STUDENT NAME :SRIRAGAVI J
REGISTER NUMBER : 422323106022
INSTITUTION : TCET - VANDAVASI
DEPARTMENT : ECE – II ND YEAR
DATE OF SUBMISSION : 15-05-2025
GITHUB REPOSITORY LINK:
https://github.com/boo253-hue/Personalized-Movie-Recommendation-
System-Using-Machine-Learning.git
Problem Statement
● Aim:Build a movie recommendation system based on ‘MovieLens’
dataset.
● We wish to integrate the aspects of personalization of user with
the overall features of movie such as genre, popularity etc.
4.
ABSTRACT
Recommendation systems arebecoming increasingly important in
today’s hectic world. People are always in the lookout for
products/services that are best suited for them. Therefore, the
recommendation systems are important as they help them make the
right choices, without having to expend their cognitive resources.
here, I will build a Movie Recommendation System using collaborative
filtering by implementing the K-Nearest Neighbors algorithm. I will also
predict the rating of the given movie based on its neighbors and
compare it with the actual rating.
5.
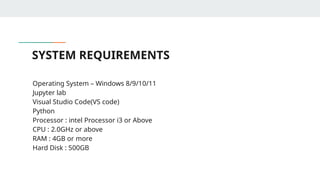
SYSTEM REQUIREMENTS
• OperatingSystem – Windows 8/9/10/11
• Jupyter lab
• Visual Studio Code(VS code)
• Python
• Processor : intel Processor i3 or Above
• CPU : 2.0GHz or above
• RAM : 4GB or more
• Hard Disk : 500GB
6.
PROJECTS OBJECTIVES
● Thisproject tackles the critical challenge of credit card fraud detection and prevention.
● Our goal is to develop effective methods using machine learning, anomaly detection, and deep
learning to identify fraudulent activities.
● This widespread criminal activity leads to financial losses and identity theft for consumers, while
businesses face chargebacks and reputational damage. Secure financial transactions are the
bedrock of trust in today's digital economy.
7.
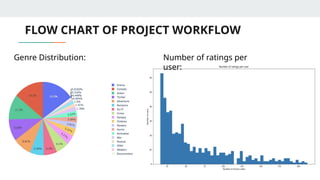
FLOW CHART OFPROJECT WORKFLOW
Genre Distribution: Number of ratings per
user:
8.
DATASET DESCRIPTION
● MovieLensreview dataset (ml-latest-small)
○ Ratings: 100k
○ Movies: 9k
○ Users: 600
● Integrated the dataset with IMDB and TMDB data set publically available.
● Split the dataset into 80% training and 20% testing based on the User ID.
9.
Models
1. Popularity basedmodel
2. Content based model
3. Collaborative Filtering
4. Matrix Factorization method
5. Combined model ( SVD + CF)
6. Hybrid model
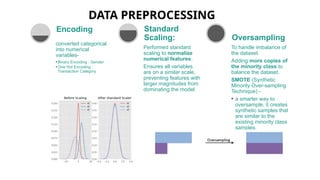
DATA PREPROCESSING
converted categorical
intonumerical
variables-
•Binary Encoding : Gender
•One Hot Encoding :
Transaction Category
Encoding
Performed standard
scaling to normalize
numerical features.
Ensures all variables
are on a similar scale,
preventing features with
larger magnitudes from
dominating the model.
Standard
Scaling:
To handle imbalance of
the dataset.
Adding more copies of
the minority class to
balance the dataset.
SMOTE (Synthetic
Minority Over-sampling
Technique) -
• a smarter way to
oversample, it creates
synthetic samples that
are similar to the
existing minority class
samples.
Oversampling
12.
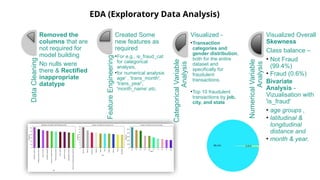
EDA (Exploratory DataAnalysis)
Data
CleaningRemoved the
columns that are
not required for
model building
No nulls were
there & Rectified
inappropriate
datatype
Feature
Engineering
Created Some
new features as
required
•For e.g., is_fraud_cat
for categorical
analysis,
•for numerical analysis
age' , 'trans_month',
'trans_year',
'month_name’,etc.
Categorical
Variable
Analysis
Visualized -
•Transaction
categories and
gender distribution,
both for the entire
dataset and
specifically for
fraudulent
transactions.
•Top 10 fraudulent
transactions by job,
city, and state
Numerical
Variable
Analysis
Visualized Overall
Skewness
Class balance –
• Not Fraud
(99.4%)
• Fraud (0.6%)
Bivariate
Analysis -
Vizualisation with
'is_fraud'
• age groups ,
• latitudinal &
longitudinal
distance and
• month & year.
13.
FEATURE ENGINEERING
1. Userprofile based on item profiles
a. Genre
b. Year of release of movie
2. Movie - Movie similarity
14.
#to read csvfile
#to print all details of 10 movies
#to calculate statiscal data like count, mean,std,
#to print all columns and nonull and data types
#returns the number of missing values in the dataset
import pandas as pd
movies = pd.read_csv('dataset.csv’)
movies.head(10)
movies.describe()
movies.info()
movies.isnull().sum()
movies.columns
#it will combine the genre and overview column
movies=movies[['id', 'title', 'overview', 'genre']]
movies
movies['tags'] = movies['overview']+movies['genre’]
movies
new_data = movies.drop(columns=['overview', 'genre'])
new_data
MODEL BUILDING
15.
from sklearn.feature_extraction.text importCountVectorizer #method to convert text to numerical data.
cv=CountVectorizer(max_features=10000, stop_words='english')
cv
vector=cv.fit_transform(new_data['tags'].values.astype('U')).toarray()
vector.shape
from sklearn.metrics.pairwise import cosine_similarity
similarity=cosine_similarity(vector)
similarity
new_data[new_data['title']=="The Godfather"].index[0]
distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]:
print(new_data.iloc[i[0]].title)
16.
def recommend(movies):
index=new_data[new_data['title']==movies].index[0]
distance =sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]: #to print only top 5 movies
print(new_data.iloc[i[0]].title)
import pickle
pickle.dump(new_data, open('movies_list.pkl',
'wb')) pickle.dump(similarity,
open('similarity.pkl', 'wb'))
pickle.load(open('movies_list.pkl', 'rb'))
import streamlit.components.v1 ascomponents
imageCarouselComponent = components.declare_component("image-carousel-
component", path="frontend/public")
#imageCarouselComponent(imageUrls=imageUrls, height=200)
selectvalue=st.selectbox("Select movie from dropdown", movies_list)
def recommend(movie):
index=movies[movies['title']==movie].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True,
key=lambda vector:vector[1])
recommend_movie
=[]
recommend_poster=[]
for i in distance[1:6]:
movies_id=movies.iloc[i[0]].id
recommend_movie.append(movies.iloc[i[0]].title)
recommend_poster.append(fetch_poster(movies_id))
return recommend_movie, recommend_poster
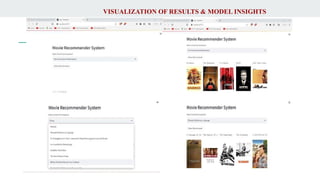
if st.button("Show Recommend"):
movie_name, movie_poster = recommend(selectvalue)
col1,col2,col3,col4,col5=st.columns(5)
with col1:
st.text(movie_name[0])
st.image(movie_poster[0])
with col2:
st.text(movie_name[1
])
st.image(movie_poster[1])
with col3:
st.text(movie_name[2
])
st.image(movie_poster[2])
with col4:
st.text(movie_name[3])
st.image(movie_poster[3])
with col5:
st.text(movie_name[4])
st.image(movie_poster[4])
20.
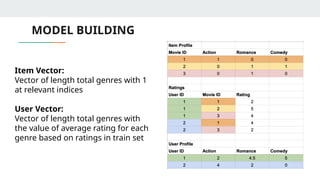
MODEL BUILDING
Item Vector:
Vectorof length total genres with 1
at relevant indices
User Vector:
Vector of length total genres with
the value of average rating for each
genre based on ratings in train set
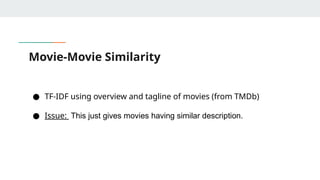
Movie-Movie Similarity
● TF-IDFusing overview and tagline of movies (from TMDb)
● Issue: This just gives movies having similar description.
23.
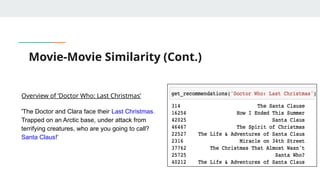
Movie-Movie Similarity (Cont.)
Overviewof ‘Doctor Who: Last Christmas’
'The Doctor and Clara face their Last Christmas.
Trapped on an Arctic base, under attack from
terrifying creatures, who are you going to call?
Santa Claus!'
24.
● Adding thegenre two times to give more weightage
● Changing TF-IDF to Count Vector
○ TF-IDF gives lesser weight to frequently occurring terms across
documents
Improvement
25.
Movie 1: '20Years After'
“In the middle of nowhere, 20 years after an apocalyptic
terrorist event that obliterated the face of the world!”
Genre: ['Drama', 'Fantasy', 'Sci-Fi']
Movie 2: '4:44 Last Day on Earth'
Overview:
'A look at how a painter and a successful actor spend their
last day together before the world comes to an end.'
Genre: ['Drama', 'Fantasy', 'Sci-Fi']
Doctor Who:
- 'The Doctor and Clara face their Last
Christmas. Trapped on an Arctic base,
under attack from terrifying creatures,
who are you going to call? Santa Claus!'
- ['Adventure', 'Drama', 'Fantasy', 'Sci-Fi']
26.
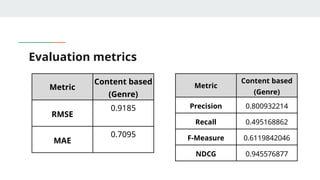
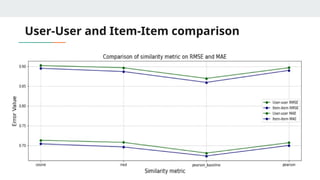
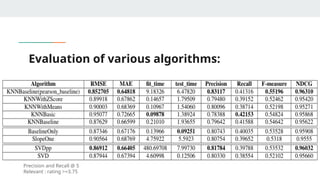
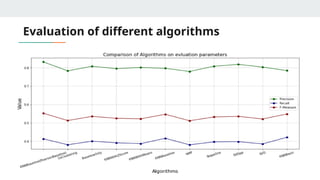
MODEL EVALUATION
● KNN(k- nearest neighbors) algorithm using Surprise library
● Variations of KNN based approaches:
○ KNNBasic
○ KNNwithMeans
○ KNNWithZScore
○ KNNBaseline : integrates the baseline estimate ratings
● Similarity metrics:
○ Cosine similarity
○ Mean square difference based similarity
○ Pearson coefficient (mean-centered cosine similarity)
○ Pearson Baseline (uses global baselines for centering instead of means)
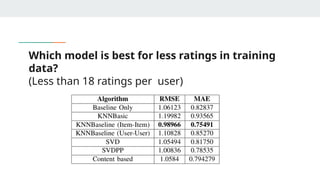
Which model isbest for less ratings in training
data?
(Less than 18 ratings per user)
33.
Combined Model
● MatrixFactorization + CF
● Weighted linear combination of prediction ratings
● Combined:
○ KNNBaseline (with pearson baseline similarity)
○ SVDpp
○ SVD
○ BaselineOnly
34.
SOURCE CODE
● UserId = 1
● User top genre list from User vector:
○ [‘Film-Noir’, ‘Animation’, ‘Musical’]:
35.
• Provides relevantcontent to user.
• It saves time and money.
• It increases customer engagement.
• Specially designed for binge watchers
FEATURE SCOPE
36.
TEAMS MEMBERS ANDCONTRIBUTIONS
BOOPATHI K : PROBLEM STATEMENT & ABSTRACT ,OBJECTIVE ,
FLOWCHART OF THE PROJECT WORKFLOW , DEPLOYMENT
SRIRAGAVI J : DATA SET DESCRIPTION & PREPROCESSING , EDA , MODEL
BUILDING, SOURCE CODE
VENNILAVAN K : MODEL BUILDING & FUTURE SCOPE, SYSTEM REQUIEMENTS









![#to read csv file
#to print all details of 10 movies
#to calculate statiscal data like count, mean,std,
#to print all columns and nonull and data types
#returns the number of missing values in the dataset
import pandas as pd
movies = pd.read_csv('dataset.csv’)
movies.head(10)
movies.describe()
movies.info()
movies.isnull().sum()
movies.columns
#it will combine the genre and overview column
movies=movies[['id', 'title', 'overview', 'genre']]
movies
movies['tags'] = movies['overview']+movies['genre’]
movies
new_data = movies.drop(columns=['overview', 'genre'])
new_data
MODEL BUILDING](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-14-320.jpg)
![from sklearn.feature_extraction.text import CountVectorizer #method to convert text to numerical data.
cv=CountVectorizer(max_features=10000, stop_words='english')
cv
vector=cv.fit_transform(new_data['tags'].values.astype('U')).toarray()
vector.shape
from sklearn.metrics.pairwise import cosine_similarity
similarity=cosine_similarity(vector)
similarity
new_data[new_data['title']=="The Godfather"].index[0]
distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]:
print(new_data.iloc[i[0]].title)](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-15-320.jpg)
![def recommend(movies):
index=new_data[new_data['title']==movies].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]: #to print only top 5 movies
print(new_data.iloc[i[0]].title)
import pickle
pickle.dump(new_data, open('movies_list.pkl',
'wb')) pickle.dump(similarity,
open('similarity.pkl', 'wb'))
pickle.load(open('movies_list.pkl', 'rb'))](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-16-320.jpg)
![import streamlit as st
import pickle
import requests
def fetch_poster(movie_id):
url = "https://api.themoviedb.org/3/movie/{}?api_key=43c2c7148a22f65595a5dcc10a9d6c8b".format(movie_id)
data=requests.get(url)
data=data.json()
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/"+poster_path
return full_path
movies = pickle.load(open("movies_list.pkl", 'rb'))
similarity = pickle.load(open("similarity.pkl", 'rb'))
movies_list=movies['title'].values
st.header("Movie Recommender System")](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-17-320.jpg)
![import streamlit.components.v1 as components
imageCarouselComponent = components.declare_component("image-carousel-
component", path="frontend/public")
#imageCarouselComponent(imageUrls=imageUrls, height=200)
selectvalue=st.selectbox("Select movie from dropdown", movies_list)
def recommend(movie):
index=movies[movies['title']==movie].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True,
key=lambda vector:vector[1])
recommend_movie
=[]
recommend_poster=[]
for i in distance[1:6]:
movies_id=movies.iloc[i[0]].id
recommend_movie.append(movies.iloc[i[0]].title)
recommend_poster.append(fetch_poster(movies_id))
return recommend_movie, recommend_poster
if st.button("Show Recommend"):
movie_name, movie_poster = recommend(selectvalue)
col1,col2,col3,col4,col5=st.columns(5)
with col1:
st.text(movie_name[0])
st.image(movie_poster[0])
with col2:
st.text(movie_name[1
])
st.image(movie_poster[1])
with col3:
st.text(movie_name[2
])
st.image(movie_poster[2])
with col4:
st.text(movie_name[3])
st.image(movie_poster[3])
with col5:
st.text(movie_name[4])
st.image(movie_poster[4])](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-19-320.jpg)

![Movie 1: '20 Years After'
“In the middle of nowhere, 20 years after an apocalyptic
terrorist event that obliterated the face of the world!”
Genre: ['Drama', 'Fantasy', 'Sci-Fi']
Movie 2: '4:44 Last Day on Earth'
Overview:
'A look at how a painter and a successful actor spend their
last day together before the world comes to an end.'
Genre: ['Drama', 'Fantasy', 'Sci-Fi']
Doctor Who:
- 'The Doctor and Clara face their Last
Christmas. Trapped on an Arctic base,
under attack from terrifying creatures,
who are you going to call? Santa Claus!'
- ['Adventure', 'Drama', 'Fantasy', 'Sci-Fi']](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-25-320.jpg)




![SOURCE CODE
● User Id = 1
● User top genre list from User vector:
○ [‘Film-Noir’, ‘Animation’, ‘Musical’]:](https://image.slidesharecdn.com/sriragaviphase3-250526053810-6081bd4c/85/SRIRAGAVI-PHASE-3phasephasephasephh-pptx-34-320.jpg)



























































