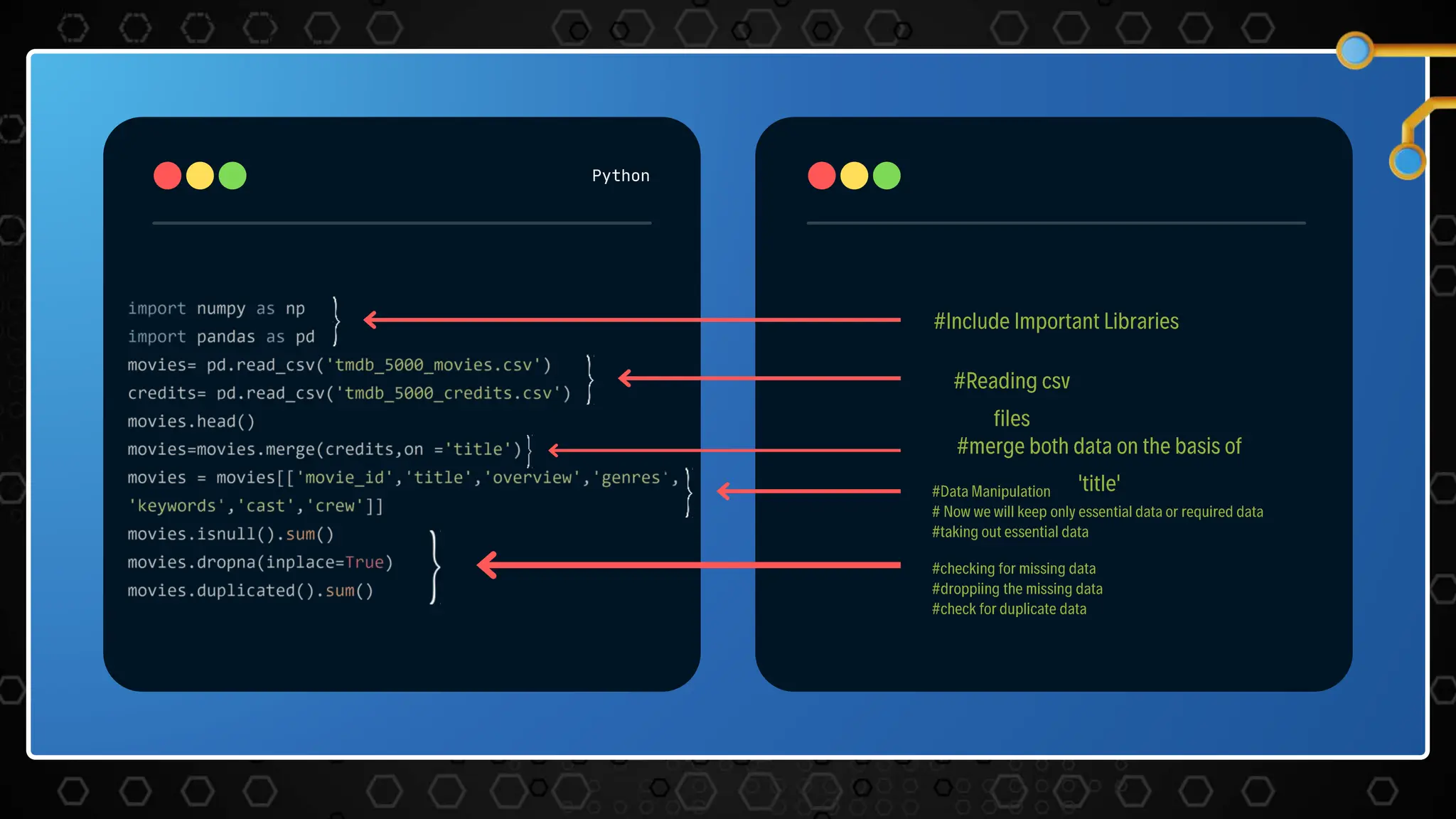
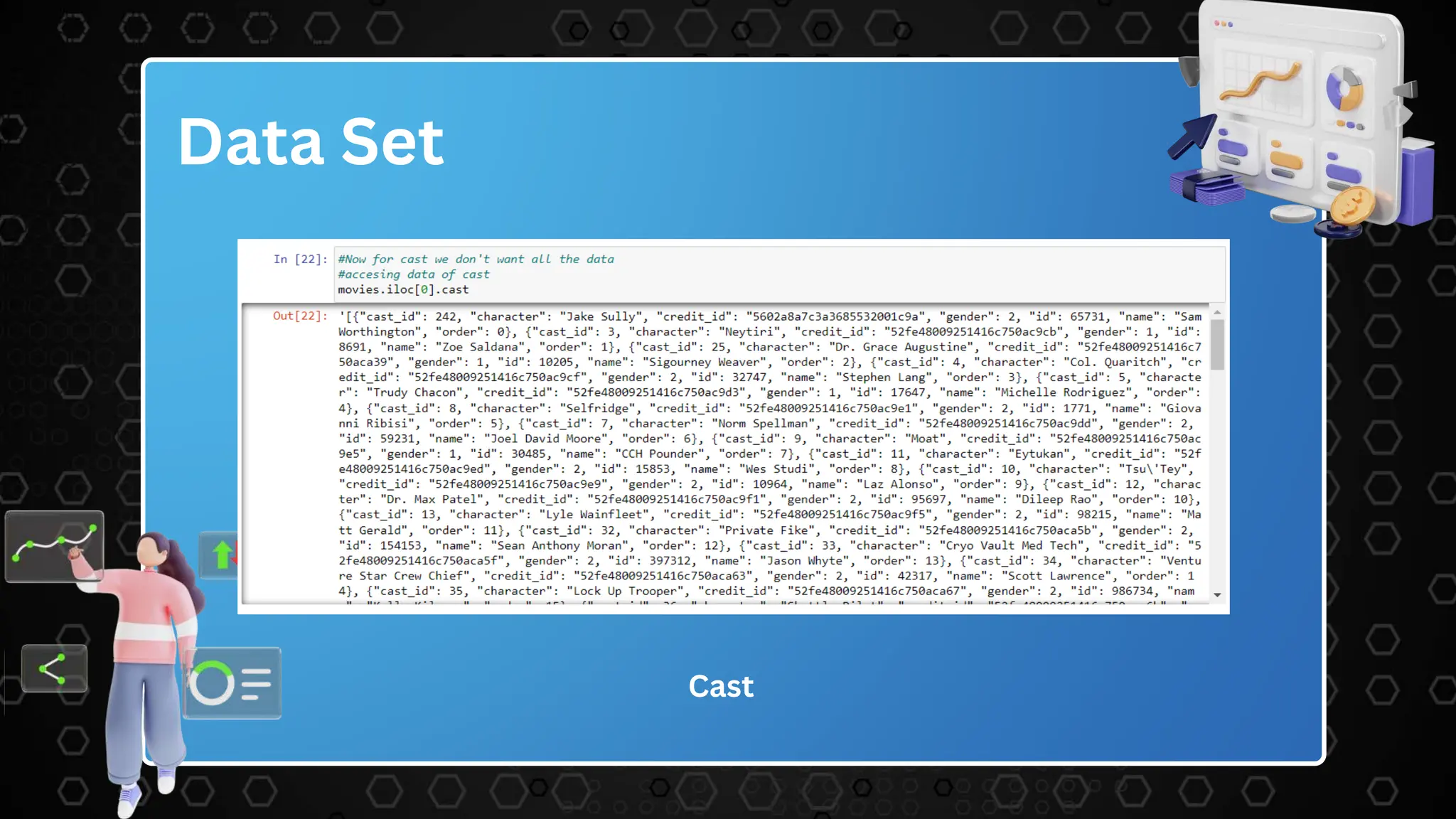
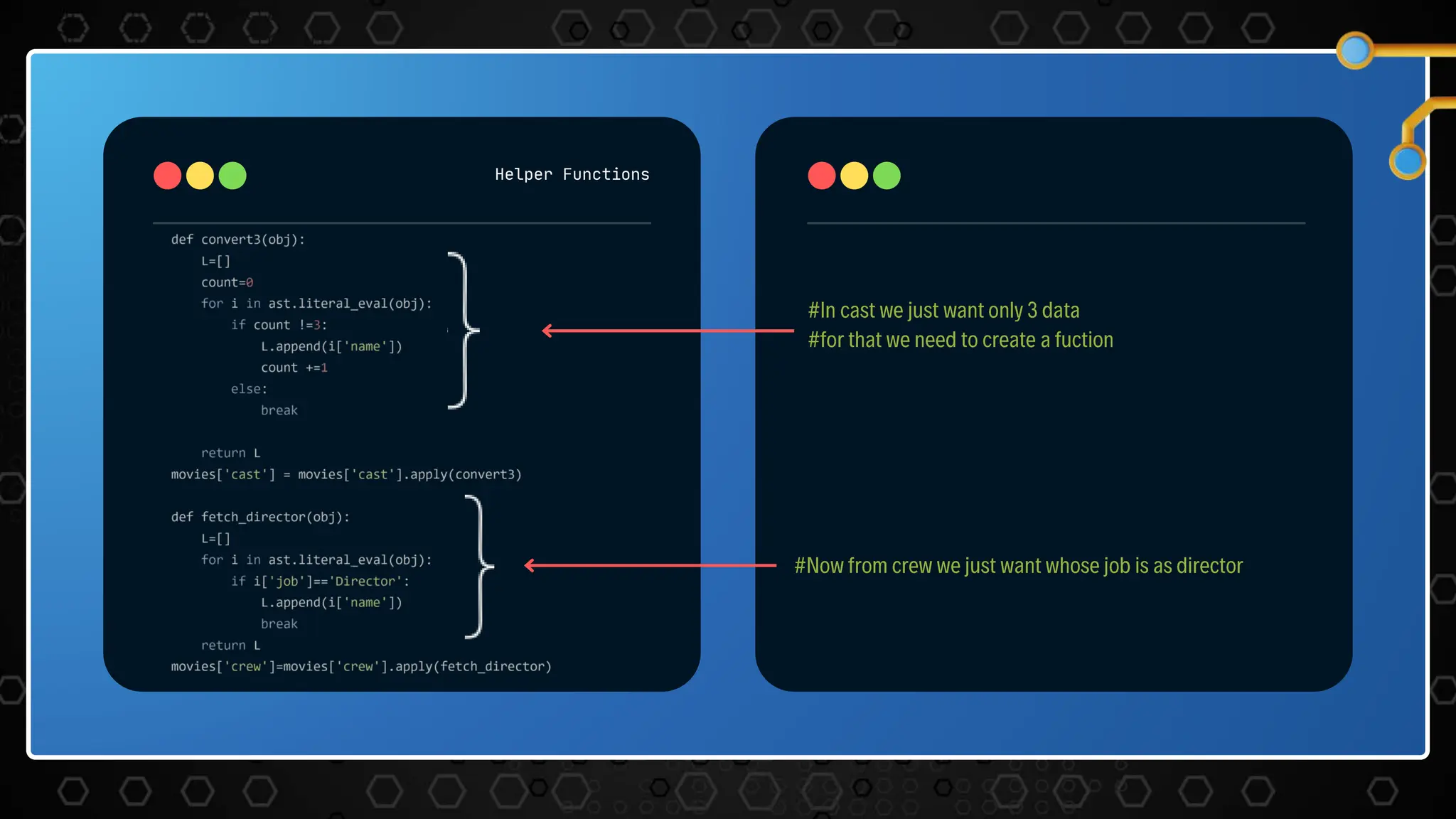
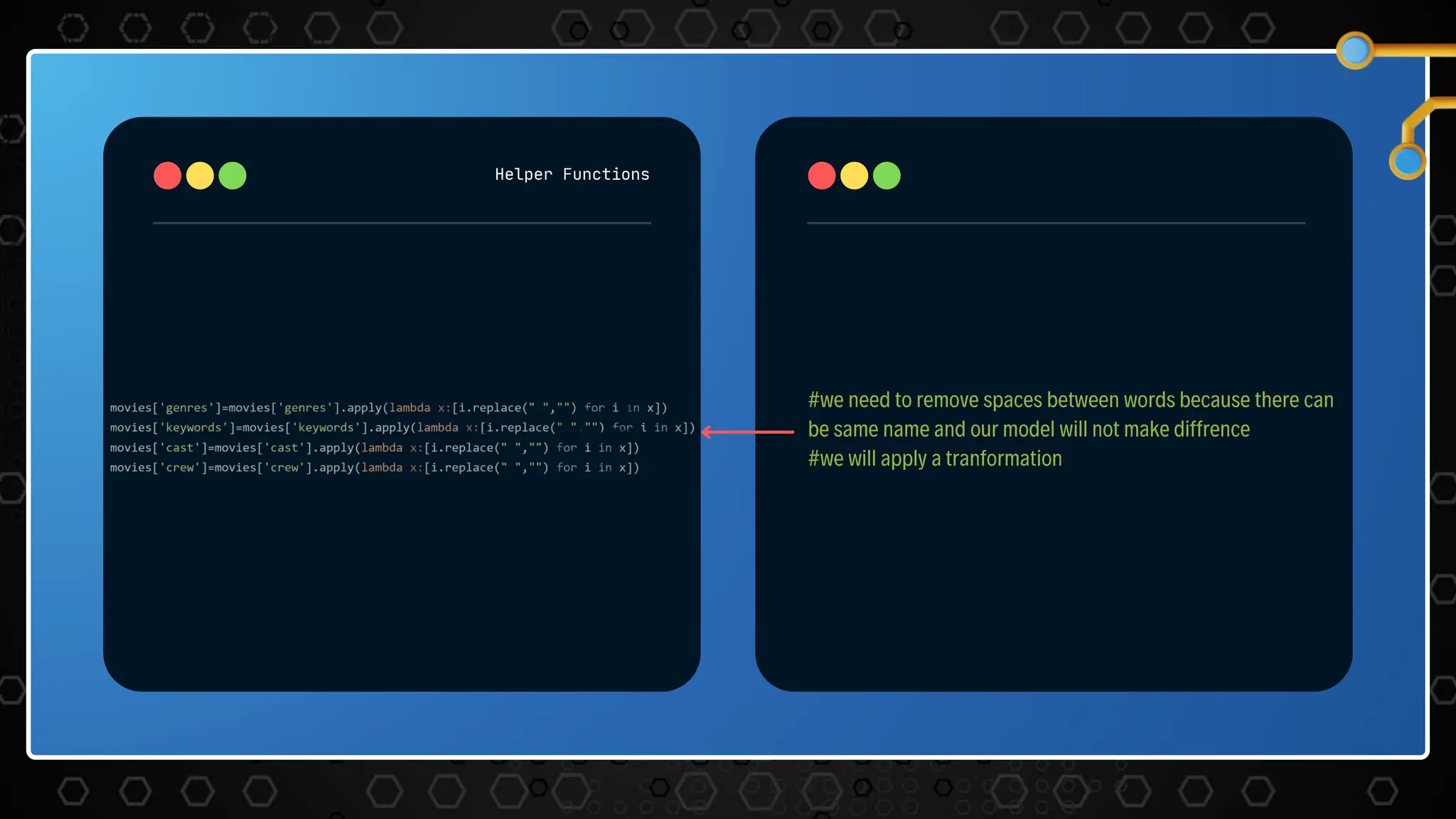
The document describes a movie recommendation system project that uses machine learning. It includes sections on the problem statement, recommendation systems, the project workflow including data collection, processing, text vectorization, building a user interface, accuracy metrics, and results. The goal is to recommend movies to users based on their preferences using collaborative filtering techniques.














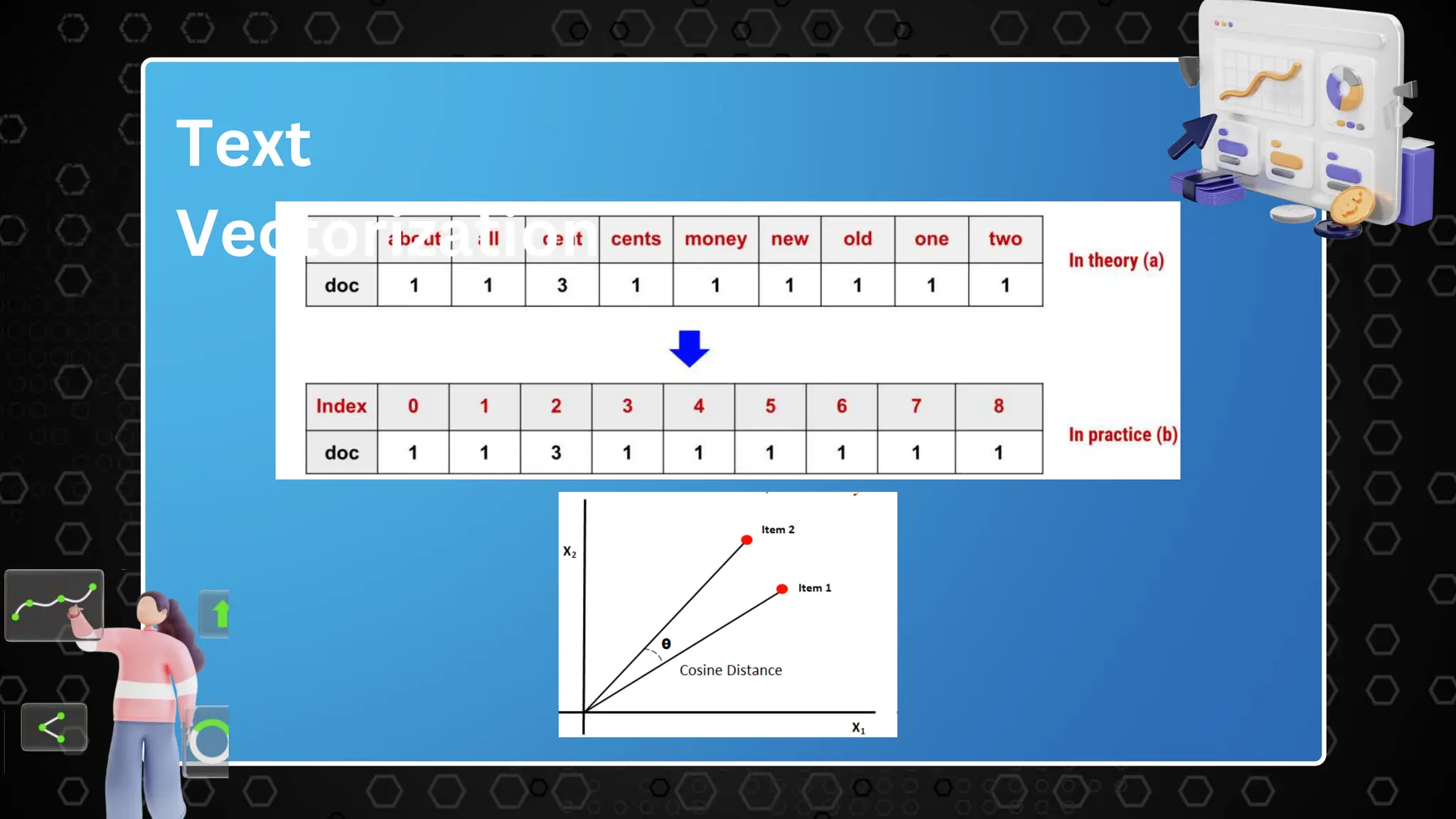

![Example:
• Consider two documents: "The cat in the hat" and "The quick brown
fox."
• Vocabulary: ["The", "cat", "in", "hat", "quick", "brown", "fox"] (unique
words across both documents).
• Document Vectors:
⚬ "The cat in the hat": [1, 1, 1, 1, 0, 0, 0]
⚬ "The quick brown fox": [1, 0, 0, 0, 1, 1, 1]](https://image.slidesharecdn.com/mlppt-240205092635-c66db5ce/75/Machine_learning_presentation_on_movie_recomendation_system-pptx-23-2048.jpg)