Download as PDF, PPTX













![need to rewrite some part:
conversion int -> char[]
int intToString(int i, char[] buffer, int offset)
avoid intermediate/temporary char[]
Allocation
17](https://image.slidesharecdn.com/lowlatencymechanicalsympathy-issuesandsolutions-150723113144-lva1-app6892/85/Low-latency-mechanical-sympathy-issues-and-solutions-17-320.jpg)



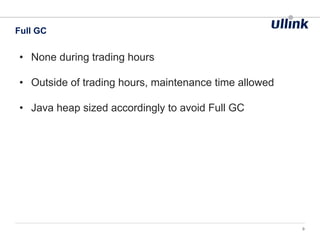
![Full GC fallback unpredictable (fragmentation, promotion
failure, …)
176710.366: [GC 176710.366: [ParNew ( promotion failed):
471872K->455002K(471872K), 2.4424250 secs]176712.809: [CMS:
6998032K->5328833K(7864320K), 53.8558640 secs] 7457624K->5328833K(8336192K),
[CMS Perm : 199377K->198212K(524288K)], 56.2987730 secs] [Times: user=56.60
sys=0.78, real=56.29 secs]
Same problem for G1
CMS
21](https://image.slidesharecdn.com/lowlatencymechanicalsympathy-issuesandsolutions-150723113144-lva1-app6892/85/Low-latency-mechanical-sympathy-issues-and-solutions-21-320.jpg)


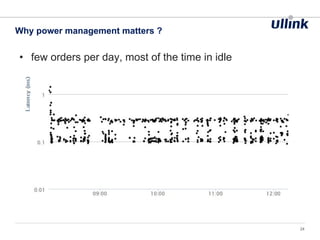

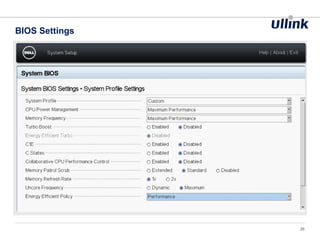
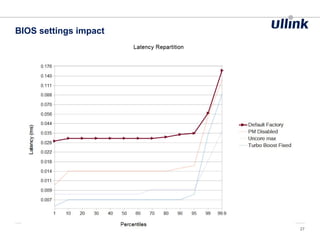
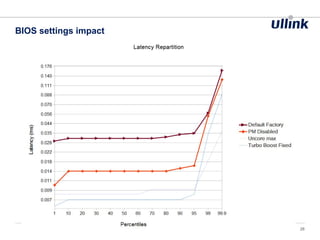
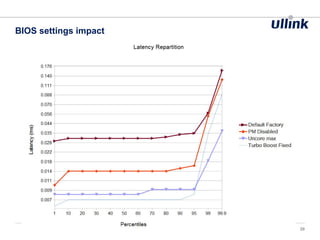
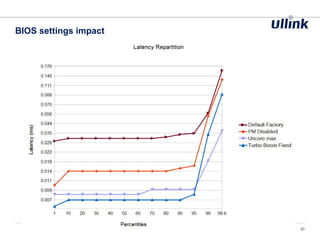


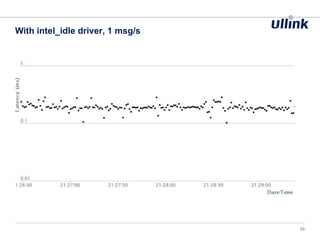
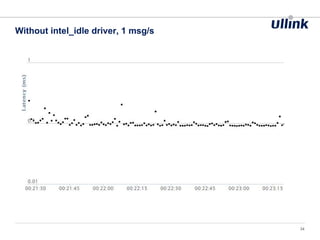
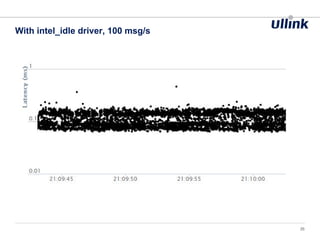
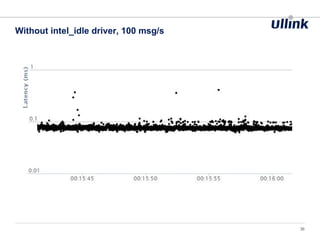

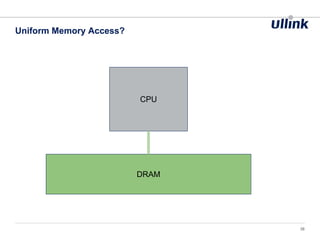
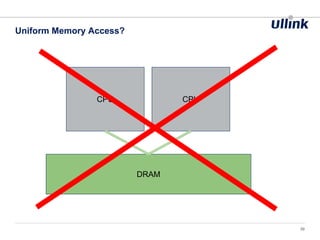

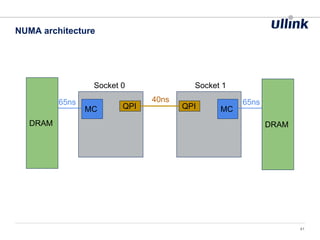


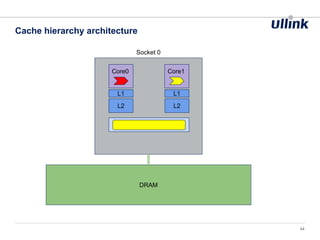


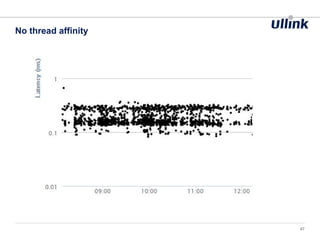
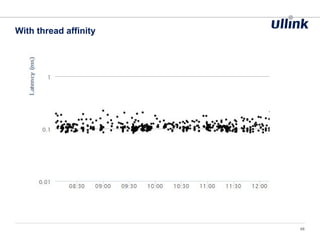

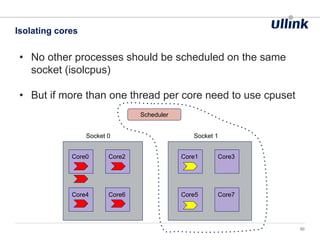




This document discusses issues related to low latency and mechanical sympathy in a Java application for routing orders. It addresses GC pauses, power management, NUMA, and cache pollution. To achieve sub-millisecond performance, the document recommends tuning the GC, BIOS, OS, NUMA configuration, and avoiding cache pollution through thread affinity and CPU isolation. The goal is to optimize performance without changing application code through mechanical sympathy with the hardware.











































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)





![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)