Download as PDF, PPTX




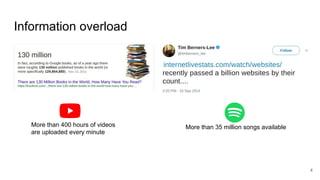


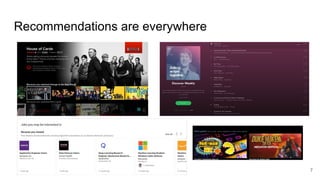

![Value of recommendation
“Our recommender system is used on most screens of the Netflix product beyond
the homepage, and in total influences choice for about 80% of hours
streamed at Netflix. The remaining 20% comes from search [...]”
Carlos A Gomez-Uribe and Neil Hunt. 2016. The netflix recommender system: Algorithms, business value, and innovation.
ACM Transactions on Management Information Systems (TMIS) 6, 4 (2016), 13.
9](https://image.slidesharecdn.com/macina-product-embeddings-180313140950/85/Real-time-personalized-recommendations-using-product-embeddings-9-320.jpg)





![Text preprocessing
● Stopwords removal
● Part-of-speech (POS) tagging
17
from nltk.corpus import stopwords
review = "Great local atmosphere, tasty tapas and great selection of beers."
words = review.lower().split(" ")
print([word for word in words if word not in (stopwords.words('english'))])
>> ['great', 'local', 'atmosphere,', 'tasty', 'tapas', 'great', 'selection', 'beers.']
for sent in nltk.sent_tokenize(review):
print(list(nltk.pos_tag(nltk.word_tokenize(sent))))
>> [('Great', 'NNP'), ('local', 'JJ'), ('atmosphere', 'NN'), (',', ','), ('tasty',
'JJ'), ('tapas', 'NN'), ('and', 'CC'), ('great', 'JJ'), ('selection', 'NN'), ('of',
'IN'), ('beers', 'NNS')]](https://image.slidesharecdn.com/macina-product-embeddings-180313140950/85/Real-time-personalized-recommendations-using-product-embeddings-17-320.jpg)




![Word2vec with gensim
24
print(reviews[:3])
>>> [
['this', 'place', 'is', 'horrible'],
['i', 'was', 'impressed', 'there'],
['i', 'decided', 'to', 'try', 'it', 'turned', 'out', 'is' , 'cheap', 'eat']
]
from gensim.models import Word2Vec
word2vec_model = Word2Vec(reviews, sg=1, iter=10, size=100, window=5, min_count=2,
workers=4)
word2vec_model.wv['impressed']
>> array([ 0.2790776 , -0.3456704 , 0.23330563, ..., -0.11152197],
dtype=float32)](https://image.slidesharecdn.com/macina-product-embeddings-180313140950/85/Real-time-personalized-recommendations-using-product-embeddings-24-320.jpg)





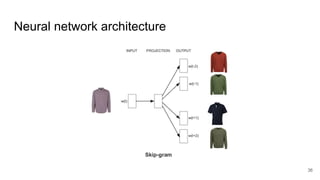
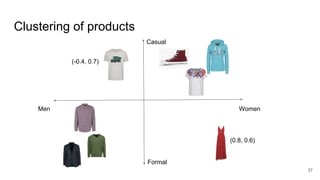
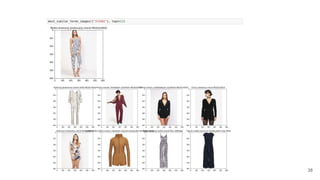




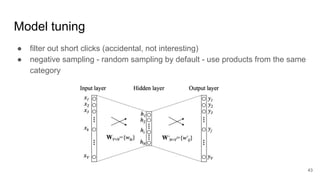
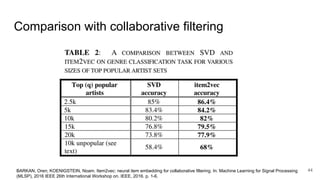



The document presents an overview of recommender systems, focusing on techniques such as collaborative filtering and content-based recommendations. It discusses challenges such as user login states and the dynamics of buying intent, emphasizing the importance and impact of recommendations, as demonstrated by Netflix and YouTube data. Additionally, it explores product embeddings and their use in enhancing personalization in recommendations through numeric vector representations.









































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





