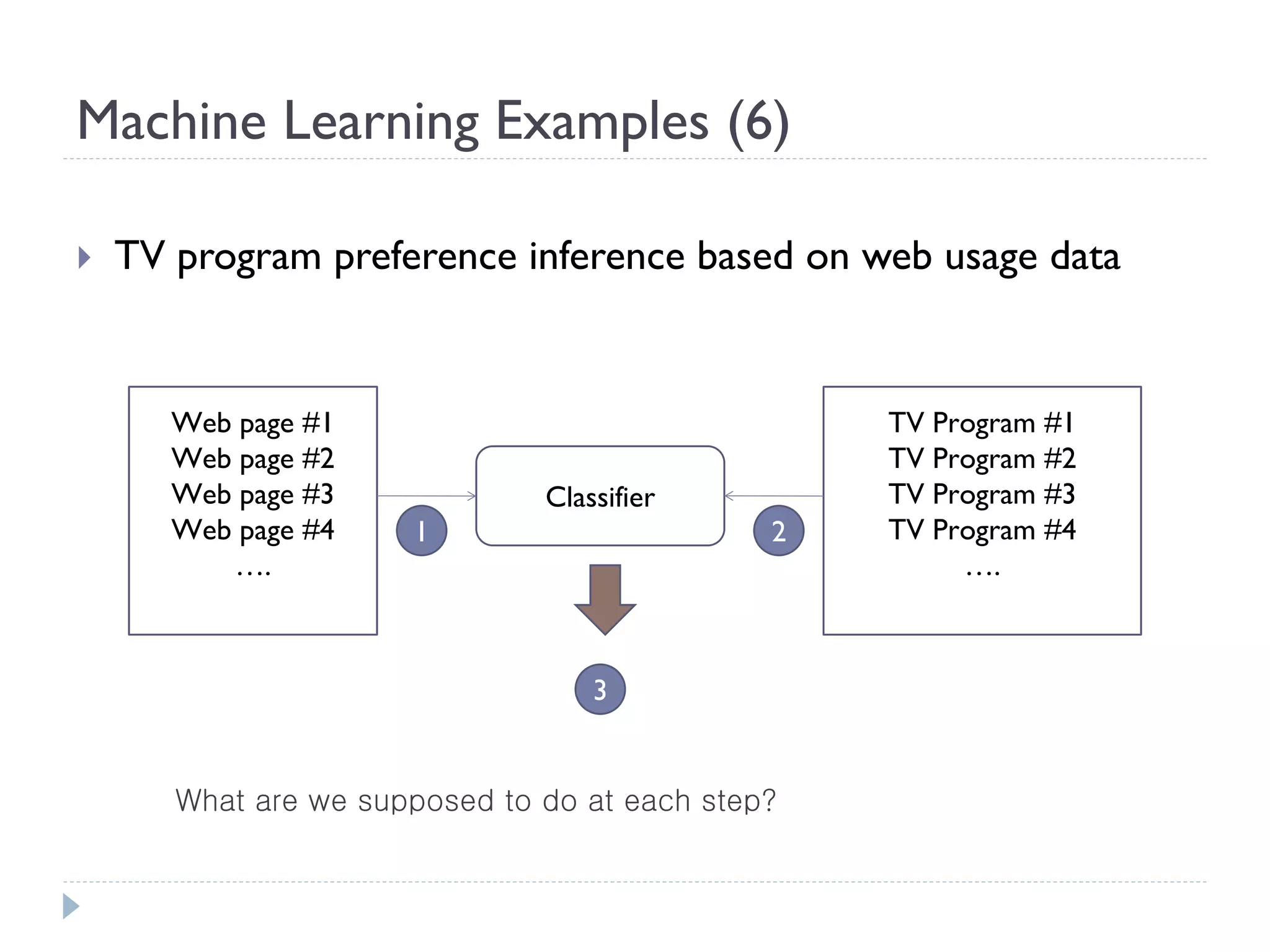
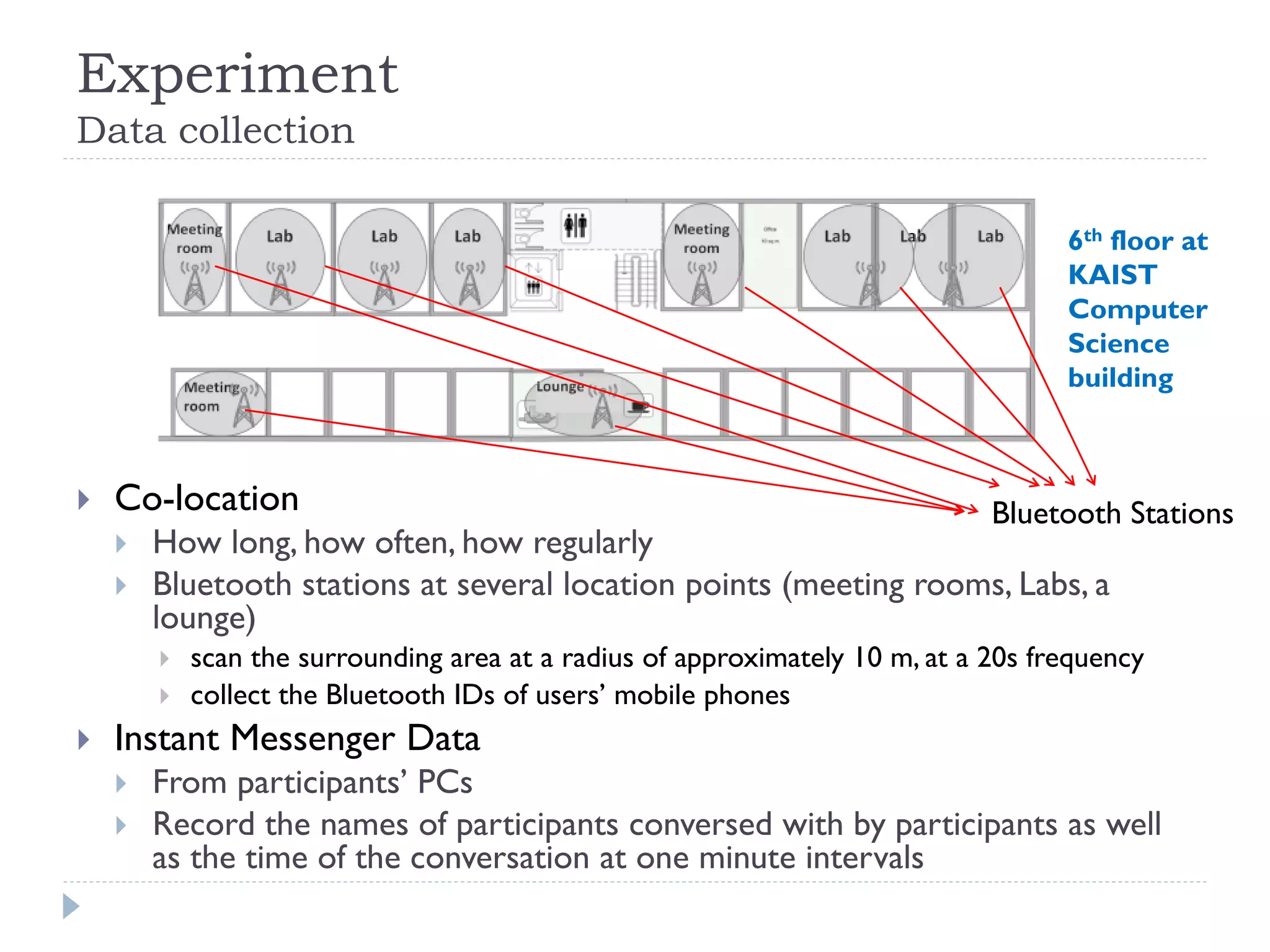
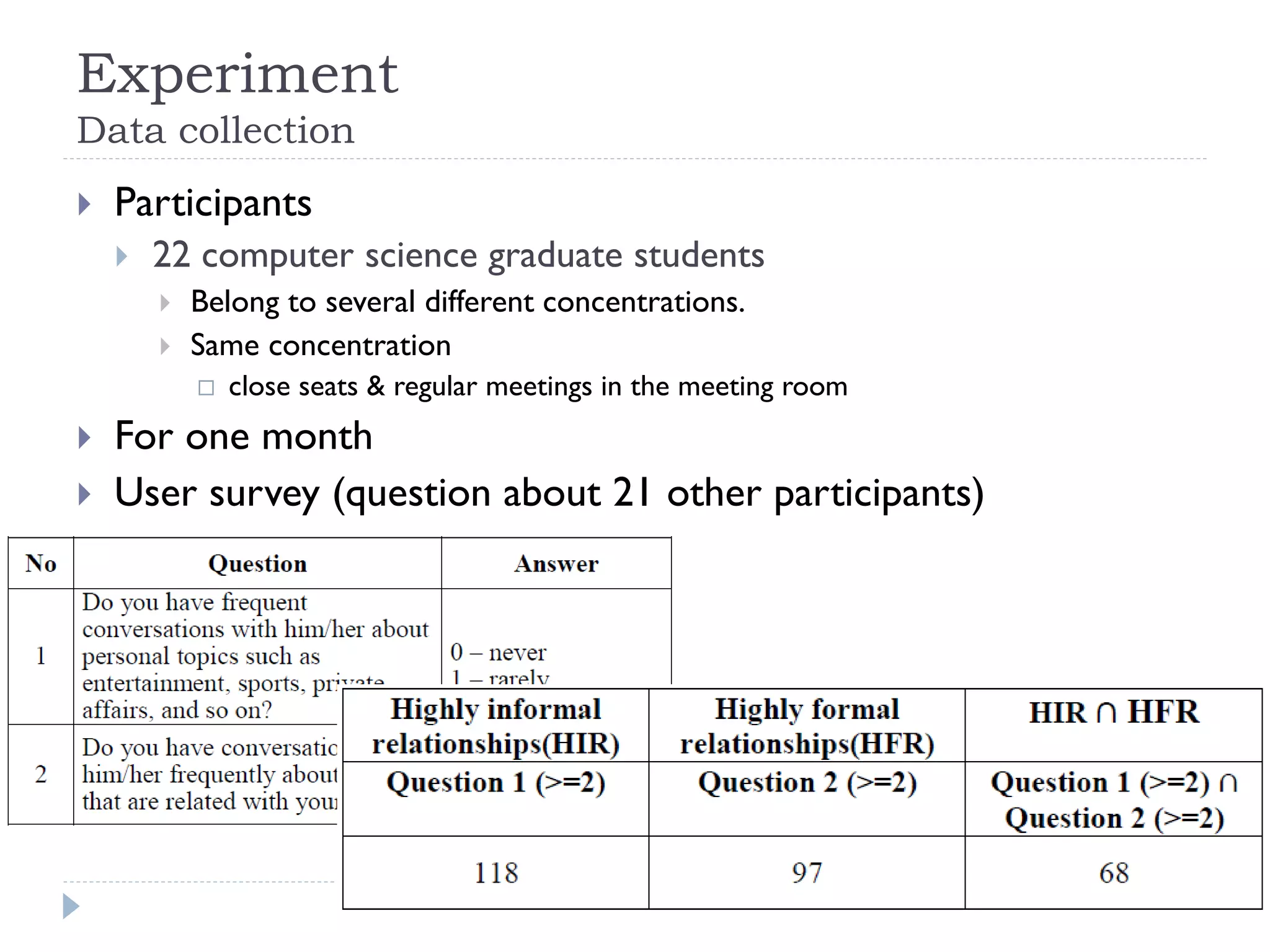
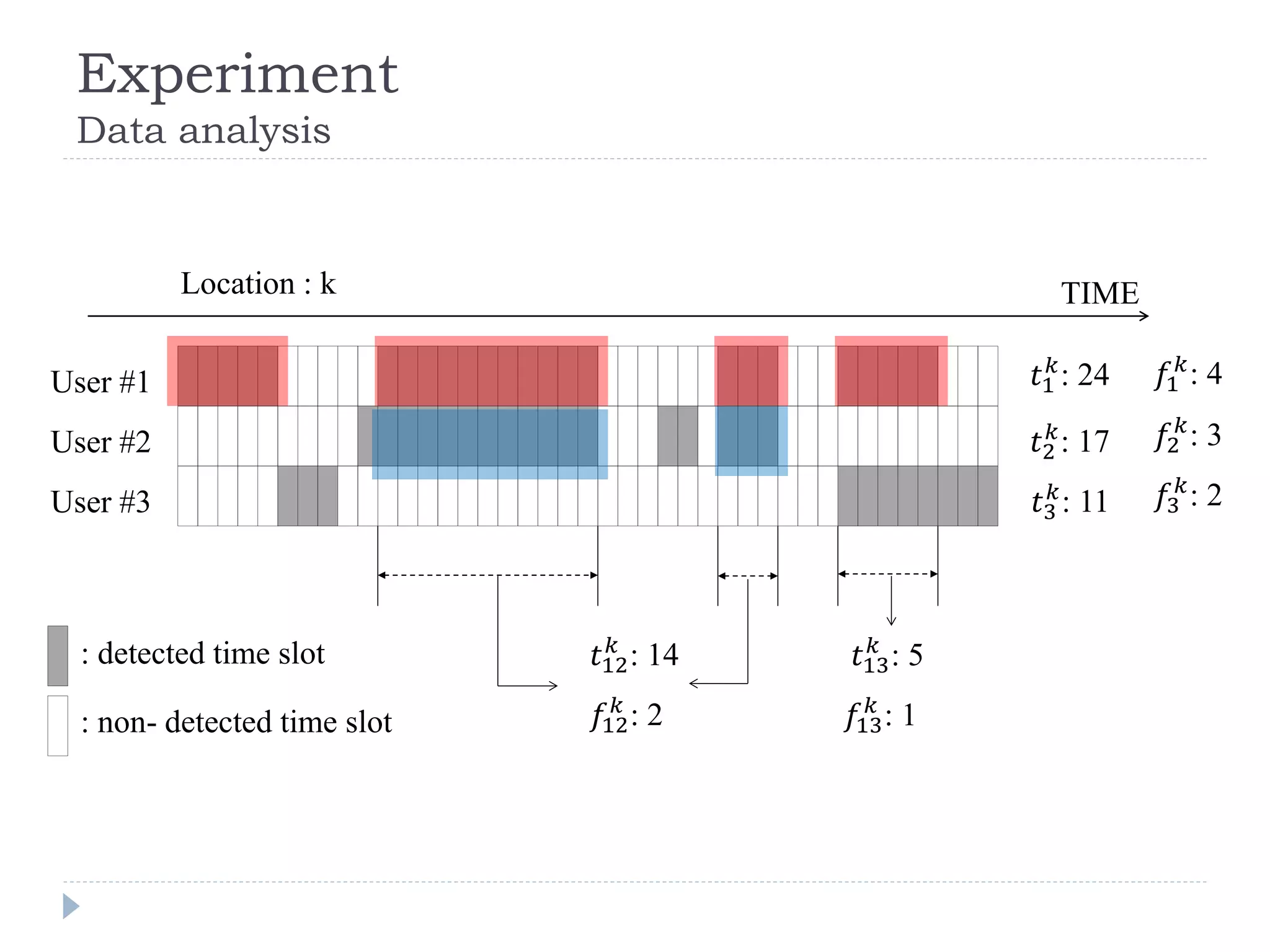
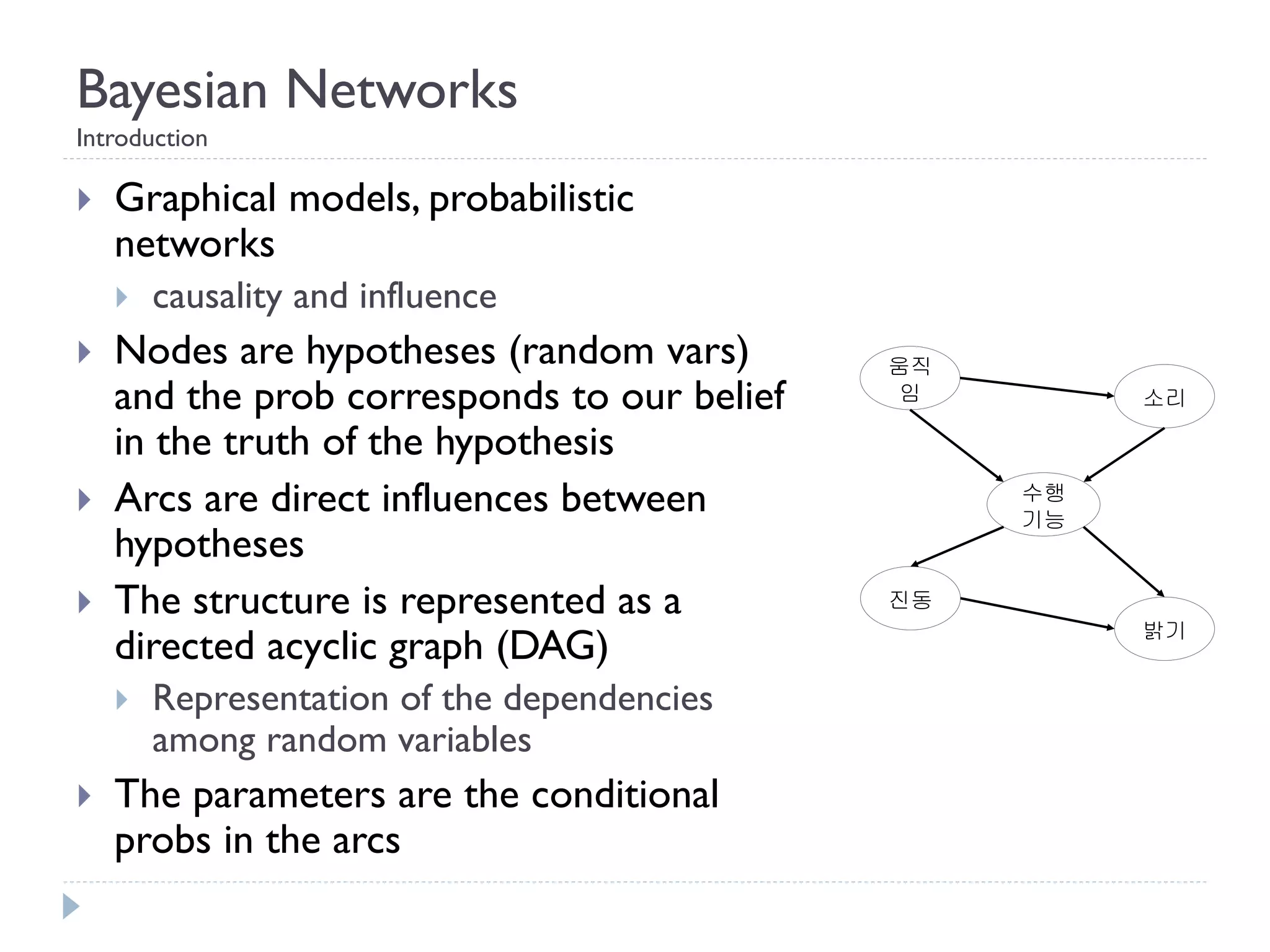
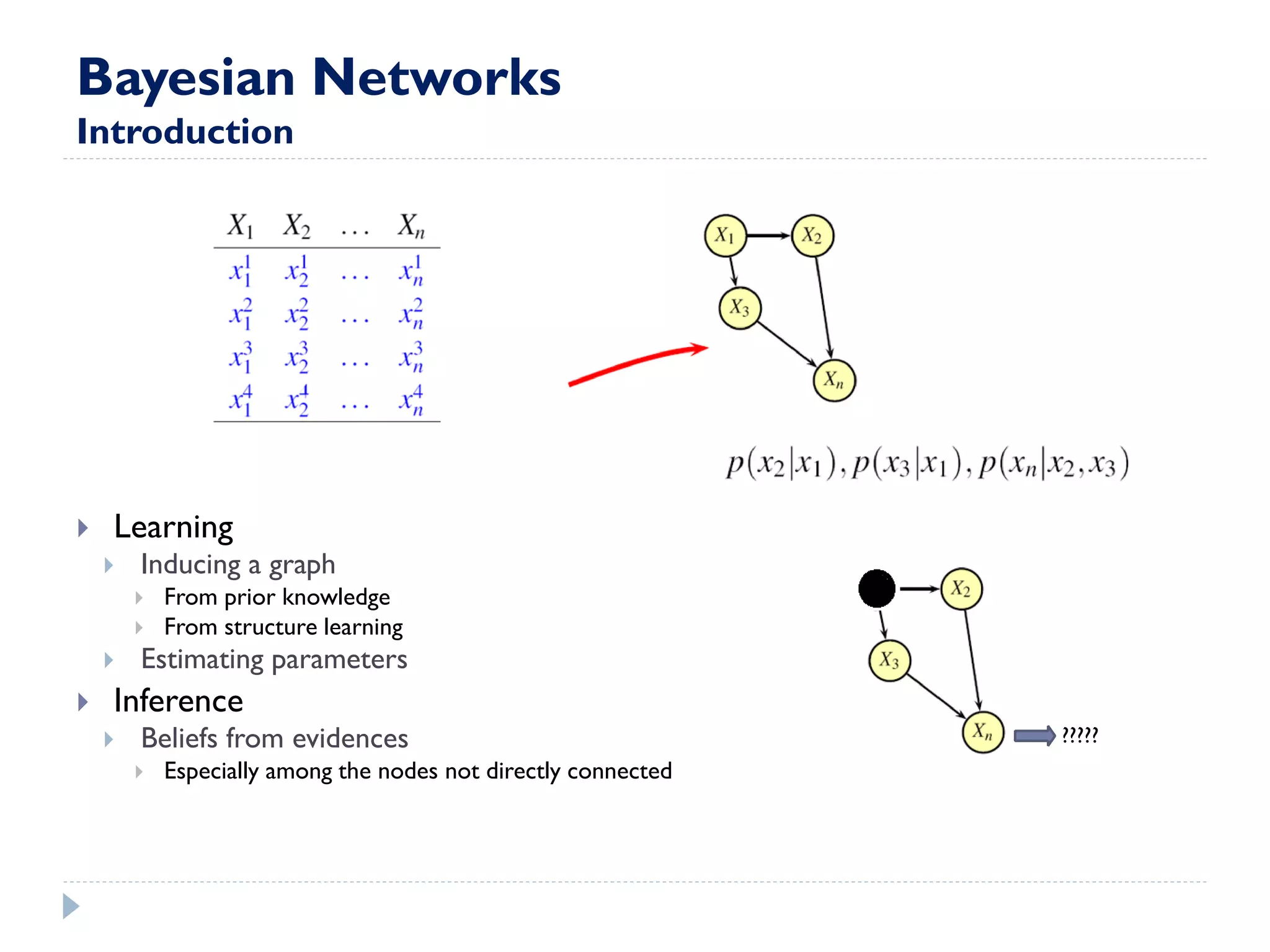
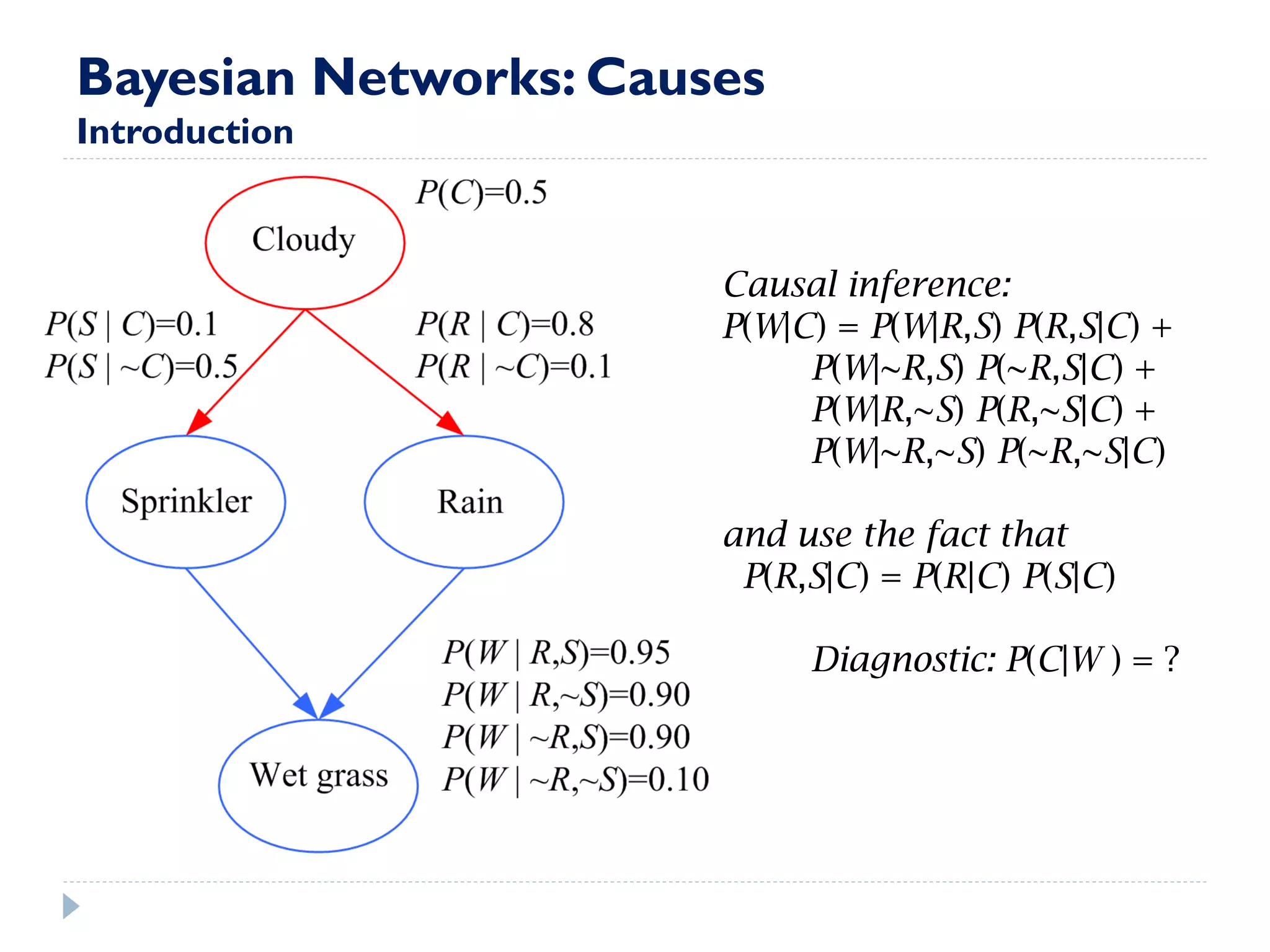
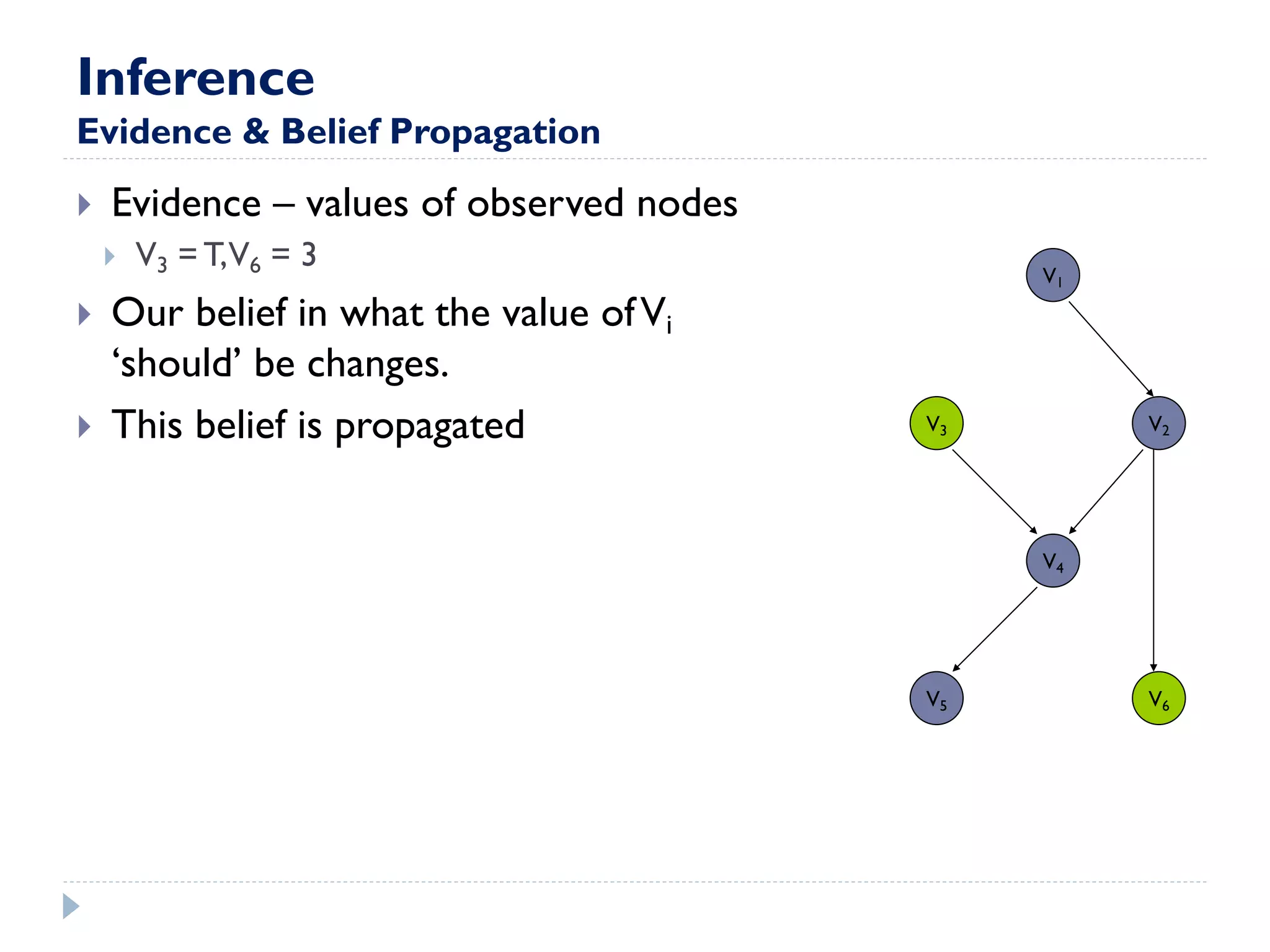
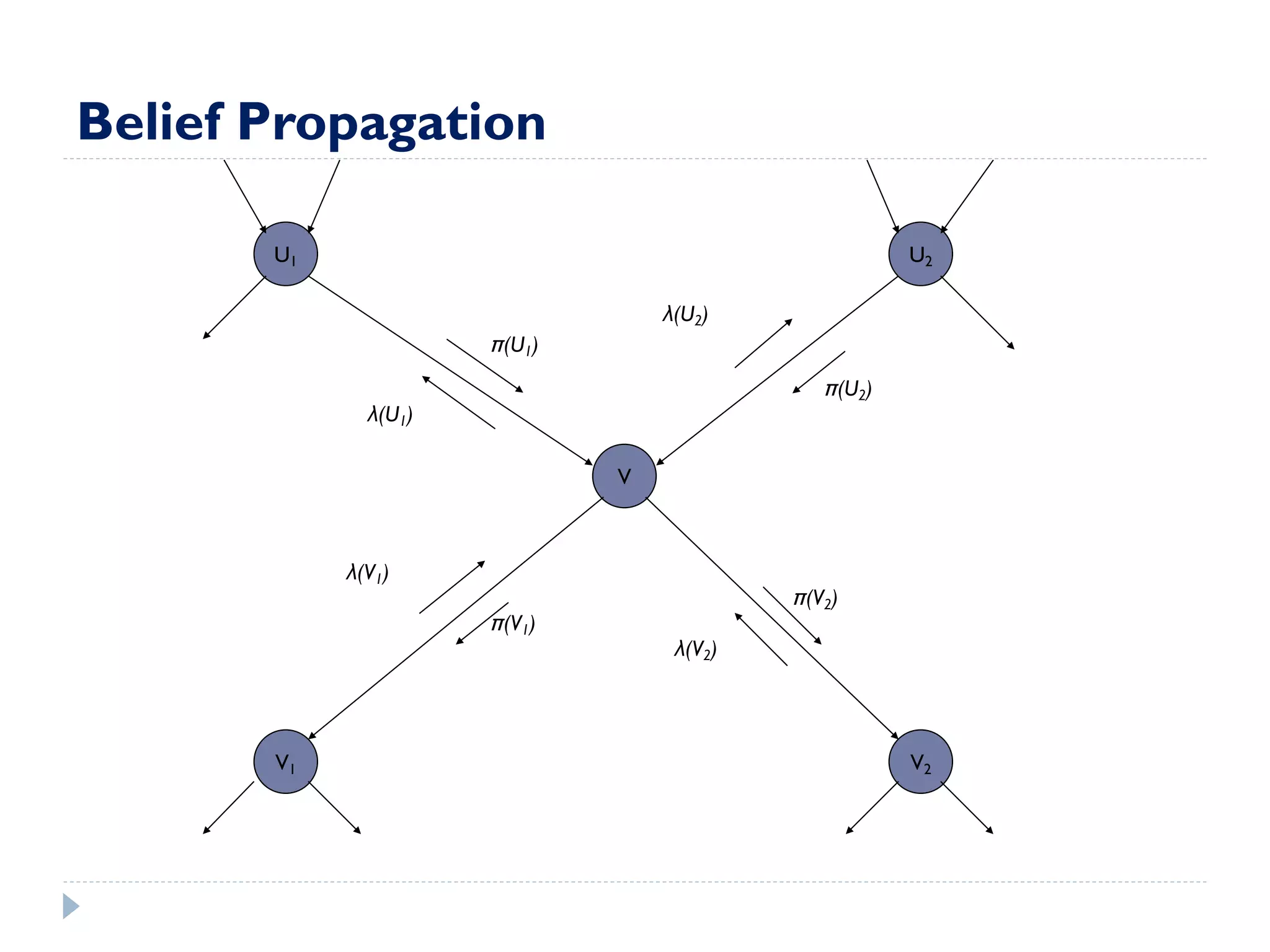
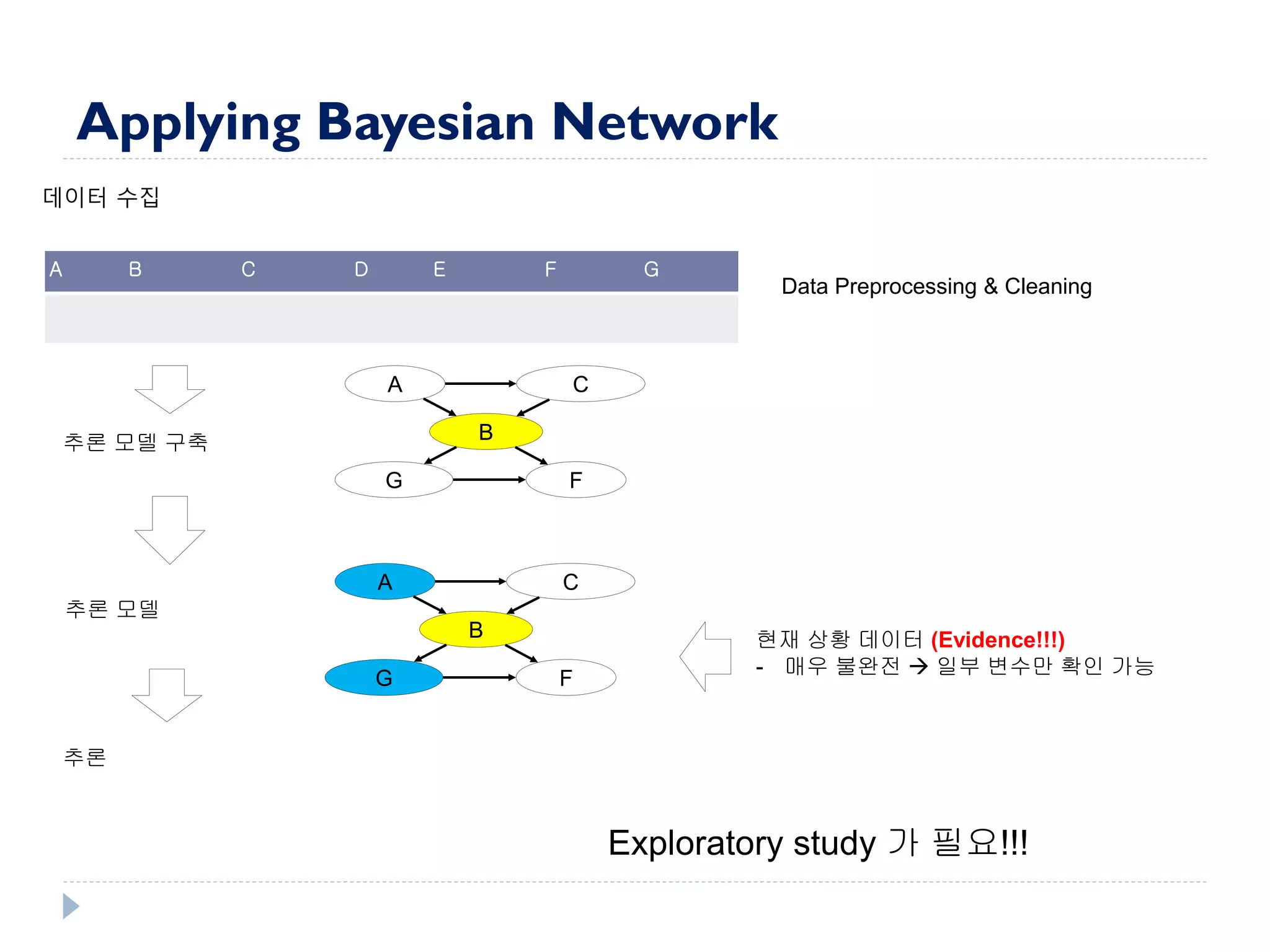
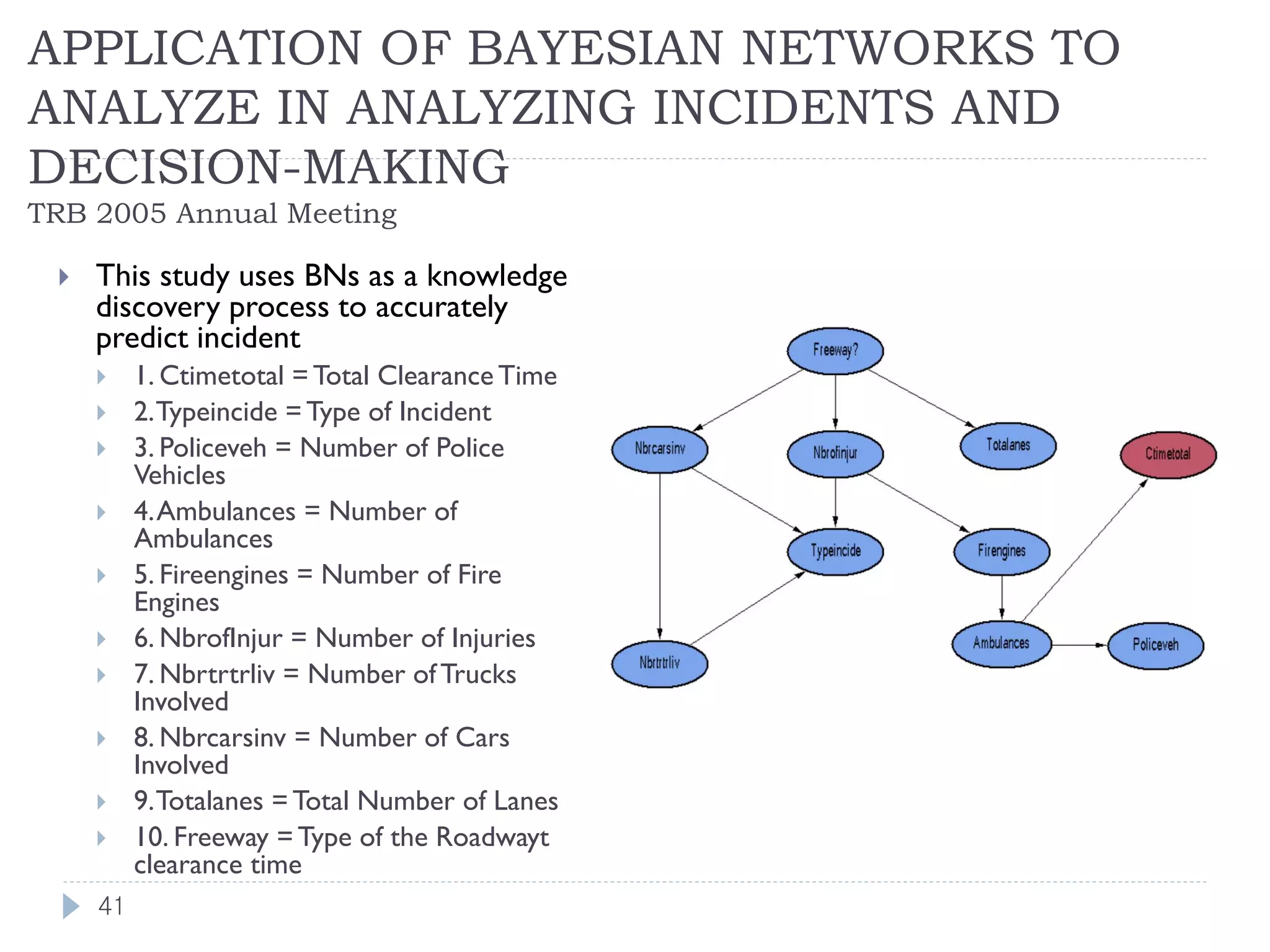
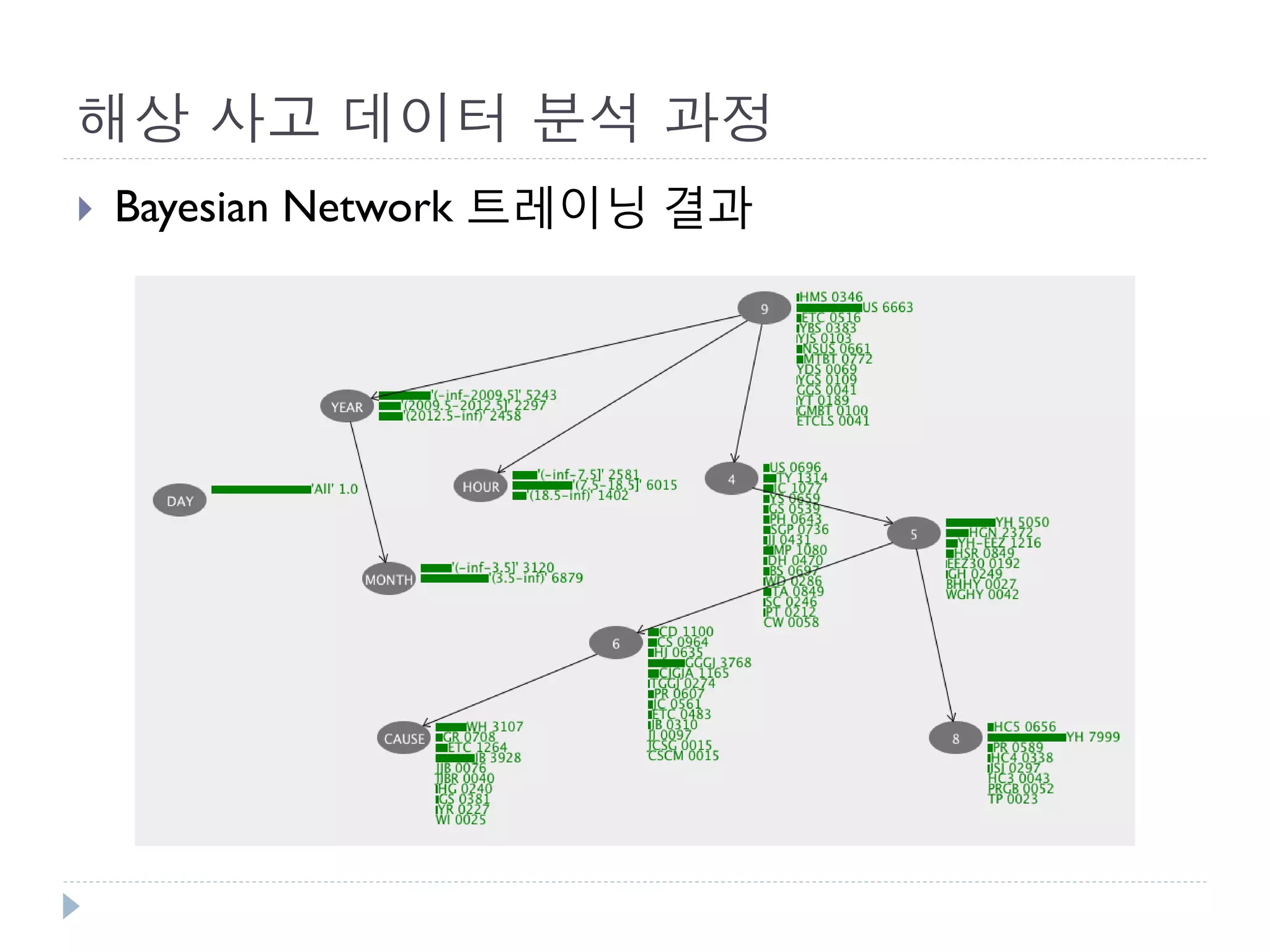
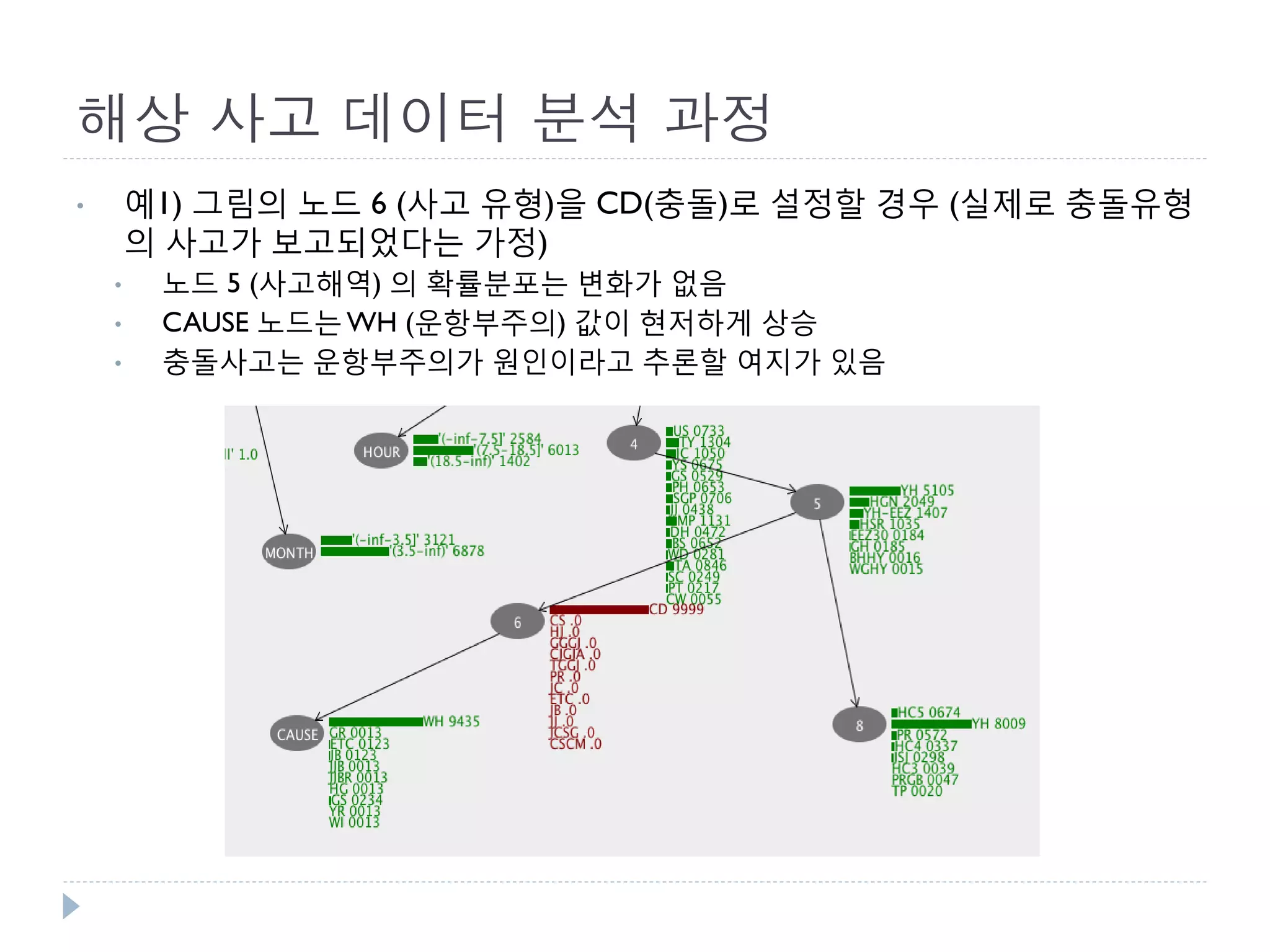
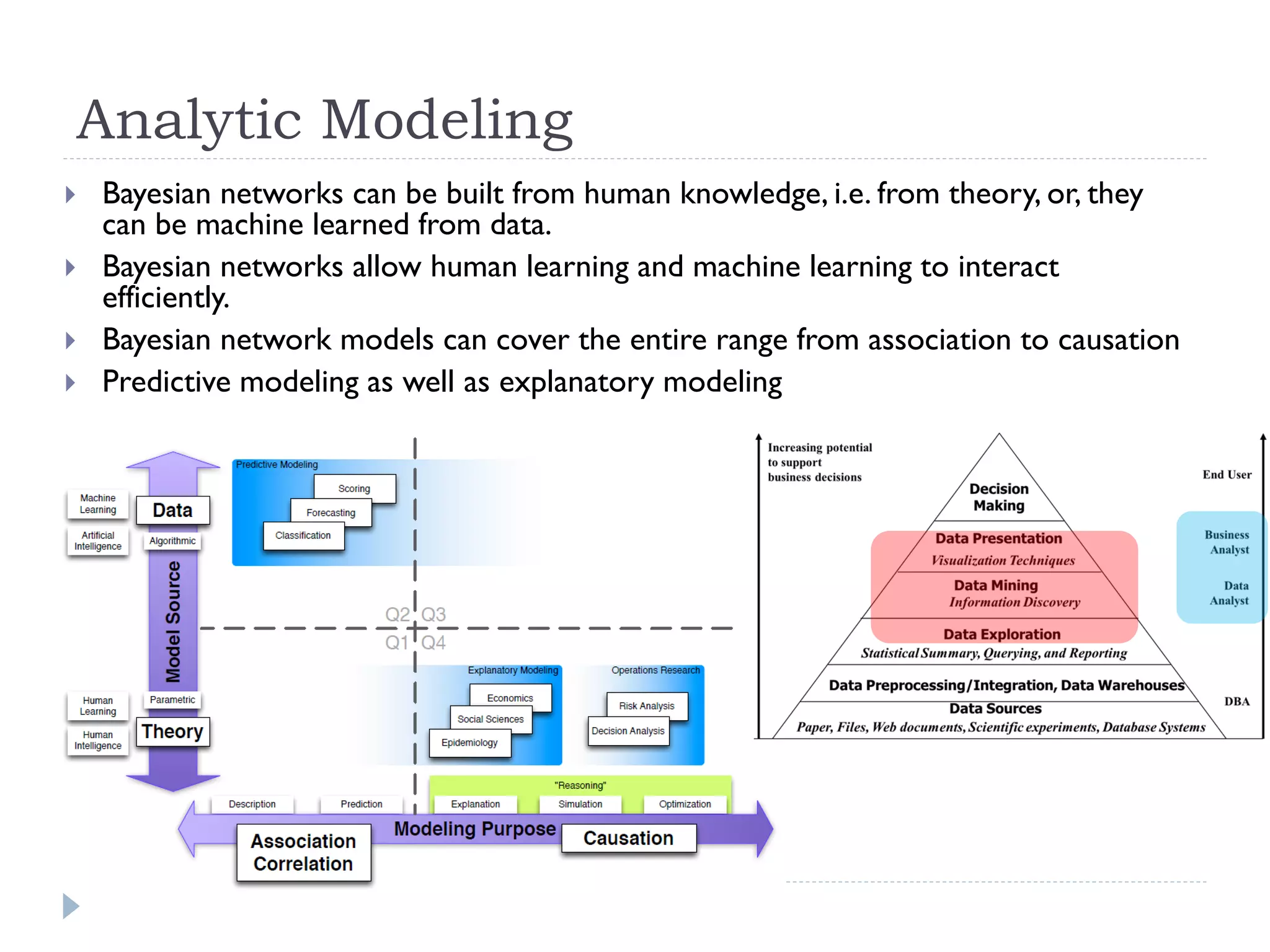
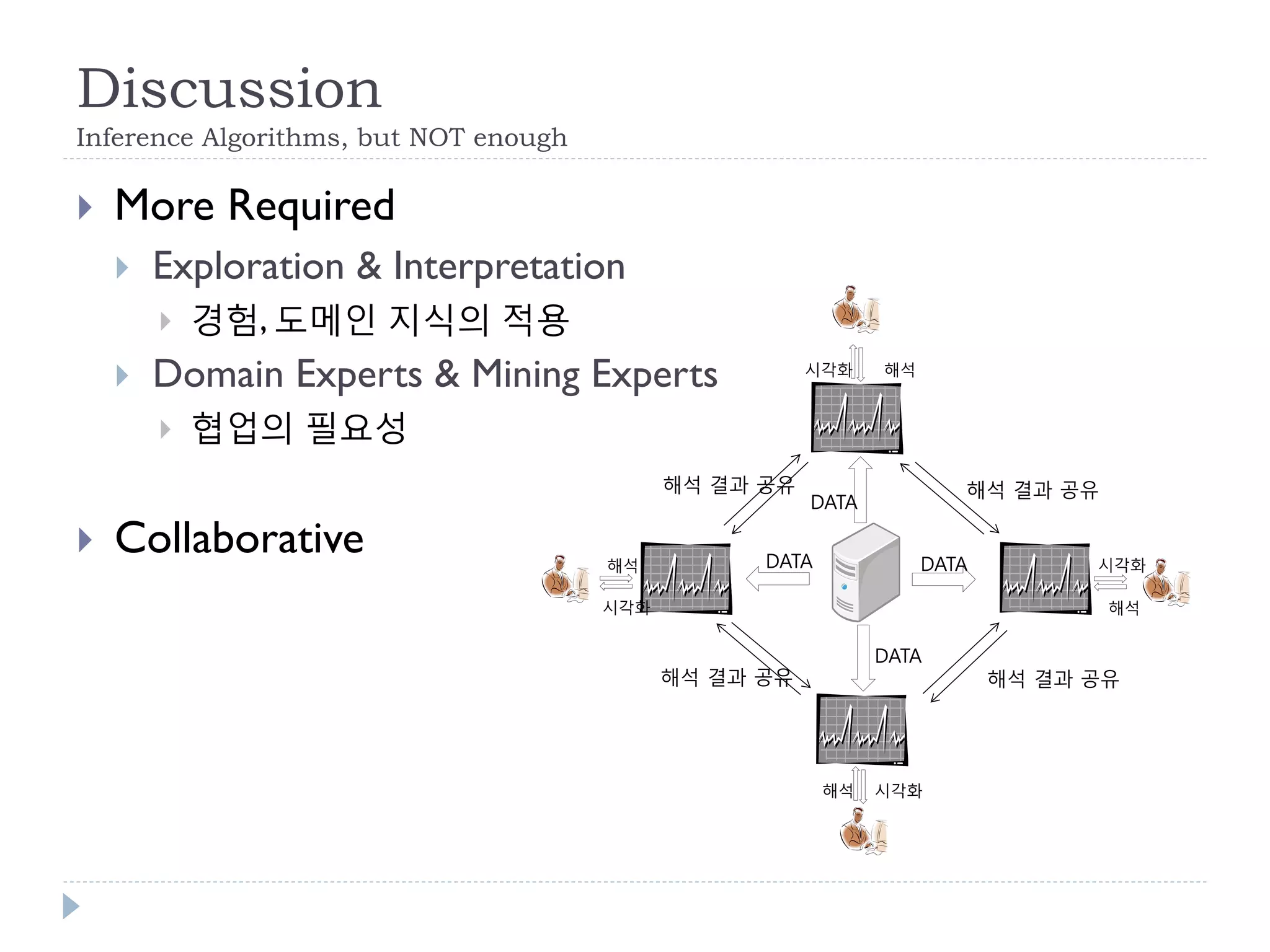
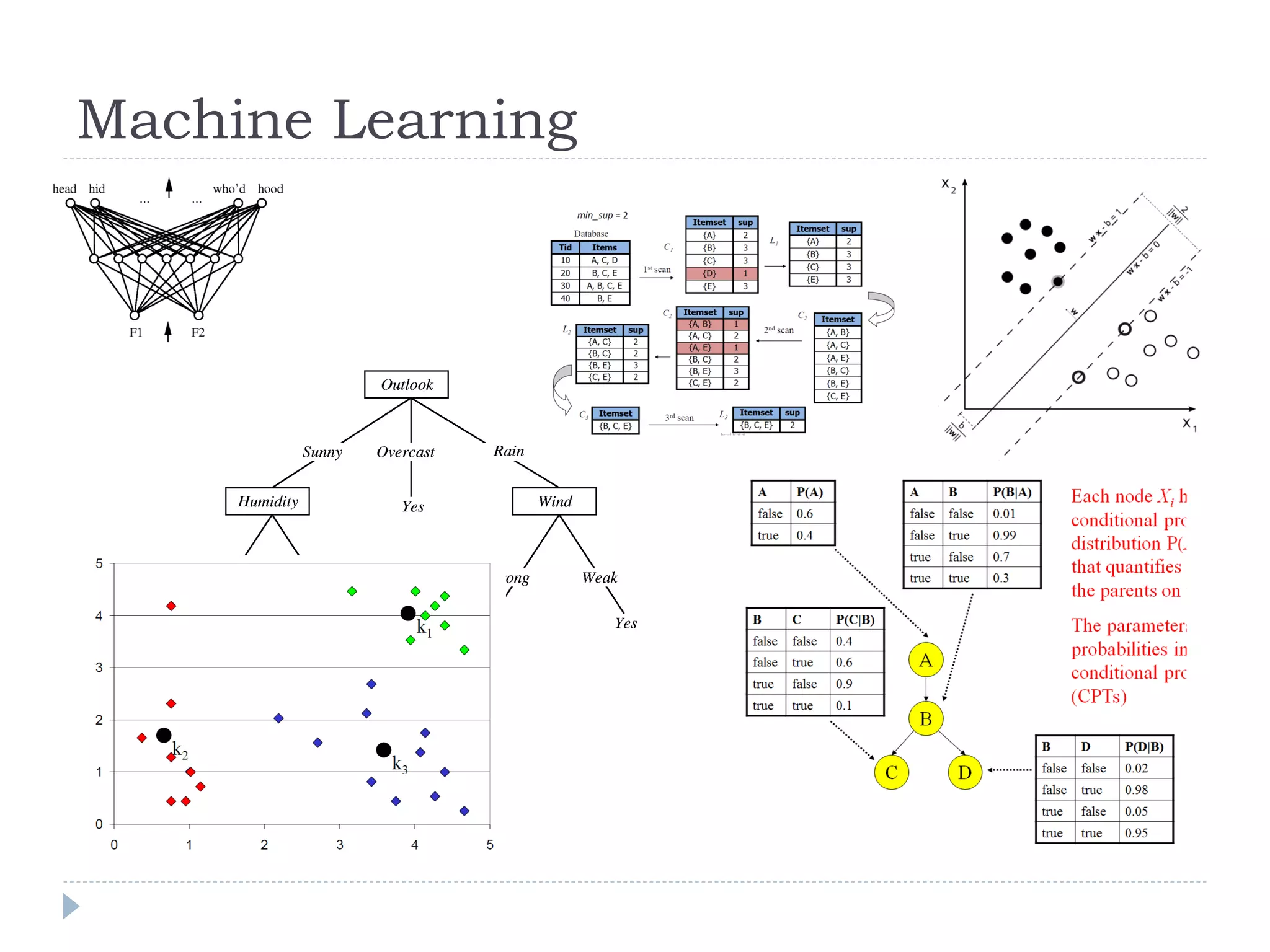
This document discusses using Bayesian networks for predictive analysis and machine learning perspectives on data utilization. It provides an example of using Bayesian networks to accurately predict incident clearance time based on variables like type of incident, number of police/ambulance vehicles, number of injuries, and number of vehicles involved. The document also discusses applying Bayesian networks by collecting current situation data as evidence to perform inference on a constructed inference model.




![Machine Learning Examples (1)
Function approximation (Mexican hat)
2 2
3 1 2 1 2 1 2 f (x , x ) sin 2 x x , x , x [1,1]](https://image.slidesharecdn.com/datascienceseminar-140917214432-phpapp01/75/Bayesian-Network-10-2048.jpg)