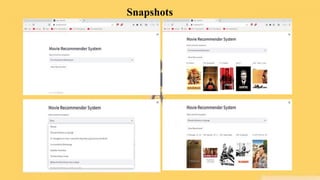
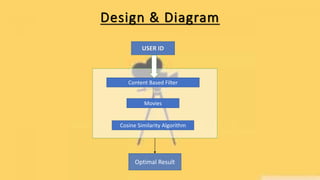
This document presents a project on building a movie recommendation system. It discusses the problem statement, objectives, requirements, design, coding approach, and results. The goal is to develop a recommendation system to help users find good movies to watch by using a dataset on movies and implementing content-based filtering and cosine similarity. The system was built using Python libraries and deployed using Streamlit for a web-based interface. It allows users to select a movie and receives top 5 recommended movies based on similarity.








![C OD IN G PA RT
( M a in.ipynb )
import pandas as pd
movies = pd.read_csv('dataset.csv’) #to read csv file
movies.head(10) #to print all details of 10 movies
movies.describe() #to calculate statiscal data like count, mean,std,
movies.info() #to print all columns and nonull and data types
movies.isnull().sum() #returns the number of missing values in the dataset
movies.columns
movies=movies[['id', 'title', 'overview', 'genre']]
movies
movies['tags'] = movies['overview']+movies['genre’] #it will combine the genre and overview column
movies
new_data = movies.drop(columns=['overview', 'genre'])
new_data](https://image.slidesharecdn.com/movierecommendationsystem-230621061735-ea969ff9/85/MOVIE-RECOMMENDATION-SYSTEM-pptx-9-320.jpg)
![from sklearn.feature_extraction.text import CountVectorizer #method to convert text to numerical data.
cv=CountVectorizer(max_features=10000, stop_words='english')
cv
vector=cv.fit_transform(new_data['tags'].values.astype('U')).toarray()
vector.shape
from sklearn.metrics.pairwise import cosine_similarity
similarity=cosine_similarity(vector)
similarity
new_data[new_data['title']=="The Godfather"].index[0]
distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]:
print(new_data.iloc[i[0]].title)](https://image.slidesharecdn.com/movierecommendationsystem-230621061735-ea969ff9/85/MOVIE-RECOMMENDATION-SYSTEM-pptx-10-320.jpg)
![def recommend(movies):
index=new_data[new_data['title']==movies].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]: #to print only top 5 movies
print(new_data.iloc[i[0]].title)
import pickle
pickle.dump(new_data, open('movies_list.pkl', 'wb'))
pickle.dump(similarity, open('similarity.pkl', 'wb'))
pickle.load(open('movies_list.pkl', 'rb'))](https://image.slidesharecdn.com/movierecommendationsystem-230621061735-ea969ff9/85/MOVIE-RECOMMENDATION-SYSTEM-pptx-11-320.jpg)
![Code For webhosting
import streamlit as st
import pickle
import requests
def fetch_poster(movie_id):
url = "https://api.themoviedb.org/3/movie/{}?api_key=43c2c7148a22f65595a5dcc10a9d6c8b".format(movie_id)
data=requests.get(url)
data=data.json()
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/"+poster_path
return full_path
movies = pickle.load(open("movies_list.pkl", 'rb'))
similarity = pickle.load(open("similarity.pkl", 'rb'))
movies_list=movies['title'].values
st.header("Movie Recommender System")](https://image.slidesharecdn.com/movierecommendationsystem-230621061735-ea969ff9/85/MOVIE-RECOMMENDATION-SYSTEM-pptx-12-320.jpg)
![import streamlit.components.v1 as components
imageCarouselComponent = components.declare_component("image-carousel-
component", path="frontend/public")
#imageCarouselComponent(imageUrls=imageUrls, height=200)
selectvalue=st.selectbox("Select movie from dropdown", movies_list)
def recommend(movie):
index=movies[movies['title']==movie].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True,
key=lambda vector:vector[1])
recommend_movie=[]
recommend_poster=[]
for i in distance[1:6]:
movies_id=movies.iloc[i[0]].id
recommend_movie.append(movies.iloc[i[0]].title)
recommend_poster.append(fetch_poster(movies_id))
return recommend_movie, recommend_poster
if st.button("Show Recommend"):
movie_name, movie_poster = recommend(selectvalue)
col1,col2,col3,col4,col5=st.columns(5)
with col1:
st.text(movie_name[0])
st.image(movie_poster[0])
with col2:
st.text(movie_name[1])
st.image(movie_poster[1])
with col3:
st.text(movie_name[2])
st.image(movie_poster[2])
with col4:
st.text(movie_name[3])
st.image(movie_poster[3])
with col5:
st.text(movie_name[4])
st.image(movie_poster[4])](https://image.slidesharecdn.com/movierecommendationsystem-230621061735-ea969ff9/85/MOVIE-RECOMMENDATION-SYSTEM-pptx-13-320.jpg)