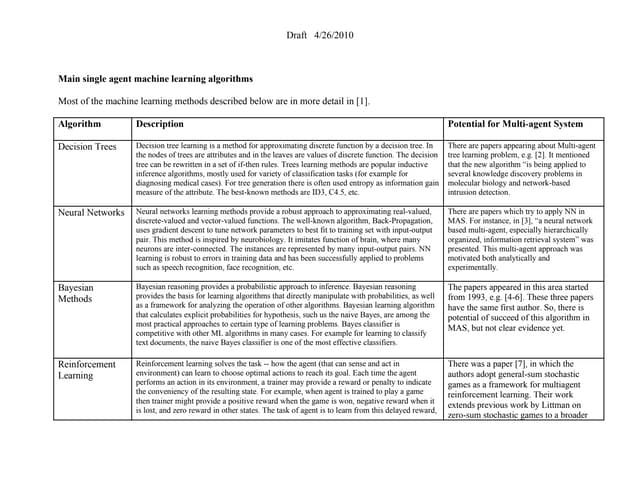
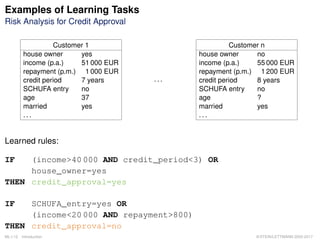
The document discusses various learning tasks and problems in machine learning, highlighting examples such as credit risk analysis and chess playing strategies. It outlines different learning paradigms including supervised, unsupervised, and reinforcement learning, along with the role of experience in improving task performance. Additionally, it covers the construction of classifiers from real-world examples and the LMS algorithm for fitting model functions to training data.



![Examples of Learning Tasks
Image Analysis [Mitchell 1997]
ML:I-13 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-5-320.jpg)
![Examples of Learning Tasks
Image Analysis [Mitchell 1997]
Sharp
Left
Sharp
Right
4 Hidden
Units
30 Output
Units
30x32 Sensor
Input Retina
Straight
Ahead
...
ML:I-14 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-6-320.jpg)
![Specification of Learning Problems
Definition 1 (Machine Learning [Mitchell 1997])
A computer program is said to learn
K from experience
K with respect to some class of tasks and
K a performance measure,
if its performance at the tasks improves with the experience.
ML:I-15 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-7-320.jpg)
![Remarks:
K Example: chess
– task = playing chess
– performance measure = number of games won during a world championship
– experience = possibility to play against itself
K Example: optical character recognition
– task = isolation and classification of handwritten words in bitmaps
– performance measure = percentage of correctly classified words
– experience = collection of correctly classified, handwritten words
K A corpus with labeled examples forms a kind of “compiled experience”.
K Consider the different corpora that are exploited for different learning tasks in the webis
group. [www.uni-weimar.de/medien/webis/corpora]
ML:I-16 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-8-320.jpg)


![Specification of Learning Problems
Example Chess: Kind of Experience [Mitchell 1997]
1. Feedback
– direct: for each board configuration the best move is given.
– indirect: only the final result is given after a series of moves.
ML:I-19 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-11-320.jpg)
![Specification of Learning Problems
Example Chess: Kind of Experience [Mitchell 1997]
1. Feedback
– direct: for each board configuration the best move is given.
– indirect: only the final result is given after a series of moves.
2. Sequence and distribution of examples
– A teacher presents important example problems along with a solution.
– The learner chooses from the examples; e.g., pick a board for which the
best move is unknown.
– The selection of examples to learn from should follow the (expected)
distribution of future problems.
ML:I-20 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-12-320.jpg)
![Specification of Learning Problems
Example Chess: Kind of Experience [Mitchell 1997]
1. Feedback
– direct: for each board configuration the best move is given.
– indirect: only the final result is given after a series of moves.
2. Sequence and distribution of examples
– A teacher presents important example problems along with a solution.
– The learner chooses from the examples; e.g., pick a board for which the
best move is unknown.
– The selection of examples to learn from should follow the (expected)
distribution of future problems.
3. Relevance under a performance measure
– How far can we get with experience?
– Can we master situations in the wild?
(playing against itself will be not enough to become world class)
ML:I-21 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-13-320.jpg)
![Specification of Learning Problems
Example Chess: Ideal Target Function γ [Mitchell 1997]
(a) γ : Boards → Moves
(b) γ : Boards → R
ML:I-22 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-14-320.jpg)
![Specification of Learning Problems
Example Chess: Ideal Target Function γ [Mitchell 1997]
(a) γ : Boards → Moves
(b) γ : Boards → R
A recursive definition of γ, following a kind of means-ends analysis :
Let be o ∈ Boards.
1. γ(o) = 100, if o represents a final board state that is won.
2. γ(o) = −100, if o represents a final board state that is lost.
3. γ(o) = 0, if o represents a final board state that is drawn.
4. γ(o) = γ(o∗
) otherwise.
o∗
denotes the best final state that can be reached if both sides play optimally.
Related: minimax strategy, α-β pruning. [Course on Search Algorithms, Stein 1998-2017]
ML:I-23 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-15-320.jpg)





![Specification of Learning Problems [model world]
How to Build a Classifier y
Characterization of the real world:
K O is a set of objects. (example: mails)
K C is a set of classes. (example: spam versus ham)
K γ : O → C is the ideal classifier for O. (typically a human expert)
ML:I-29 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-21-320.jpg)
![Specification of Learning Problems [model world]
How to Build a Classifier y
Characterization of the real world:
K O is a set of objects. (example: mails)
K C is a set of classes. (example: spam versus ham)
K γ : O → C is the ideal classifier for O. (typically a human expert)
Classification problem:
K Given some o ∈ O, determine its class γ(o) ∈ C. (example: is a mail spam?)
Acquisition of classification knowledge:
1. Collect real-world examples of the form (o, γ(o)), o ∈ O.
2. Abstract the objects towards feature vectors x ∈ X, with x = α(o).
3. Construct feature vector examples as (x, c(x)), with x = α(o), c(x) = γ(o).
ML:I-30 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-22-320.jpg)
![Specification of Learning Problems [real world]
How to Build a Classifier y (continued)
Characterization of the model world:
K X is a set of feature vectors, called feature space. (example: word frequencies)
K C is a set of classes. (as before: spam versus ham)
K c : X → C is the ideal classifier for X. (c is unknown)
K D = {(x1, c(x1)), . . . , (xn, c(xn))} ⊆ X × C is a set of examples.
ML:I-31 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-23-320.jpg)
![Specification of Learning Problems [real world]
How to Build a Classifier y (continued)
Characterization of the model world:
K X is a set of feature vectors, called feature space. (example: word frequencies)
K C is a set of classes. (as before: spam versus ham)
K c : X → C is the ideal classifier for X. (c is unknown)
K D = {(x1, c(x1)), . . . , (xn, c(xn))} ⊆ X × C is a set of examples.
Machine learning problem:
K Approximate the ideal classifier c (implicitly given via D) by a function y:
§ Decide on a model function y : X → C, x → y(x) (y needs to be parameterized)
§ Apply statistics, search, theory, and algorithms from the field of machine
learning to maximize the goodness of fit between c and y.
ML:I-32 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-24-320.jpg)


![Specification of Learning Problems
LMS Algorithm for Fitting y [IGD Algorithm]
Algorithm: LMS Least Mean Squares.
Input: D Training examples of the form (x, c(x)) with target function value c(x) for x.
η Learning rate, a small positive constant.
Internal: y(D) Set of y(x)-values computed from the elements x in D given some w.
Output: w Weight vector.
LMS(D, η)
1. initialize_random_weights((w0, w1, . . . , wp))
2. REPEAT
3. (x, c(x)) = random_select(D)
4. y(x) = w0 + w1 · x1 + . . . + wp · xp
5. error = c(x) − y(x)
6. FOR j = 0 TO p DO
7. ∆wj = η · error · xj // ∀x∈D : x|x0
≡ 1
8. wj = wj + ∆wj
9. ENDDO
10. UNTIL(convergence(D, y(D)))
11. return((w0, w1, . . . , wp))
ML:I-35 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-27-320.jpg)
![Remarks:
K The LMS weight adaptation corresponds to the incremental gradient descend [IGD] algorithm,
and approximates the global direction of steepest error descent as used by the batch gradient
descent [BGD] algorithm, for which more rigorous statements on convergence are possible.
K Possible criteria for convergence() :
– The global error quantified as the sum of the squared residuals, x,c(x)∈D (c(x) − y(x))2
.
– An upper bound on the number of iterations.
ML:I-36 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-28-320.jpg)
![Specification of Learning Problems
Design of Learning Systems [p.12, Mitchell 1997]
Solution
Moves, γ(o*)
Chess
program
compute_solution()
Problem
Chess
board
ML:I-37 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-29-320.jpg)
![Specification of Learning Problems
Design of Learning Systems [p.12, Mitchell 1997]
Solution
Moves, γ(o*)
Chess
program
compute_solution()
Problem
Chess
board
Training examples
(x1, c(x1)), ...,
(xn, c(xn))
accept
improve
Move
analysis
evaluate()
ML:I-38 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-30-320.jpg)
![Specification of Learning Problems
Design of Learning Systems [p.12, Mitchell 1997]
Solution
Moves, γ(o*)
Chess
program
compute_solution()
Problem
Chess
board
Training examples
(x1, c(x1)), ...,
(xn, c(xn))
accept
improve
Move
analysis
evaluate()
generalize()
LMS
algorithm
Hypothesis
(w0, ..., wp)
ML:I-39 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-31-320.jpg)
![Specification of Learning Problems
Design of Learning Systems [p.12, Mitchell 1997]
Solution
Moves, γ(o*)
Chess
program
compute_solution()
Problem
Chess
board
Training examples
(x1, c(x1)), ...,
(xn, c(xn))
accept
improve
Move
analysis
evaluate()
generalize()
LMS
algorithm
Hypothesis
(w0, ..., wp)
generate_
problem()
Important design aspects:
1. kind of experience
2. fidelity of the model formation function α : O → X
3. class or structure of the model function y
4. learning method for fitting y
ML:I-40 Introduction © STEIN/LETTMANN 2005-2017](https://image.slidesharecdn.com/unit-en-ml-introduction-180111081607/85/Machine-Learning-and-Data-Mining-Organization-Literature-32-320.jpg)










![UNIT 1 Machine Learning [KCS-055] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit1machinelearningkcs-0551-230208173320-a2f4e13a-thumbnail.jpg?width=640&height=640&fit=bounds)