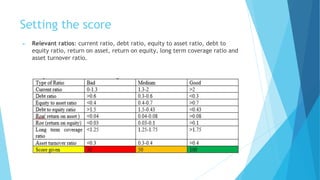
1) The document discusses using machine learning techniques like logistic regression, random forest, and K-means clustering to develop a credit scoring model based on financial ratios to predict a company's probability of default.
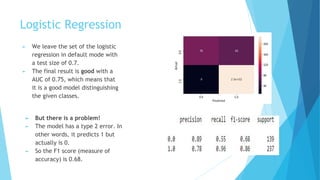
2) Random forest performed the best with an AUC of 0.87 and high precision and recall, while logistic regression had a AUC of 0.75 but issues with type II errors.
3) K-means clustering had a lower precision predicting defaults but an acceptable F1-score and AUC of 0.80.