Downloaded 38 times















![Chapter 1 Introduction
1
INTRODUCTION
Compression is the art of representing the information in a compact form rather than
in its original or uncompressed form. In other words, using the data compression, the size
of a particular file can be reduced. This is very useful when processing, storing or
transferring a huge file, which needs lots of resources. If the algorithms used to encrypt
works properly, there should be a significant difference between the original file and the
compressed file. When the data compression is used in a data transmission application,
speed is the primary goal. The speed of the transmission depends on the number of bits
sent, the time required for the encoder to generate the coded message, and the time
required for the decoder to recover the original ensemble. In a data storage application, the
degree of compression is the primary concern. Compression can be classified as either
lossy or lossless.
Lossy compression is one in which compressing data and then decompressing it
retrieves data that will be different from the original, but it is enough to be useful in some
way. Lossy data compression is used frequently on the Internet and mostly in streaming
media and telephony applications. In lossy data repeated compressing and decompressing,
a file will cause it to lose quality. Lossless when compared with lossy data compression
will retain the original quality, an efficient and minimum hardware implementation for the
data compression and decompression needs to be used even though there are so many
compression techniques which are faster, memory efficient which suits the requirements of
the user [1]. In the decompression phase of lossy image compression, the output images are
almost the same as the input images. In addition, this method is useful where a little
information from each pixel is important.
Lossless compression is to reconstruct the original data from the compressed file
without any loss of data. Thus, the information does not change during the compression
and decompression processes. These kinds of compression algorithms are called reversible
compressions since the original message is reconstructed by the decompression process.
Lossless compression techniques are used to compress medical images, text, and images
preserved for legal reasons, computer executable file and so on [2].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-16-320.jpg)
![Chapter 1 Introduction
2
The examples of the lossless compression techniques are run length encoding,
Huffman encoding, LZW coding, area coding, and Arithmetic coding [3]. In the lossless
compression scheme, after compression is numerically identical to the original image. It is
used in many applications such as ZIP file format & in UNIX tool zip. It is important when
the original & the decompressed data be identical. Some image file formats like PNG or
GIF use only lossless compression. Most lossless compression programs do two things in
sequence: the first step generates a statistical model for the input data, and the second step
uses this model to map input data to bit sequences in such a way that "probable" (e.g.
frequently encountered) data will produce shorter output than "improbable" data [4].
Discrete wavelet transform (DWT) is one of the wavelet transforms used in image
processing. DWT decomposes an image into different sub band images, namely low-low
(LL), low-high (LH), high-low (HL), and high-high (HH).
A recent wavelet transform which has been used in a several image processing
application that is the stationary wavelet transform (SWT).In short, SWT is similar to
DWT but it does not use down-sampling, hence the sub bands will have the same size as
the input image [6]. The stationary wavelet transform among the different tools of multi-
scale signal processing, the wavelet is a time-frequency analysis that has been widely used
in the field of image processing such as DE noising, compression, and segmentation.
Wavelet-based DE noising provides multi-scale treatment of noise, down-sampling of sub-
band images during decomposition, and the threes holding of wavelet coefficients may
cause edge distortion and artifacts in the reconstructed images [5].
Vector Quantization (VQ) is a block-coding technique that quantizes blocks of data
instead of single samples. VQ exploits the correlation between neighboring signal samples
by quantizing them together. VQ Compression contains two components: VQ encoder and
decoder as shown in Figure 1.1. At the encoder, the input image is portioned into a set of
non-overlapping image blocks. The closest code word in the code book is then found for
each image block. Here, the closest code word for a given block is the one in the code book
that has the minimum squared Euclidean distance from the input block. Next, the
corresponding index for each searched closest code word is transmitted to the decoder.
Compression is achieved because the indices of the closest code words in the code book
sent to the decoder instead of the image blocks themselves [7].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-17-320.jpg)
![Chapter 1 Introduction
3
Vector quantization (VQ) is a powerful method for image compression due to its
excellent rate-distortion performance and its simple structure. Some efficient clustering
algorithms are developed based on the VQ-like approach. However, the VQ algorithm still
employs a full search method to ensure the best-matched code word and consequently
results in the computational requirement is large. Therefore, many research efforts were
paid on simplifying the search complexity for the encoding process. These approaches are
further classified into two types in terms of simplified technique. One is the tree-structured
VQ (TSVQ) techniques, and the other is the triangular inequality elimination (TIE) based
approaches [8].
Figure 1.1: Vector quantization encoder and decoder
This thesis focuses on lossy compression because it is the most popular category in
real applications.
1.1 Lossy Compression
Lossy compression works very differently. These programs simply eliminate
"unnecessary" bits of information, tailoring the file so that it is smaller. This type of
compression is used a lot for reducing the file size of bitmap pictures, which tend to be
fairly bulky [9]. This may examine the color data for a range of pixels, and identifies subtle
variations in pixel color values that are so minute that the human eye/brain is unable to](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-18-320.jpg)
![Chapter 1 Introduction
4
distinguish the difference between them. The algorithm may choose a smaller range of
pixels whose color value differences fall within the boundaries of our perception, and
substitute those for the others. The Lossy compression framework is shown in Figure (1.2).
Figure 1.2: Lossy compression framework
To achieve this goal one of the following operations is performed. 1. Predicted image
is formed by predicting pixels based on the values of neighboring pixels of the original
image. Then the residual image is formed which is the difference between the predicted
image and the original image. 2. Transformation a reversible process that reduces
redundancy and/or provides an image representation that is more amenable to the efficient
extraction and coding of relevant information. 3. Quantization process compresses a range
of values to a single quantum value. When the number of discrete symbols in a given
stream is reduced, the stream becomes more compressible. Entropy coding is then applied
to achieve further compression. Major performance considerations of a lossy compression
scheme are: a) the compression ratio (CR), the signal-to noise ratio (PSNR) of the
reconstructed image with respect to the original, and c) the speed of encoding and
decoding [9].
We will use the following techniques in the Lossy compression process:
1.1.1 Transform Coding
Transform coding algorithm usually start by partitioning the original image into sub
images (blocks) of small size (usually 8 x 8). For each block the transform coefficients are
calculated, effectively converting the original 8 x 8 array of pixel values into an array of
coefficients closer to the top-left corner usually contains most of the information needed to
quantize and encode the image with little perceptual distortion. The resulting coefficients
Original Image
Data
Prediction/Transformat
ion/ Decomposition
Quantization
Modeling and
Encoding
Compressed Image](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-19-320.jpg)
![Chapter 1 Introduction
5
are then quantized and the output of the quantized issued by a symbol encoding technique
to produce the output bit stream representing the encoded image [9].
1.1.2 Vector Quantization
The vector quantization is a classical quantization technique for signal processing
and image compression, which allows the modelling of probability density functions by the
distribution of prototype vectors. The main use of vector quantization (VQ) is for data
compression [10] and [11]. It works by dividing a large set of values (vectors) into groups
having approximately the same number of points closest to them. Each group is
represented by its centroid value, as in LBG algorithm and some other algorithms [12].
The density matching property for vector quantization is powerful, especially in the
case for identifying the density of large and high dimensioned data. Since data points are
represented by their index to the closest centroid, commonly occurring data have less error
and rare data have higher error. Hence VQ is suitable for lossy data compression. It can
also be used for lossy data correction and density estimation. The methodology of vector
quantization is based on the competitive learning paradigm, hence it is closely related to
the self-organizing map model. Vector quantization (VQ) is used for lossy data
compression, lossy data correction and density estimation [12].
Our approach is considered a lossy compression technique that enhances lossy
compression technique by using stationary wavelet transform and vector quantization to
solve the major problems of lossy compression techniques.
1.2 Wavelet Transforms (WT)
Wavelets are signals which are local in time and scale and generally have an
irregular shape. A wavelet is a waveform of effect limited duration that has an average
value of zero. The term „wavelet‟ comes from the fact that they integrate to zero; they
wave up and down across the axis. Many wavelets also display a property ideal for
compact signal representation: orthogonally. This property ensures that data is not over
represented. A signal can be decomposed into many shifted and scaled representations of
the original mother wavelet. A wavelet transform can be used to decompose a signal into
component wavelets. Once this is done the coefficients of the wavelets can be decimated to](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-20-320.jpg)
![Chapter 1 Introduction
6
remove some of the details. Wavelets have the great advantage of being able to separate
the fine details in a signal. Very small wavelets can be used to isolate very fine details in a
signal, while very large wavelets can identify coarse details. In addition, there are many
different wavelets to choose from. Various types of wavelets are: Morlet, Daubechies, etc.
One particular wavelet may generate a more sparse representation of a signal than another,
so different kinds of wavelets must be examined to see which is most suited to image
compression [13].
1.2.1 Discrete Wavelet Transform (DWT)
The Discrete Wavelet Transform (DWT) of image signals produces a no redundant
image representation, which provides better spatial and spectral localization of image
formation, compared with other multi scale representations such as Gaussian and Laplacian
pyramid. Recently, Discrete Wavelet Transform has attracted more and more interest in
image fusion. An image can be decomposed into a sequence of different spatial resolution
images using DWT. In case of a 2D image, an N level decomposition can be performed,
resulting in 3N+1 different frequency bands and it is shown in Figure 1.3 Optimal
decomposition level of the discrete, stationary, and dual tree complex [14].
Figure 1.3: 2D-Discrete wavelet transforms](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-21-320.jpg)
![Chapter 1 Introduction
7
1.2.2 Lifting Wavelet Transform (LWT)
The lifting scheme (LS) has been introduced for the efficient computation of DWT
.For image compression, it is very necessary that the selection of transform should reduce
the size of the resultant data as compared to the original data set .So a new lossless image
compression method is proposed. Wavelet using the lifting scheme significantly reduces
the computation time, speed up the computation process. The lifting transforms even at its
highest level is very simple. The lifting transform can be performed via two operations:
Split, Predict and Update [15]. Suppose we have the one dimensional signal a0. The
Lifting is done by performing the following sequence of operations:
1.Split a0 into Even-1 and Odd-1
2. d-1 = Odd-1 – Predict (Even-1)
3. a-1 = Even-1 + Update( d-1 )
These steps are repeated to construct multiple scales of the transform. The wiring
diagram in Figure 1.4 shows the forward transform visually. The coefficients “a” are
representing the averages in the signal that is Approximation coefficient, while the
coefficients in “d” represent the differences in the signal that is Detailed Coefficient. Thus,
these two sets also correspond to the low- pass and high- pass frequencies present in the
signal [16].
Figure 1.4: Wire diagram of forward transformation with the lifting scheme](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-22-320.jpg)
![Chapter 1 Introduction
8
1.2.3 Stationary Wavelet Transform (SWT)
Among the different tools of multi-scale signal processing, wavelet is a time-frequency
analysis that has been widely used in the field of image processing such as denoising,
compression, and segmentation. Wavelet-based denoising provides multi-scale treatment of
noise, down-sampling of sub-band images during decomposition and the thresholding of wavelet
coefficients may cause edge distortion and artifacts in the reconstructed images. To improve the
limitation of the traditional wavelet transform, a multi-layer stationary wavelet transform (SWT)
was adopted in this study, as illustrated in Figure 1.5.
In Figure 1.5, Hj and Lj represent high-pass and low-pass filters at scale j, resulting
from the interleaved zero padding of filters Hj-1 and Lj-1 (j>1). LL0 is the original image
and the output of scale j, LLj, would be the input of scale j+1. LLj+1 denotes the low-
frequency (LF) estimation after the stationary wavelet decomposition, while LHj+1, HLj+1
and HHj+1 denote the high frequency (HF) detailed information along the horizontal,
vertical and diagonal directions, respectively [5].
Figure 1.5: Stationary wavelet decomposition of a two-dimensional image](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-23-320.jpg)
![Chapter 1 Introduction
9
These sub-band images would have the same size as that of the original image
because no down-sampling is performed during the wavelet transform. In this study, the
Haar wavelet was applied to perform multi-layer stationary wavelet transform on a 2D
image. Mathematically, the wavelet decomposition is defined as:
LLj+1(χ, γ) = L[n] L [m] LLj (2j+1 m- χ, 2j+1 n- γ)
LHj+1(χ, γ) = L[n] H [m] LLj (2j+1 m- χ, 2j+1 n- γ)
HLj+1(χ, γ) = H[n] L [m] LLj (2j+1 m- χ, 2j+1 n- γ)
HHj+1(χ, γ) = H[n] H [m] LLj (2j+1 m- χ, 2j+1 n- γ)
Where L[·] and H[·] represent the low pass and high pass filters respectively, and
LL0(X,Y)=F(X,Y)
Compare with the traditional wavelet transform, the SWT has several advantages.
First, each sub-band has the same size, so it is easier to get the relationship between the
sub-bands. Second, the resolution can be retained since the original data is not decimated.
Also at the same time the wavelet coefficients contain much redundant information which
helps to distinguish the noise from the feature. In this study, the image processing and
stationary wavelet transform are performed using MATLAB programming language. The
proposed method is tested using Standard images as well as image sets selected from Heath
et al.‟s library. For the sake of thoroughness, the developed method is compared with the
standard Sobel, Prewitt, Laplacian, and Canny edge detectors [5].
1.3 Problem Statement
The large increase in the data lead to delays in access to the information required and
this leads to a delay in the time. Large data lead to data units and storage is full this leads
to the need to buy a bigger space for storage and losing money. Large data lead to give
inaccurate results for the similarity of data and this leads to getting inaccurate information.
Also to show the difference between the types of transforms Stationary Wavelet
Transforms and Discrete Wavelet Transform and Lifting Wavelet Transform because they
are very similar at one level so we used three levels.
(1.1)](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-24-320.jpg)

![Chapter 2 Background and Literature Review
11
BACKGROUND AND LITERATURE REVIEW
This chapter offers some important background related to the proposed system that
including wavelet transform and vector quantization. It also introduces a taxonomy of
image compression techniques, and covers a literature review on image compression
algorithms.
2.1 Background
2.1.1 Compression Techniques
Compression techniques come in two forms: lossy and lossless. Generally a lossy
technique means that data are saved approximately rather than exactly. In contrast lossless
techniques save data exactly. They look for sequences that are identical and code these.
This type of compression has a lower compression rate than a lossy technique, but when
the file is recovered it is identical to the original. Generally speaking, Lossless data
compression is used as a component within lossy data compression technologies. Lossless
compression is used in cases where it is important that the original and the decompressed
data be identical, or where deviations from the original data could be deleterious. Typical
examples are executable programs, text documents, and source code. Lossless compression
methods may be categorized according to the type of data they are designed to compress.
While, in principle, any general-purpose lossless compression algorithm can be used on
any type of data, many are unable to achieve significant compression on data that are not
of the form for which they were designed to compress [18].
In lossless compression schemes, the reconstructed image, after compression, is
numerically identical to the original image. However, lossless compression can only
achieve a modest amount of compression. An image reconstructed following lossy
compression contains degradation relative to the original. Often this is because the
compression scheme completely discards redundant information. However, lossy schemes
are capable of achieving much higher compression. Under normal viewing conditions, no
visible loss is perceived (visually lossless). Table 1 describes the comparison between
loosy and lossless compression in some items [17].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-26-320.jpg)
![Chapter 2 Background and Literature Review
12
Table 2.1: Comparison between lossy and lossless compression techniques
Item Lossy Compression Lossless Compression
Reconstructed image
Contains degradation relative to
the original image.
Numerically identical to the
original image.
Compression rate
High compression (visually
lossless).
2:1 (at most 3:1).
Application
Music, photos, video, medical
images, scanned documents, fax
machines.
Databases, emails,
spreadsheets, office
documents, source code.
2.1.2 Lossy Compression Vector Quantization
Figure 2.1: Code words in 1-dimensional space
Vector quantization (VQ) is a lossy data compression method based on the principle
of block coding. It is a fixed-to-fixed length algorithm. A VQ is nothing more than an
approximate. The idea is similar to that of “rounding-off” (say to the nearest integer) [21]
and [22]. The following example shown in Figure 2.1 represents every number less than -2
is approximated by -3, all numbers between -2 and 0 are approximated by -1, every
number between 0 and 2 are approximated by +1, and every number greater than 2 are
approximated by +3. The approximate values are uniquely represented by 2 bits. This is a
1-dimensional, called 2-bit VQ. It has a rate of 2 bits/dimension. In the above example, the
stars are called code vectors [21].
A vector quantizer map k-dimensional vectors in the vector space a finite set of
vectors Y = {y: i = 1, 2, ... , N}. Each vector is called a code vector or a code word, and
the set of all the codewords is called a codebook. Associated with each codeword is a
nearest neighbor region called encoding region or Voronoi region [21] and [23] and it is
defined by:
| || || } ................................... (1)](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-27-320.jpg)
![Chapter 2 Background and Literature Review
13
The set of encoding region's partition, the entire space such that:
⋃ ⋂ .......................... (2)
Thus the set of all encoding regions is called the partition of the space. In the
following example, we take vectors in the two dimensional case without loss of generality
in Figure 2.1 In the figure, Input vectors are marked with an x, code words are marked with
solid circles, and the Voronoi regions are separated with boundary lines. The figure shows
some vectors in space. Associated with each cluster of vectors is a representative code
word. Each code word resides in its own Voronoi region. These regions are separated by
imaginary boundary lines in Figure 2.2 given an input vector; the code word that is chosen
to represent it is the one in the same Voronoi region. The representative code word is
determined to be the closest in Euclidean distance from the input vector [21].
The Euclidean distance is defined by:
√∑ ....................................... (3)
Where is the component of the input vector, and is the component of the
code word . In Figure 2.2 there are 13 regions and 13 solid circles, each of which can be
uniquely represented by 4 bits. Thus, this is a 2-dimensional, 4-bit VQ. Its rate is also 2
bits/dimension [21].
Figure 2.2: Code words in 2-dimensional space](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-28-320.jpg)
![Chapter 2 Background and Literature Review
14
A vector quantizer is composed of two operations. The first is the encoder, and the
second is the decoder [24]. The encoder takes an input vector and outputs the index of the
code word that offers the lowest distortion. In this case the lowest distortion is found by
evaluating the Euclidean distance between the input vector and each code word in the
codebook. Once the closest code word is found, the index of that code word is sent through
a channel (the channel could be computer storage, communications channel, and so on).
When the decoder receives the index of the code word, it replaces the index with the
associated code word. Figure 2.3 shows a block diagram of the operation of the encoder
and the decoder [21].
Figure 2.3: The Encoder and decoder in a vector quantizer
In Figure 2.3, an input vector is given, the closest code word is found and the index
of the code word is sent through the channel. The decoder receives the index of the code
word, and outputs the code word [21].
The drawback of vector quantization, this technique generates code book in very
slow speed than bpp [25].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-29-320.jpg)
![Chapter 2 Background and Literature Review
15
2.1.2.1 Linde-Buzo-Gray Algorithm:
Generalized Lloyd Algorithm (GLA), which is also called, Linde-Buzo-Gray (LBG)
Algorithm They used a mapping function to partition training vectors in N clusters. The
mapping function is defined as in [10].
→ CB
Let X = (x1, x2,…,xk) be a training vector and d(X, Y) be the Euclidean Distance
between any two vectors. The iteration of GLA for a codebook generation is given as
follows:
1. LBG algorithm
Step 1: Randomly generate an initial codebook CB0.
Step 2: i = 0.
Step 3: Perform the following process for each training vector.
Compute the Euclidean distances between the training vector and the
code words in . The Euclidean distance is defined as
∑ ................................... (4)
Search the nearest code word among .
Step 4: Partition the codebook into N cells.
Step 5: Compute the centroid of each cell to obtain the new codebook CBi+1.
Step 6: Compute the average distortion for CBi+1. If it is changed by a small
enough amount since the last iteration, the codebook may converge and
the procedure stops. Otherwise, i = i + 1 and go to Step 3 [10].
LBG algorithm has the local optimization problem and the utility of each codeword
in the codebook is low. The local optimization problem means that the codebook
guarantees local minimum distortion, but not global minimum distortion [29].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-30-320.jpg)
![Chapter 2 Background and Literature Review
16
Figure 2.4: Flowchart of Linde-Buzo-Gray Algorithm
2.1.2.2 Equitz Nearest Neighbor
The selection of initial codebook by the LBG algorithm is poor, which results in an
undesirable final codebook. Another algorithm Equitz Nearest neighbor (ENN) is used in
which no need for selection of initial codebook. As the beginning of ENN algorithm, all
training vectors are viewed as initial clusters (code vectors). Then, the two nearest vectors
are found and merged by taking their average. A new vector is formed which replaces and
reduce the number of clusters by one. The Process is going on until desired number of
clusters is not obtained [30].
The steps for the implementation of the ENN algorithm are as follows:
2. ENN Algorithm
1. Initially, all the image vectors taken as the initial codewords.
2. Find each of two nearest codewords by the equation:](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-31-320.jpg)
![Chapter 2 Background and Literature Review
17
Od (X, Yi) =k-1Σj=0|Xj–Yi, j|............................... (2.2)
Where “X” represents an input vector from the original image and “Y”
represents a codeword, and merge them by taking their average where “k”
represents the codeword length.
3. The new codeword replaces the two codeword and reduce the number of
codewords by one.
4. Repeat step 2 and step 3 until desired number of codewords is reached. The ENN
requires a long time and large number of iterations to design the codebook.
Therefore, to decrease the number of iterations and time required to generate the
codebook, an image block distortion threshold value (dth) is calculated [10].
The ENN algorithm is modified as:
1. Determine the desired number of codeword and the maximum number of gray
levels in the image (max–gray)
2. Distortion threshold (dth) is calculated as:
dth=k× (max-gray/64) ..................................... (5)
Where „k‟ is codeword length
3. Calculate the distortion error between a taken codeword and a next codeword. If
the distortion error is less than or equal to dth, then merge these two codeword
and reduce the number of codeword by one. Otherwise, consider the next
codeword.
4. Repeat the step 3 until we obtain the number of codewords equal to desired
number of codewords.
5. Even, after all the codewords are compared and merged, the resultant number of
codewords greater than desired number of codewords, then change the dth value
as follows
Dth=dth+k×(max-gray/256) .................................. (6)
And then go to step 3.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-32-320.jpg)
![Chapter 2 Background and Literature Review
18
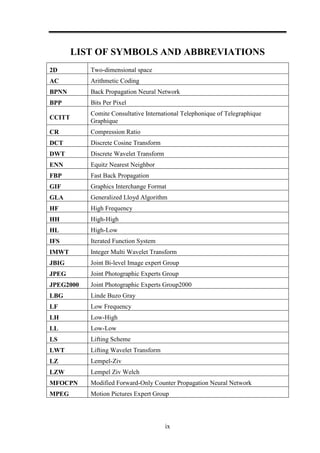
2.1.2.3 Back Propagation Neural Network Algorithm
BPNN algorithm helps to increase the performance of the system and to decrease the
convergence time for the training of the neural network [31]. BPNN architecture is used
for both image compression and also for improving VQ of images. A BPNN consists of
three layers: input layer, hidden layer and output layer. The number of neurons in the input
layer is equal to the number of neurons in the output layer. The number of neurons in the
hidden layer should be less than that of the number of neurons in the input layer. Input
layer neurons represent the original image block pixels and output layer neuron represents
the pixels of the reconstructed image block. The assumption in hidden layer neurons is that
the arrangement is in one-dimensional array of neurons, which represents the element of
codeword. This process produces an optimal VQ codebook. The source image is divided
into non-overlapping blocks of pixels such that block size equals the number of input layer
neurons and the number of hidden layer neurons equals the codeword length. In the BP
algorithm, to design the codebook, the codebook is divided into rows and columns in
which rows represent the number of patterns of all images and columns represents the
number of hidden layer units [10].
Figure 2.5: Back propagation neural network image compression system
The implementation of BPNN VQ encoding can be summarized as follows:](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-33-320.jpg)
![Chapter 2 Background and Literature Review
19
2. BPNN algorithm
1. Divide the source image into non-overlapping blocks with predefined block
dimensions (P), where (P×P) equals the number of neurons in the input layer.
2. Take one block from the image, normalize it, convert the image into pixels
(rasterizing), and apply it to the input layer neurons of BPNN.
3. Execute one iteration BP in the forward direction to calculate the output of
hidden layer neurons.
4. From the codebook file, find the codeword that best matches the outputs of
hidden layer neurons.
5. Store index i.e. position of this codeword in codebook in the compressed version
of source image file.
6. For all the blocks of source image, repeat the steps from step2 to step5 [10].
Number of bits required for indexing each block equals to log2M, where M is
codebook length.
The implementation of BPNN VQ decoding process can be described as follows:
1. Open compressed VQ file
2. Take one index from this file.
3. This index is then replaced by its corresponding codeword which is obtained
from the codebook and this codeword is assumed to be the output of hidden layer
neurons.
4. Execute one iteration BP in the forward direction to calculate the output of the
output layer neurons, then de-rasterizing it, de-normalize it and store this output
vector in a decompressed image file.
5. Repeat steps from step2 to step4 until the end of the compressed file.
The BP algorithm is used to train the BPNN network to obtain the codebook with
smaller size with improved performance of the system. The BPNN image compression
system has the ability to decrease the errors that occur during transmission of compressed
images through analog or digital channel. Practically, we can note that BPNN has the
ability to enhance any noisy compressed image that has been corrupted during compressed
image transmission through a noisy digital or analog channel. BPNN has the capacity to](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-34-320.jpg)
![Chapter 2 Background and Literature Review
20
compress untrained images, but not in the same performance of trained images. This can be
done, especially when using a small number of image block dimension [33].
2.1.2.4 Fast Back Propagation Algorithm
The FBP algorithm is used for training the designed BPNN to reduce the
convergence time of BPNN as possible as. The fast back propagation (FBP) algorithm is
based on the minimization of an objective function after initial adaption cycles. This
minimization can be obtained by reducing lambda (λ) from unity to zero during network
training. The FBP algorithm differs from standard BP algorithm in the development of
alternative training criterion. This criterion indicates that (λ) must change from 1 to 0
during training process i.e. λ approaches to zero as total error decreases. In each adaption
cycle, λ should be calculated from the total error at that point, according to the equation:
λ=λ (E), where E is error of network, indicates that λ≈1 when E˃˃1.When E˃˃1 for any
positive integer n, 1/En approaches zero, therefore exp(-1/En) ≈1. When E˂˂1, 1/En is
very large, therefore exp(-1/En)≈0. As a result, for the reduction of λ from 1 to 0, a suitable
rule is as follows [32]:
λ=λ(E)= exp (-μ/En).....................................(7)
Where μ is a positive real number and n is a positive integer. When n is small,
reduction of λ is faster, when E˃˃1. It has been experimentally verified that if λ is much
smaller than unity during initial adaption cycles, algorithm may be trapped in local
minimum. So, n should be greater than 1.
Thus, λ is calculated during any network training according to equ. 6[32]:
λ = λ(E)=exp(-μ/E2).......................................(8)
In the FBP algorithm, all the hidden layer neurons and output layer neurons use
hyperbolic tangent function instead of sigmoid functions in the BPNN architecture. So, the
equation is modified for hyperbolic tangent function as follows [32]:
F (NET j)= ( J - J) / ( J - J)............... (9)
And derivative of this function is as follows:
F(׳NET j)=(1-(F(NETj)2).........................................(10)
So that F (NET j) lies between -1 and 1.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-35-320.jpg)
![Chapter 2 Background and Literature Review
22
2.1.2.5 Joint Photopphic Experts Group
JPEG stands for Joint Photopphic Experts Group, it is indeed one of the most used
standards in the field of the compression of photographic images and it was created at the
beginning of the 90s. It tums out moreover very competitive when it is used in a weak or
an average compression ratios. But the mediocre quality of the obtained images in a higher
compression ratio as well as its lack of flexibility and features gave a clear evidence of its
incapability to satisfy all the application requirements in the field of the digital image
processing. Based on those facts, members of the PEG group recovered to develop a new
standard for image coding offering more flexibility and functionalities: JPEG2000 [69].
2. Joint Photopphic Experts Group (JPEG) Algorithm
The algorithm behind JPEG is relatively straightforward and can be explained
through the following steps [70]:
1. Take an image and divide it up into 8-pixel by 8-pixel blocks. If the image
cannot be divided into 8-by-8 blocks, then you can add in empty pixels around
the edges, essentially zero-padding the image.
2. For each 8-by-8 block, get image data such that you have values to represent the
color at each pixel.
3. Take the Discrete Cosine Transform (DCT) of each 8-by-8 block.
4. After taking the DCT of a block, matrix multiply the block by a mask that will
zero out certain values from the DCT matrix.
5. Finally, to get the data for the compressed image, take the inverse DCT of each
block. All these blocks are combined back into an image of the same size as the
original.
As it may be unclear why these steps result in a compressed image, I'll now explain
the mathematics and the logic behind the algorithm [70].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-37-320.jpg)
![Chapter 2 Background and Literature Review
23
2.1.2.6 JPEG2000
A. Historic : With the continual expansion of multimedia and Internet applications, the
needs and requirements of the technologies used, grew and evolved In March 1997 a
new call for contributions were launched for the development of a new standard for the
compression of still images, the JPEG2000 [69]. This project, JTC2 1.29.14 (15444),
was intended to create a new image coding system for different types of still images
(bi-level, gray-level, color, multicomponent). The standardization process, which is
coordinated by the JTCI/SC29/WGI of ISO/lEC3, has produced the Final Draft
International Standard (FDIS') in August 2000. The International Standard (Is) was
ready by December 2000. Only editorial changes are expected at this stage and
therefore, there will be no more technical or functional changes in Part 1 of the
Standard
B. Characteristics and features: The purpose of having a new standard was twofold.
First, it would address a number of weaknesses in the existing standard second, it
would provide a number of new features not available in the JPEG standard The
preceding points led to several key objectives for the new standard, namely that it
should enclose [69]:
1) Superior low bit-rate performance,
2) Lossless and lossy compression in a single code-stream,
3) Continuous-tone and bi-level compression,
4) Progressive transmission by pixel accuracy and resolution,
5) Fixed-rate, fixed-size,
6) Robustness to bit errors,
7) Open architecture,
8) Sequential build-up capability,
9) Interface with MPEG-4,
10) Protective image security,
11) Region of interest](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-38-320.jpg)
![Chapter 2 Background and Literature Review
24
2.1.3 Lossless Compression Techniques
The extremely fast growth of data that needs to be stored and transferred has given
rise to the demands of better transmission and storage techniques. Lossless data
compressions categorized into two types are: models & code and dictionary models.
Various lossless data compression algorithms have been proposed and used. Huffman
Coding, Arithmetic Coding, Shannon Fano Algorithm, Run Length Encoding Algorithm
are some of the techniques in use [34].
2.1.3.1 Models and Code
Model code divided to Huffman coding and Arithmetic coding
2.1.3.1.1 Huffman Coding
A first Huffman coding algorithm was developed by David Huffman in 1951.
Huffman coding is an entropy encoding algorithm used for lossless data compression. In
this algorithm fixed length codes are replaced by variable length codes. When using
variable-length code words, it is desirable to create a prefix code, avoiding the need for a
separator to determine codeword boundaries. Huffman Coding uses, such prefix code [34].
Huffman procedure works as follow:
1. Symbols with a higher frequency are expressed using shorter encodings than
symbols which occur less frequently.
2. The two symbols that occur least frequently will have the same length.
The Huffman algorithm uses the greedy approach i.e. at each step the algorithm
chooses the best available option. A binary tree is built up from the bottom up.
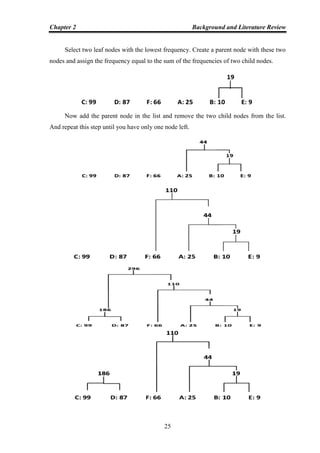
To see how Huffman Coding works, let‟s take an example. Assume that the
characters in a file to be compressed have the following frequencies:
A: 25 B: 10 C: 99 D: 87 E: 9 F: 66
The processing of building this tree is:
Create a list of leaf nodes for each symbol and arrange the nodes in the order from
highest to lowest.
C: 99 D:87 F:66 A:25 B:10 E:9](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-39-320.jpg)
![Chapter 2 Background and Literature Review
26
Now label each edge. The left child of each parent is labeled with the digit 0 and
right child with 1. The code word for each source letter is the sequence of labels along the
path from root to the leaf node representing the letter.
Huffman Codes are shown below in the table [34].
Table 2.3: Huffman Coding
C 00
D 01
F 10
A 110
B 1110
E 1111
2. Huffman Encoding Algorithm
Huffman Encoding Algorithm [52].
Huffman (W, n) //Here, W means weight and n is the no. of inputs
Input: A list W of n (Positive) Weights.
Output: An Extended Binary Tree T with Weights Taken from W that gives the
minimum weighted path length.
Procedure: Create list F from singleton trees formed from elements of W.
While (F has more than 1 element) do
Find T1, T2 in F that have minimum values associated with their roots // T1 and T2
are sub tree .
Construct new tree T by creating a new node and setting T1 and T2 as its children
Let, the sum of the values associated with the roots of T1 and T2 be associated with
the root of T Add T to F
Do Huffman-Tree stored in the F](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-41-320.jpg)
![Chapter 2 Background and Literature Review
27
2.1.3.1.2 Arithmetic Coding
Arithmetic coding (AC) is a statistically lossless encoding algorithm with very high
compression efficiency and is especially useful when dealing with the source with an
alphabet of small size. Nowadays, AC is widely adopted in the image and video coding
standards, such as JPEG2000 [22] and [39]. Recent researches on secure arithmetic coding
primary focus on the two approaches: the interval splitting AC (ISAC) and the randomized
AC (RAC). In [40] and [41], the strategy of key-based interval splitting had been
successfully incorporated with arithmetic coding to construct a novel coder with the
capabilities of compression and encryption. This approach has been studied deeply just for
the floating-point arithmetic coding over the past few years. On compression efficiency,
the authors illustrated that even the interval is just split (the total length kept unchanged) in
an arithmetic coder, the code length will raise a little relative to the floating-point
arithmetic coding [42] analyzed that the key-based interval splitting AC is vulnerable to
known-plaintext attacks [43]. Further used message in distinguishability to prove that
ISAC is still insecure under [36].
Cipher text-only attacks even under the circumstance that different keys are used to
encrypt different messages. In order to enhance the security, [44] provided an extended
version of ISAC, called Secure Arithmetic Coding (SAC), which applies two permutations
to the input symbol sequence and the output codeword. However,[45] and [46]
independently proved that it is still not secure under the chosen-plaintext attacks and
known-plaintext attacks due to the regularities of permutations steps [47] presented a
randomized arithmetic coding (RAC) algorithm, which achieves the capability of
encryption by randomly swapping two symbol intervals during the process of binary AC.
Although RAC does not suffer any loss of compression efficiency, its security problem
does exist [48] proved that it is vulnerable to cipher-only attacks.
Recently [49] presented a secure integer AC scheme (here called MIAC) that performs
the compression and the encryption simultaneously. In this scheme, the size ratio D𝛼1,+1/λn of
interval allocated to the symbol 𝛼1 will be far approximated to the probability P(𝛼1) and the
size ratios D𝛼1,n+1/λn of interval allocated to the symbol 𝛼i will be far approximated to the
probability P(𝛼i). In this paper, we further try to propose another secure arithmetic coding
scheme with good compression efficiency and highest secrecy.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-42-320.jpg)
![Chapter 2 Background and Literature Review
28
Illustrated Example of Arithmetic Encoding
Arithmetic Coding works, let‟s take an example, we have a string:
BE_A_BEE
And we now compress it using arithmetic coding.
Step 1: in the first step we do is look at the frequency count for the different letters:
E B _ A
3 2 2 1
Step 2: In the second step we encode the string by dividing up the interval [0, 1] and
allocate each letter an interval whose size depends on how often it count in the string. Our
string start with a‟B‟, so we take the „B‟ interval and divide it up again in the same way:
The boundary between „BE‟ and „BB‟ is 3/8 of the way along the interval, which is
itself 2/3 long and starts at 3/8. So boundary is 3/8 + (2/8) * (3/8) = 30/64. Similarly the
boundary between „BB‟ and „B_‟ is 3/8+ (2/8) * (5/8) = 34/64, and so on. [51].
Step 3: In the third step we see next letter is now „E‟, so now we subdivide the”E‟
interval in the same way. We carry on through the message….And, continuing in this way,
we eventually obtain:](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-43-320.jpg)
![Chapter 2 Background and Literature Review
29
And continuing in this way, we obtain:
So we represent the message as any number in the interval
[7653888/16777216, 7654320/16777216]
However, we cannot send numbers like 7654320/16777216 easily using a computer.
In decimal notation, the rightmost digit to the left of the decimal point indicates the number
of units; the one to its left gives the number of tens: the next one along gives the number of
hundred, and so on.
7653888 = (7*106) + (6*105) + (5*104) + (3*103) + (8*102) + (8*10) + 8
Binary numbers are almost exactly the same, we only deal with powers of 2 instead
of power of 10. The rightmost digit of a binary number is unitary (as before) the one to its
left gives the number of 2s, the next one the number of 4s, and so on.
110100111 = (1*28) + (1*27) + (0*26) + (1*25) + (0*24) + (0*23) + (1*22) +
(1*21) + 1 = 256 + 128 + 32 + 4 + 2 + 1 = 423 in denary (i.e. base 10) [51].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-44-320.jpg)
![Chapter 2 Background and Literature Review
30
2. Arithmetic Encoding Algorithm
BEGIN
low = 0.0; high = 1.0; range = 1.0;
While (symbol i= terminator)
{
get (symbol) ;
Low = low + range * Range_low (symbol);
Low = low + range * Range_high (symbol);
range = high – low;
}
Output a code so that low <= code < high;
END
Huffman Coding Algorithm uses a static table for the whole coding process, so it is
faster. However, it does not produce efficient compression ratios. On the contrary,
Arithmetic algorithm can generate a high compression ratio, but its compression speed is
slow [34]. Table 2.4 presents a simple comparison between these compression methods.
Table 2.4: Huffman coding vs. Arithmetic coding
Compression Method Arithmetic Huffman
Compression ratio Very good Poor
Compression speed Slow Fast
Decompression speed Slow Fast
Memory space Very low Low
Compressed pattern matching No Yes
Permits Random access No Yes
Input Variable Fixed
Output Variable Variable](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-45-320.jpg)
![Chapter 2 Background and Literature Review
31
2.1.3.2 Dictionary Model
Dictionary model divided to Lempel Ziv Welch, Run length encoding and Fractal
encoding
2.1.3.2.1 Lempel Ziv Welch :
Lempel–Ziv–Welch Coding: Lempel–Ziv–Welch (LZW) is a universal lossless data
compression algorithm created by Abraham Lempel, Jacob Ziv, and Terry Welch. It was
published by Welch in 1984 as an improved implementation of the LZ78 algorithm
published by Lempel and Ziv in 1978. LZW is a dictionary based coding. Dictionary based
coding can be static or dynamic. In the static dictionary coding, the dictionary is fixed
when the encoding and decoding processes. In dynamic dictionary coding, dictionary is
updated on the fly. The algorithm is simple to implement, and has the potential for very
high throughput in hardware implementations. It was the algorithm of the widely used
UNIX file compression utility compress, and is used in the GIF image format. LZW
compression became the first widely used universal image compression method on
computers. A large English text file can typically be compressed via LZW to about half its
original size [35].
3. LZW Encoding Algorithm
LZW Encoding Algorithm [52].
Step 1: At the start, the dictionary contains all possible roots, and P is empty;
Step 2: C: = next character in the char stream;
Step 3: Is the string P+C present in the dictionary?
(a) if it is, P := P+C (extend P with C);
( b) if not,
– output the code word which denotes P to the code stream;
– add the string P+C to the dictionary;
– P := C (P now contains only the character C); (c) Are there more
characters in the char stream?](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-46-320.jpg)
![Chapter 2 Background and Literature Review
32
– if yes, go back to step 2;
– if not:
Step 4: Output the code word which denotes P to the code stream;
Step 5: END.
2.1.3.2.2 Run Length Encoding
Run Length Encoding (RLE) is the simplest of the data compression algorithms. It
replaces runs of two or more of the same characters with a number which represents the
length of the run, followed by the original character. Single characters are coded as runs of
1. The major task of this algorithm is to identify the runs of the source file, and to record
the symbol and the length of each run. The Run Length Encoding algorithm uses those
runs to compress the original source file while keeping all the non-runs without using for
the compression process [34].
Example of RLE:
Input: AAABBCCCCD
Output: 3A2B4C1D
4. Run Length Encoding Algorithm
Input: Original Image
Output: Encoding Image
Step1: i 0, j0,k0,Prev””
Step2: while (Image[i][j]) do
If(Image[i][j]) ≠ Prev)
Encoding Encoding . k
else
kk+1
Step3: return Encoding](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-47-320.jpg)
![Chapter 2 Background and Literature Review
33
2.1.3.2.3 Fractal Encoding
The essential idea here is to decompose the image into segments by using standard
image processing techniques such as color separation, edge detection, and spectrum and
texture analysis. Then each segment is looked up in a library of fractals. The library
actually contains codes called iterated function system (IFS) codes, which are compact sets
of numbers. This scheme is highly effective for compressing images that have good
regularity and self-similarity [50].
5. Fractal Encoding Algorithm
Procedure compression (N×N Image)[68]
begin
Partition the image into blocks of M×M; (M<N)
Keep each block unmarked initially;
For each unmarked block Bi (i=1 to N2/M2)
Begin
Mark the block Bi;
Add block Bi to the block pool;
Assign a unique sequence number to the block Bi;
Attach the indices for the location of Bi in the
source image with block Bi in block pool;
Attach „00‟ as transformation code with this location;
For each unmarked block Bj (j=i+1 to N2/M2)
Begin
If(Bi==Bj)
begin
Mark the block Bj;
Attach the indices for the location of Bj in the
source image with block Bi in block pool;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-48-320.jpg)


![Chapter 2 Background and Literature Review
36
Table 2.5: Summarizing the advantages and disadvantages of various lossless
compression algorithms
Techniques Advantages Disadvantages
1. Run Length
Encoding
This algorithm is easy to
implement and does not require
much CPU horsepower [3].
RLE compression is only efficient
with files that contain lots of
repetitive data [3].
2.Fractal Encoding
This technique includes Good
mathematical Encoding-frame
[25].
But this technique has slow
Encoding [25].
3.LZW Encoding
Simple, fast and good
compression [37].
Dynamic codeword table built for
each file [37].
Decompression recreates the
codeword table so it does not need
to be passed [37].
Many popular programs such as
the UNIX-based, gzip and gunzip,
and the Windows-based WinZip
program, are based on the LZW
algorithm [3].
Actual compression hard to predict
Jindal [37].
It occupies more storage space that
is not the optimum compression
ratio [37].
LZW algorithm works only when
the input data is sufficiently large
and there is sufficient redundancy
in the data [3].
4.Arithmetic
Encoding
Its ability to keep the coding and
the modeler separate [38].
No code tree needs to be
transmitted to the receiver [38].
Its use the fractional values [38].
Arithmetic coding have complex
operations because it consists of
additions, subtractions,
multiplications, and divisions [38].
Arithmetic coding significantly
slower than Huffman coding, there
are no infinite precision [38].
Two issues structures to store the
numbers and the constant division
of the interval may result in code
overlap [38].
5.Huffman
Encoding
This compression algorithm is
very simple and efficient in
compressing text or program files
[37].
This technique shows shorter
sequences for more frequently
appearing characters [3].
Prefix-free: no bit sequence
encoding of a character is the
prefix of any other bit-sequence
encoding [3].
An image that is compressed by
this technique is better compressed
by other compression algorithms
[37].
Code tree also needs to be
transmitted as well as the message
(unless some code table or
prediction table is
agreed upon between sender and
receiver) [3].
Whole data corrupted by one
corrupt bit [3].
Performance depends on good
estimate if the estimate is not
better than performance is poor
[3].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-51-320.jpg)
![Chapter 2 Background and Literature Review
37
2.1.4 Wavelet Transform
Often signals we wish to process are in the time-domain, but in order to process them
more easily other information, such as frequency, is required [26]. Wavelet analysis can be
used to divide the information of an image into approximation and detail sub signals. The
approximation sub signal shows the general trend of pixel values, and three detail sub
signals show the vertical, horizontal and diagonal details or changes in the image. It is
enough to retain the detail sub signals alone for the image, thus leading to compression
[26] and [27].
The original image is given as input to the Wavelet Transform and the outcomes of
the wavelet are four sub bands, namely LL, HL, LH and HH [26]. To get the fine details of
the image, the image can be decomposed into many levels. A first level of decomposition
of the image is given in Figure. 2.6.
Figure 2.6: First level wavelet decomposition
LL - Low frequency sub band.
HL - High frequency sub band.
LH - High frequency sub band of the vertical details of the image.
HH - High frequency sub-band of the diagonal details of the image.
The fundamental idea behind wavelets is to analyze according to scale [19]. Wavelet
algorithms process data at different scales or resolutions. If we look at a signal with a large
“window” we would notice gross features. Similarly, if we look at a signal with a small
“window” we would notice small features. The result of wavelet analysis is to see both the](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-52-320.jpg)
![Chapter 2 Background and Literature Review
38
forest and the trees, so to speak. Wavelets are well-suited for approximating data with
sharp discontinuities. The wavelet analysis procedure is to adopt a wavelet prototype
function, called an analyzing wavelet or mother wavelet [19].
Dilations and translations of the “Mother function,” or “analyzing wavelet” );(x
define an orthogonal basis, our wavelet basis [19] and [20]:
(11)lx2Φ2(x)Φ s2
s
l)(s,
The variables sand l are integers that scale and dilate the mother function to
generate wavelets, such as a Daubechies wavelet family. The scale index s indicates the
wavelet's width, and the location index l gives its position. The mother functions are
rescaled, or “dilated” by powers of two, and translated by integers. What makes wavelet
bases, especially interesting is the self-similarity caused by the scales and dilations. Once
we know about the mother functions, we know everything about the basis. To span our
data domain at different resolutions, the analyzing wavelet is used in a scalar equation:
(12)k2xΦC1W(x) 1k
k2N
1k
Where )(xW is the scaling function for the mother function ; and kc are the wavelet
coefficients. The wavelet coefficients must satisfy linear and quadratic constraints of the form:
1
0
l,0
1
0
(13)2,2
N
k
lk
N
k
k ccc
Where is the delta function and l is the location index. Temporal analysis is
performed with a contracted, high-frequency version of the prototype wavelet, while
frequency analysis is performed with a dilated, low-frequency version of the same wavelet.
Because the original signal or function can be represented in terms of a wavelet expansion
(using coefficients in a linear combination of the wavelet functions), data operations can be
performed using just the corresponding wavelet coefficients; and if you further choose the
best wavelets adapted to your data, or truncate the coefficients below a threshold, your data
are sparsely represented. This sparse coding makes wavelets an excellent tool in the field
of data compression [19] and [20].](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-53-320.jpg)
![Chapter 2 Background and Literature Review
39
Table 2.6: Advantages and disadvantages of wavelet transform
Method Advantages Disadvantages
Wavelet
Transform
High Compression Ratio
Coefficient quantization
Bit allocation
In PSNR values v. good CPU Time high
Chapter 1 described the definition of wavelet transforms techniques such as:
stationary wavelets transform (SWT), discrete wavelets transform (DWT), and lifting
wavelets transform (LWT). In the next section, we present the usage of wavelets
transforms in image compression.
2.2 Literature Review of Various Techniques of Data
Compression:
2.2.1 Related Work
S. Shanmugasundaram et al presents A Comparative Study of Text
Compression Algorithms [67]. They provide a survey of different basic lossless data
compression algorithms. Experimental results and comparisons of the lossless compression
algorithms using Statistical compression techniques and Dictionary based compression
techniques were performed on text data. Among the statistical coding techniques the
algorithms such as Shannon-Fano Coding, Huffman coding, Adaptive Huffman coding,
Run Length Encoding and Arithmetic coding are considered. Lempel Ziv scheme which is
a dictionary based technique is divided into two families: those derived from LZ77 (LZ77,
LZSS, LZH and LZB) and those derived from LZ78 (LZ78, LZW and LZFG). In the
Statistical compression techniques, Arithmetic coding technique outperforms the rest with
an improvement of 1.15% over Adaptive Huffman coding, 2.28% over Huffman coding,
6.36% over Shannon-Fano coding and 35.06% over Run Length Encoding technique. LZB
outperforms LZ77, LZSS, and LZH to show a marked compression, which is a 19.85%
improvement over LZ77, 6.33% improvement over LZSS and 3.42% improvement over
LZH, amongst the LZ77 family. LZFG shows a significant result in the average BPC
compared to LZ78 and LZW. From the result, it is evident that LZFG has outperformed the
other two with an improvement of 32.16% over LZ78 and 41.02% over LZW.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-54-320.jpg)
![Chapter 2 Background and Literature Review
40
Jau-Ji Shen et al presents vector quantization based image compression
technique [53]. They adjust the encoding of the difference map between the original image
and after that it‟s restored in VQ compressed version. Its experimental results show that
although there scheme needs to provide extra data, it can substantially improve the quality
of VQ compressed images, and further be adjusted depending on the difference map from
the lossy compression to lossless compression.
Architecture
Figure 2.7: Conceptual diagram of the difference map generated by the VQ compressed
The steps are as follows:
Input: I, k
Output: Compressed code
Step 1: Compress image I by VQ compression to obtain index table IT, and use IT
to restore image I‟.
Step 2: Subtract I from I‟ to get the difference map D.
Step 3: Let threshold be k, change values between +-k to zero in the difference map
D, let the new difference map be D‟.
Step4: Compress IT and D‟by arithmetic coding to generate compressed code of
image I‟ k is the threshold value which used to adjust the distortion level,
and compression turns lossless when k = 0.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-55-320.jpg)
![Chapter 2 Background and Literature Review
41
Yi-Fei Tan, et al presents image compression technique based on utilizing
reference points coding with threshold values [57]. This approach intends to bring
forward an image compression method which is capable to perform both lossy and lossless
compression. A threshold value is associated in the compression process, different
compression ratios can be achieved by varying the threshold values and lossless
compression is performed if the threshold value is set to zero. The proposed method allows
the quality of the decompressed image to be determined during the compression process. In
this method If the threshold value of a parameter in the proposed method is set to 0, then
lossless compression is performed. Lossy compression is achieved when the threshold
value of a parameter assumes positive values. Further study can be performed to calculate
the optimal threshold value T that should be used.
S. Sahami, et al presents bi-level image compression techniques using neural
networks [58]. It is the lossy image compression technique. In this method, the locations
of pixels of the image are applied to the input of a multilayer perceptron neural network .
The output the network denotes the pixel intensity 0 or 1. The final weights of the trained
neural-network are quantized, represented by few bites, Huffman encoded and then stored
as the compressed image. Huffman encoded and then stored as the compressed image. In
the decompression phase, by applying the pixel locations to the trained network, the output
determines the intensity. The results of experiments on more than 4000 different images
indicate higher compression rate of the proposed structure compared with the commonly
used methods such as committee consultative international telephone of telegraphic
graphique (CCITT) G4 and joint bi-level image expert group (JBIG2) standards. The
results of this technique provide High compression ratios as well as high PSNRs were
obtained using the proposed method. In the future they will use activity, pattern based
criteria and some complexity measures to adaptively obtain high compression rate.
Architecture
In Figure. 2.8 demonstrates block diagram of the proposed method in the compression
phase. As shown, a multi-layer perception neural network with one hidden layer is
employed.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-56-320.jpg)
![Chapter 2 Background and Literature Review
42
Figure 2.8: Block diagram of the proposed method (compression phase)
C. Rengarajaswamy, et al presents a novel technique in which done encryption and
compression of an image [59]. In this method stream cipher is used for encryption of an image
after that SPIHT is used for image compression. In this paper stream cipher encryption is carried
out to provide better encryption used. SPIHT compression provides better compression as the
size of the larger images can be chosen and can be decompressed with the minimal or no loss in
the original image. Thus high and confidential encryption and the best compression rate have
been energized to provide better security the main scope or aspiration of this paper is achieved.
Architecture
Figure 2.9: Block Diagram of the proposed system
Pralhadrao V Shantagiri, et al presents a new spatial domain of lossless image
compression algorithm for synthetic color image of 24 bits [61]. This proposed algorithm use
reduction of size of pixels for the compression of an image. In this the size of pixels is reduced
by representing pixel using the only required number of bits instead of 8 bits per color. This
proposed algorithm has been applied on asset of test images and the result obtained after
applying algorithm is encouraging. In this paper they also compared to Huffman, TIFF, PPM-](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-57-320.jpg)
![Chapter 2 Background and Literature Review
43
tree, and GPPM. In this paper, they introduce the principles of PSR (Pixel Size Reduction)
lossless image compression algorithm. They also had shown the procedures of compression and
decompression of their proposed algorithm.
S. Dharanidharan, et al presents a new modified international data encryption
algorithm using in Image Compression Techniques [63]. To encrypt the full image in an
efficient, secure manner and encryption after the original file will be segmented and converted to
other image file. By using Huffman algorithm the segmented image files are merged and they
merge the entire segmented image to compress into a single image. Finally, they retrieve a fully
decrypted image. Next they find an efficient way to transfer the encrypted images to multipath
routing techniques. The above compressed image has been sent to the single pathway and now
they enhanced with the multipath routing algorithm, finally they get an efficient transmission and
reliable, efficient image.
2.2.2 Previous Work
M. Mozammel et al presents Image Compression Using Discrete Wavelet
Transform. This research suggests a new image compression scheme with pruning
proposal based on discrete wavelet transformation (DWT) [64]. The effectiveness of the
algorithm has been justified over some real images, and the performance of the algorithm has
been compared to other common compression standards. The experimental results it is evident
that, the proposed compression technique gives better performance compared to other
traditional techniques. Wavelets are better suited to time-limited data and wavelet based
compression technique maintains better image quality by reducing errors [64].
Architecture
Figure 2.10: The structure of the wavelet transforms based compression](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-58-320.jpg)
![Chapter 2 Background and Literature Review
44
Tejas S. Patel et al presents Image Compression Using DWT and Vector
Quantization [65]. DWT and Vector quantization technique are simulated. Using different
codebook size, we apply DWT-VQ technique and Extended DWT-VQ (Which is the modified
algorithm) on various kinds of images. Today is the most famous technique for compression is
JPEG. JPEG achieves compression ratios of 2.4 up to 144. If we want high quality then JPEG
provides 2.4 compression ratio and if we can compromise with quality then it will provide 144.
The proposed system provides 2.97 to 6.11 compression ratio with high quality in the sense of
information loss. Though if we consider time as a cost, then our proposed system required more
time because counting differential matrix is time consuming, but this defect can be removed if
we provide efficient hardware component for our proposed system.
Architecture
Figure 2.11: Extended Hybrid System of DWT-VQ for Image Compression
Steps:
1. Apply the DWT transform on the original image and got four bands of original
image LL, LH, HL, HH.
2. Then apply the preprocess step as below.
a. First partition the LH, HL, HH bonds into the 4x4 block.
b. Compute the mean of each block.
c. Subtract the mean of block from each element of that block and result is
difference matrix.
3. Now apply the Vector Quantization on this difference matrix. With codebook
there is also pass mean of each block to decoder side.
Osamu Yamanaka et al present Image compression Using Wavelet Transform
and Vector Quantization with Variable block Size [66]. They introduced discrete
wavelet transform (DWT) to vector quantization (VQ) for image compression. DWT is
multi-resolution analysis, and signal energy concentrates to specific DWT coefficients.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-59-320.jpg)
![Chapter 2 Background and Literature Review
45
This characteristic is useful for image compression. DWT coefficients are compressed
using VQ with variable block size. To perform effective compression, blocks are merged
by the algorithm proposed. Results of computational experiments show that the proposed
algorithm is effective for VQ with variable block size.
B Siva Kumar et al presents Discrete and Stationary Wavelet Decomposition for
IMAGE Resolution Enhancement [6]. An image resolution enhancement technique based on
the interpolation of the high frequency sub-band images obtained by discrete wavelet transforms
(DWT) and the input image. The edges are enhanced by introducing an intermediate stage by
using stationary wavelet transform (SWT). DWT is applied in order to decompose an input
image into different sub-bands. Then the high frequency sub-bands as well as the input image are
interpolated. The estimated high frequency sub-bands are being modified by using high
frequency sub-band obtained through SWT. Then all these sub-bands are combined to generate a
new high resolution image by using inverse DWT (IDWT). The proposed technique uses DWT
to decompose an image into different sub bands, and then the high frequency sub band images
have been interpolated. The interpolated high frequency sub band coefficients have been
corrected by using higher frequency sub bands achieved by Stationary Wavelet transform (SWT)
of the input image. An original image is interpolated with half of the interpolation factor used for
interpolation the high frequency sub bands. Afterwards all these images have been combined
using IDWT to generate a super resolved imaged.
Architecture
Figure 2.12: Block diagram of the proposed super resolution algorithm](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-60-320.jpg)
![Chapter 2 Background and Literature Review
46
Suresh Yerva, et al presents the approach of the lossless image compression
using the novel concept of image folding [54]. The proposed method uses the property of
adjacent neighbor redundancy for the prediction. In this method, column folding followed
by row folding is applied iteratively on the image till the image size reduces to a smaller
pre-defined value. The proposed method is compared with the existing standard lossless
image compression algorithms and the results show comparative performance. Data
folding technique is a simple approach for compression that provides good compression
efficiency and has lower computational complexity as compared to the standard SPIHT
technique for lossless compression.
Architecture
Figure 2.13: Flowchart of data folding
Firas A. Jassim, et al presents a novel method for image compression which is
called five module methods (FMM) [55]. In this method converting each pixel value in 8x8
blocks into a multiple of 5 for each of RGB array. After that the value could be divided by 5 to](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-61-320.jpg)
![Chapter 2 Background and Literature Review
47
get new values which are a bit length for each pixel and it is less in storage space than the
original values which is 8 bits. This method demonstrates the potential of the FMM based
image compression techniques. The advantage of their method is it provided high PSNR (peak
signal to noise ratio) although it is low CR (compression ratio). This method is appropriate for
bi-level like black and white medical images where the pixel in such images is presented by
one byte (8 bit). As a recommendation, a variable module method (X) MM, where X can be
any number, may be constructed in latter research.
Ashutosh Dwivedi, et al presents a novel hybrid image compression technique [56].
This technique inherits the properties of localizing the global spatial and frequency correlation
from wavelets and classification and function approximation tasks from modified forward-only
counter propagation neural network (MFOCPN) for image compression. Here several tests are
used to investigate the usefulness of the proposed scheme. They explore the use of MFO-CPN
networks to predict wavelet coefficients for image compression. In this method, they combined
the classical wavelet based method with MFO-CPN. The performance of the proposed network
is tested for three discrete wavelet transform functions. In this they analysis that Haar wavelet
results in a higher compression ratio, but the quality of the reconstructed image is not good. On
the other hand db6 with the same number of wavelet coefficients leads to higher compression
ratio with good quality. Overall, they found that the application of db6 wavelet in image
compression out performs other two.
Architecture
Figure 2.14: Block Diagram for Wavelet–CPN Based Image Compression](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-62-320.jpg)
![Chapter 2 Background and Literature Review
48
S. Srikanth, et al presents a technique for image compression which is use
different embedded Wavelet based image coding with Huffman-encoder for further
compression [60]. They implemented the SPIHT and EZW algorithms with Huffman
encoding using different wavelet families and after that compare the PSNRs and bit rates
of these families. These algorithms were tested on different images, and it is seen that the
results obtained by these algorithms have good quality and it provides high compression
ratio as compared to the previous exist lossless image compression techniques.
K. Rajkumar, et al presents an implementation of multi-wavelet transform
coding for lossless image compression [62]. In this paper the performance of the IMWT
(Integer Multi wavelet Transform) for lossless studied .The IMWT provides good result
with the image reconstructed. The performance of the IMWT for lossless compression of
images with magnitude set coding has been obtained. In this proposed technique the
transform coefficient is coded with a magnitude set of coding & run length encoding
technique. The performance of the integer multi-wavelet transform for the lossless
compression of images was analyzed. It was found that the IMWT can be used for the
lossless image compression. The bit rate obtained using the MS-VLI (Magnitude Set-
Variable Length Integer Representation) with RLE scheme is about 2.1 bpp (bits per pixel)
to 3.1 bpp less than that obtain using MS-VLI without RLE scheme.
2.3 Summary
In this chapter, we introduced the objective of image compression that decrease the
redundancy data in image without changes the information of an image. This operation
occurs by some techniques classified into the techniques of compression using wavelet
transforms. Many Researchers hybrids the wavelet transforms with lossy or lossless to
enhance image compression.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-63-320.jpg)

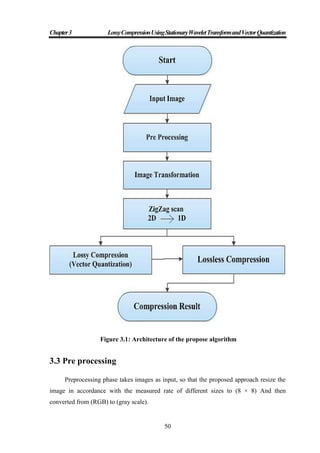
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
51
Resize image reduces in both horizontal and vertical direction using equation 3.1
fd (m, n) = f (2m,2n) ……………………..(1)
Where f (x, y) represents the original continuous image, fd (m, n) the sampled image.[71]
While gray scale ways to convert a full-color image to grayscale, equation 3.2, gray
scale algorithms utilizes the same basic three-step process:
1. Get the red, green, and blue values of a pixel
2. Use a fancy math to turn those numbers into a single gray value
3. Replace the original red, green, and blue values with the new gray value.
When describing grayscale algorithms, I‟m going to focus on step 2 – using math to
turn color values into a grayscale value. So, when you see a formula like this:
Gray = (Red + Green + Blue) / 3…………….(2)
Recognize that the actual code to implement such an algorithm looks like [71]:
6. Preprocessing Algorithm
RGB to Gray (image_matrix)
For Each Pixel in Image_matrix {
Red = Pixel. Red Green = Pixel. Green Blue = Pixel.Blue
Gray = (Red + Green + Blue) / 3
Pixel. Red = Gray
Pixel. Green = Gray
Pixel.Blue = Gray
}
Return image gray_matrix](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-66-320.jpg)
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
52
Figure 3.2: Diagram conversion and downsizing
3.4 Image Transformation
Image transformation phase received the resizable gray scale images and produced
transformed images. This phase used the three types of wavelet transforms such as DWT,
LWT, and SWT.
3.4.1 Discrete Wavelet Transform
The Discrete Wavelet Transform (DWT) of image signals produces a nonredundant
image representation, which provides better spatial and spectral localization of image
formation, compared with other multi scale representations such as Gaussian and Laplacian
pyramid. Recently, Discrete Wavelet Transform has attracted more and more interest in
image fusion [17]. An image can be decomposed into a sequence of different spatial
resolution images using DWT. In case of a 2D image, an N level decomposition can be
performed, resulting in 3N+1 different frequency bands and it is shown in Figure. 3.3
Resizes to image
8x8
Image
2-D matrix (8x8)
Convert gray scale](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-67-320.jpg)
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
53
Figure 3.3: 2D - Discrete wavelet transforms
3.4.2 Lifting Wavelet Transform
Lifting scheme algorithms have the advantage that they do not require temporary
arrays in the calculation steps, as is necessary for some versions of the Daubechies D4
Wavelet algorithm. The Predict step calculates the wavelet function in the wavelet
transform .This is a high Pass filter. The update step calculates the scaling function, which
results in a smoother version of the data [19].
This operation consists of three steps.
1) First, the input signal x[n] is down sampled into the even position signal xe (n)
and the odd position signal xo(n) , then modifying these values using
alternating prediction and updating steps.
xe (n) = x [2n] and xo(n) = x [2n+1]
2) A prediction step consists of predicting each odd sample as a linear
combination of the even samples and subtracting it from the odd sample to
form the prediction error.
3) An update step consists of updating the even samples by adding them to a
linear combination of the prediction error to form the updated sequence. The
prediction and update may be evaluated in several steps until the forward
transform is completed.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-68-320.jpg)
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
54
Figure 3.4: Diagram lifting wavelet scheme transform
3.4.3 Stationary Wavelet Transform
The Stationary wavelet transform (SWT) is a wavelet transform algorithm designed
to overcome the lack of translation-invariance of the discrete wavelet transforms (DWT).
Translation-invariance is achieved by removing the downsamplers and upsamplers in the
DWT and upsampling the filter coefficients by a factor of in the th level of the
algorithm. The SWT is an inherently redundant scheme as the output of each level of SWT
contains the same number of samples as the input – so for a decomposition of N levels
there is a redundancy of N in the wavelet coefficients[72].
The following block diagram depicts the digital implementation of SWT.
Figure 3.5 : 3 level Stationary wavelet transform filter bank
In the above diagram, filters in each level are up-sampled versions of the previous.
Figure 3.6: Stationary wavelet transforms filters](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-69-320.jpg)
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
55
LLj+1(χ, γ) = L[n] L [m] LLj (2j+1 m- χ, 2j+1 n- γ)
LHj+1(χ, γ) = L[n] H [m] LLj (2j+1 m- χ, 2j+1 n- γ)
( 3 )
HLj+1(χ, γ) = H[n] L [m] LLj (2j+1 m- χ, 2j+1 n- γ)
HHj+1(χ, γ) = H[n] H [m] LLj (2j+1 m- χ, 2j+1 n- γ)
[MATLAB R2013a]](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-70-320.jpg)
![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
56
3.5 Zigzag Scan
Zigzag scans phase takes as an input the transformed images in 2D matrix and
produced images in 1D matrix, so that the frequency (horizontal + vertical) increases in
this order, and the coefficient variance decreases in this order [71].
Figure 3.7: Zigzag scan
3.6 Lossy Compression Vector quantization by Linde-Buzo-
Gray
Lossy compression technique provides a higher compression ratio than lossless
compression.
A lossy compression scheme, shown in Figure 3.8, may examine the color data for a
range of pixels, and identify subtle variations in pixel color values that are so minute that
the human eye/brain is unable to distinguish the difference between them.
Figure 3.8: Block diagram for lossy compression](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-71-320.jpg)



![Chapter3 LossyCompressionUsingStationaryWaveletTransformandVectorQuantization
60
3.7.2 Huffman Coding
Uses Top-down approach The Huffman algorithm is simple and can be described in
terms of creating a Huffman code tree. The procedure for building this tree is:
1- Start with a list of free nodes, where each node corresponds to a symbol in the alphabet.
2- Select two free nodes with the lowest weight from the list.
3- Create a parent node for these two nodes selected and the weight is equal to the
weight of the sum of two child nodes.
4- Remove the two child nodes from the list and the parent node is added to the list of free
nodes.
5- Repeat the process starting from step-2 until only a single tree remains.
3.8 Compression Ratio
Compression Ratio: is the ratio of the size of the compressed database system with
the original size of the uncompressed database systems. Also known as compression,
power is a computer-science term used to quantify the reduction in data-representation size
produced by a data compression algorithm. Compression ratio is defined as follows: [1]
CR=
size of original image data
size of compressed image data
…………………(5)
3.9 Summary
In this chapter, we introduced our proposed approach called lossy image
compression using stationary wavelet transform and vector quantization, which consist of
four phases; namely: preprocessing, image transformation, zigzag scan, and lossy/lossless
compression. In preprocessing phase, we take an image as inputs and produced gray scale
resizable images. In image transformation phase, we take the result of preprocessing phase
and applied transformation techniques such as SWT to transformed our images, so in
zigzag scan phase, we mapping our images from two dimension matrix into one dimension
matrix. Finally, in the Lossy/Lossless phase, we applied vector quantization and other
techniques to compress our images in a sufficient way.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-75-320.jpg)



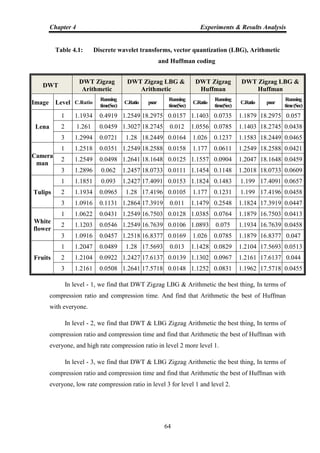


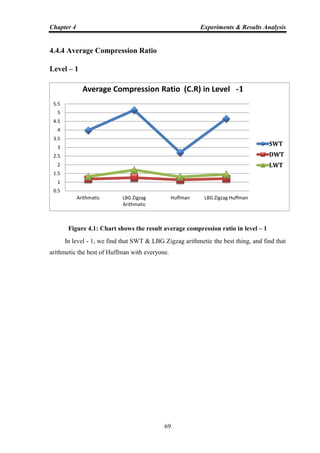
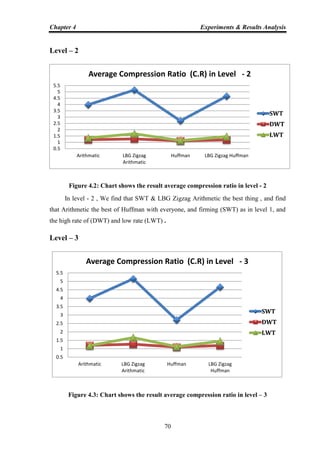










![Appendix (I) Programs Appendices
1
APPENDIX (I)
Implementation of Lossy Compression Using Stationary
Wavelet Transform and Vector Quantization
1- Stationary Wavelet Transform (SWT)
1.1. Swt_Zigzag_Arithmetic
function [out] = swt_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
Setdemorandstream(96868483);
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
tic;
dbstop if error
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
% Image coding.
Nbcol = size(map,1);
cod_X = wcodemat(I,nbcol);
%=========================SWT============================](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-96-320.jpg)
![Appendix (I) Programs Appendices
2
[ca,chd,cvd,cdd] = swt2(X,Level,'db1');
cod_ca = wcodemat(ca(:,:,1),nbcol);
cod_chd = wcodemat(chd(:,:,1),nbcol);
cod_cvd = wcodemat(cvd(:,:,1),nbcol);
cod_cdd = wcodemat(cdd(:,:,1),nbcol);
decl = [cod_ca,cod_chd;cod_cvd,cod_cdd];
imwrite(cod_ca,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;imshow(Xswt)
%=========================Zigzag============================
p=zigzag (Xswt);
%=======================Arithmatic===========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v*2]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;
1.2. Swt_LBGVQ_Zigzag_Arithmetic
function [out] = SWT_LBGVQ_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-97-320.jpg)
![Appendix (I) Programs Appendices
3
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
% Image coding.
nbcol = size(map,1);
cod_X = wcodemat(I,nbcol);
% subplot(333)
% image(cod_X)
% title('Original image');
% colormap(map)
%=========================SWT============================
[ca,chd,cvd,cdd] = swt2(X,Level,'db1');
cod_ca = wcodemat(ca(:,:,1),nbcol);
cod_chd = wcodemat(chd(:,:,1),nbcol);
cod_cvd = wcodemat(cvd(:,:,1),nbcol);
cod_cdd = wcodemat(cdd(:,:,1),nbcol);
decl = [cod_ca,cod_chd;cod_cvd,cod_cdd];](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-98-320.jpg)
![Appendix (I) Programs Appendices
4
imwrite(cod_ca,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%=========================Vector Quantization==================
original=x;
[v]=trainlvq(x,0);
compressed=v;
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag (Xswt);
%=======================Arithmatic===========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;
1.3. Swt_Zigzag_Huffman
function [out] = swt2_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-99-320.jpg)
![Appendix (I) Programs Appendices
5
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
disp('Running ..');
% set(0, 'RecursionLimit', 100000)
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
tic;
dbstop if error
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
% Image coding.
nbcol = size(map,1);
cod_X = wcodemat(I,nbcol);
%============================SWT===========================
[ca,chd,cvd,cdd] = swt2(X,Level,'db1');
cod_ca = wcodemat(ca(:,:,1),nbcol);
cod_chd = wcodemat(chd(:,:,1),nbcol);
cod_cvd = wcodemat(cvd(:,:,1),nbcol);
cod_cdd = wcodemat(cdd(:,:,1),nbcol);
decl = [cod_ca,cod_chd;cod_cvd,cod_cdd];
imwrite(cod_ca,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;imshow(Xswt)](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-100-320.jpg)
![Appendix (I) Programs Appendices
6
%=========================Zigzag============================
p=zigzag(Xswt);
%==========================Huffman==========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[v nn]=size(pp);
count = [1:1:v*6]; % Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p); % build the Huffman dictionary
code= huffmanenco(ppnew,dict); %encode your original image with the dictionary you
just built
CompressionRatio = CR(decl,code)
toc;
1.4. Swt_LBGVQ_Zigzag_Huffman
function [out] = SWT_LBGVQ_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
% set(0, 'RecursionLimit', 100000)
SX=str2num(get(SX,'String'));](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-101-320.jpg)
![Appendix (I) Programs Appendices
7
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
% Image coding.
nbcol = size(map,1);
cod_X = wcodemat(I,nbcol);
%============================SWT===========================
[ca,chd,cvd,cdd] = swt2(X,Level,'db1');
cod_ca = wcodemat(ca(:,:,1),nbcol);
cod_chd = wcodemat(chd(:,:,1),nbcol);
cod_cvd = wcodemat(cvd(:,:,1),nbcol);
cod_cdd = wcod
emat(cdd(:,:,1),nbcol);
decl = [cod_ca,cod_chd;cod_cvd,cod_cdd];
imwrite(cod_ca,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%======================Vector Quantization====================
original=x;
[v]=trainlvq(x,0);
compressed=v;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-102-320.jpg)
![Appendix (I) Programs Appendices
8
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag(Xswt);
%==========================Huffman==========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[v nn]=size(pp);
count = [1:1:v]; % Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p); % build the Huffman dictionary
code= huffmanenco(ppnew,dict); %encode your original image with the dictionary you
just built
CompressionRatio = CR(decl,code)
toc;
2 - Discrete wavelet transform (DWT)
2.1. Dwt_Zigzag_Arithmetic
function [out] = DWT_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-103-320.jpg)
![Appendix (I) Programs Appendices
9
setdemorandstream(96868483);
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================DWT======================
decl = DWT(I,Level);
imwrite(decl,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;
% imshow(Xswt)
%=========================Zigzag====================
p=zigzag(Xswt);
%=======================Arithmatic====================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-104-320.jpg)
![Appendix (I) Programs Appendices
10
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v+10]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;
2.2. Dwt_LBGVQ_Zigzag_Arithmetic
function [out] =DWT_LBGVQ_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
com.mathworks.mlservices.MLCommandHistoryServices.removeAll
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-105-320.jpg)
![Appendix (I) Programs Appendices
11
%=========================DWT=============================
decl = DWT(I,Level);
imwrite(decl,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%======================Vector Quantization=====================
original=x;
[v]=trainlvq(x,0);
compressed=v;
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag(Xswt);
%=======================Arithmatic===========================pp=p'
;
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;
2.3. Dwt_Zigzag_Huffman
function [out] = DWT_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-106-320.jpg)
![Appendix (I) Programs Appendices
12
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
set(0, 'RecursionLimit', 100000)
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================DWT=============================
decl = DWT(I,Level);
imwrite(decl,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;
% imshow(Xswt)
%=========================Zigzag============================
p=zigzag(Xswt);
%==========================Huffman==========================
pp=p';
BB = sort(pp);](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-107-320.jpg)
![Appendix (I) Programs Appendices
13
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
[v nn]=size(ppnew);
count = [1:1:N]; % Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p); % build the Huffman dictionary
code= huffmanenco(ppnew,dict); %encode your original image with the dictionary you
just built
CompressionRatio = CR(decl,code)
toc;
2.4. DWT_LBGVQ_Zigzag_Hufman
function [out] = DWT_LBGVQ_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
% set(0, 'RecursionLimit', 100000)
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-108-320.jpg)
![Appendix (I) Programs Appendices
14
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================DWT============================
decl = DWT(I,Level);
imwrite(decl,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%======================Vector Quantization====================
original=x;
[v]=trainlvq(x,0);
compressed=v;
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag(Xswt);
%=========================Huffman===========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-109-320.jpg)
![Appendix (I) Programs Appendices
15
[v nn]=size(ppnew);
count = [1:1:v];
% Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p);
% build the Huffman dictionary
code= huffmanenco(ppnew,dict);
%encode your original image with the dictionary you just built
CompressionRatio = CR(decl,code)
toc;
3 Lifting Wavelet Transform (LWT)
3.1. Lwt_Zigzag_Arithmetic
function [out] = LWT_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-110-320.jpg)
![Appendix (I) Programs Appendices
16
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================LWT============================
lshaar = liftwave('db1');
% Add a primal ELS to the lifting scheme.
els = {'p',[-0.125 0.125],0};
lsnew = addlift(lshaar,els);
% Perform LWT at level 1 of a simple image.
[decl,cH,cV,cD] = lwt2(I,lsnew,Level)% coefficients matrix decl
imwrite(decl,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;
% imshow(Xswt)
%=========================Zigzag=============================
p=zigzag (Xswt);
%=======================Arithmatic==========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v*2]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-111-320.jpg)
![Appendix (I) Programs Appendices
17
1.7 Lwt_LBGVQ_Zigzag_Arithmetic
function [out] = LWT_LBGVQ_Zigzag_Arithmetic(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================LWT=============================
lshaar = liftwave('db1');
els = {'p',[-0.125 0.125],0};
lsnew = addlift(lshaar,els);
[decl,cH,cV,cD] = lwt2(I,lsnew,Level)% coefficients matrix decl
imwrite(decl,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%=====================Vector Quantization======================](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-112-320.jpg)
![Appendix (I) Programs Appendices
18
original=x;
[v]=trainlvq(x,0);
compressed=v;
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag (Xswt);
%=======================Arithmatic===========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[M N]=size(ppnew');
v=max(ppnew);
counts = [1:1:v]; % Distinct data symbols appearing in sig
code = arithenco(ppnew',counts);
CompressionRatio = CR(decl,code)
toc;
% dseq = arithdeco(code,counts,length(ppnew'));
% isequal(ppnew',dseq)
%
% [M N]=size(dseq');
% ppOR=zeros(1,N);
% for k=1:M
% ppOR(1,k) =BB(dseq(1,k),1);
% end
% isequal(pp',ppOR)](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-113-320.jpg)
![Appendix (I) Programs Appendices
19
1.8 LWT_Zigzag_Hufman
function [out] = LWT_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
set(0, 'RecursionLimit', 100000)
disp('Running ..');
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================LWT=============================
lshaar = liftwave('db1');
% Add a primal ELS to the lifting scheme.
els = {'p',[-0.125 0.125],0};
lsnew = addlift(lshaar,els);
% Perform LWT at level 1 of a simple image.
[decl,cH,cV,cD] = lwt2(I,lsnew,Level)% coefficients matrix decl](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-114-320.jpg)
![Appendix (I) Programs Appendices
20
imwrite(decl,map,'myclown.png')
Xswt = imread('myclown.png');
% figure;
% imshow(Xswt)
%=========================Zigzag============================
p=zigzag(Xswt);
%==========================Huffman==========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[v nn]=size(ppnew);
count = [1:1:v+10]; % Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p); % build the Huffman dictionary
code= huffmanenco(ppnew,dict); %encode your original image with the dictionary you
just built
CompressionRatio = CR(decl,code)
toc;
1.9 LWT_LBGVQ_Zigzag_Hufman
function [out] = LWT_LBGVQ_Zigzag_Hufman(Level,SX,SY)
% clc; % Clear the command window.
% close all; % Close all figures (except those of imtool.)
% imtool close all; % Close all imtool figures if you have the Image Processing Toolbox.
% clear; % Erase all existing variables. Or clearvars if you want.](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-115-320.jpg)
![Appendix (I) Programs Appendices
21
% workspace; % Make sure the workspace panel is showing.
setdemorandstream(96868483);
% set(0, 'RecursionLimit', 100000)
SX=str2num(get(SX,'String'));
SY=str2num(get(SY,'String'));
Level=str2num(get(Level,'String'));
[filename, pathname]=uigetfile({'*.jpg';'*.bmp';'*.png'},'Select an image');
load parameter;
global para;
tic;
ab=strcat(pathname,filename);
gmap = [0:255;0:255;0:255]'/255;
X = imread(ab);
X = imresize(X, [SX SY]);
[ORX,ORY]=size(X);
[X,map] = rgb2ind(X,gmap);
I=double(X);
[xx,yy]=size(I);
%=========================LWT======================
lshaar = liftwave('db1');
% Add a primal ELS to the lifting scheme.
els = {'p',[-0.125 0.125],0};
lsnew = addlift(lshaar,els);
% Perform LWT at level 1 of a simple image.
[decl,cH,cV,cD] = lwt2(I,lsnew,Level)% coefficients matrix decl
imwrite(decl,map,'myclown.png')
x = imread('myclown.png');
% figure;imshow(Xswt)
%======================Vector Quantization====================
original=x;
[v]=trainlvq(x,0);
compressed=v;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-116-320.jpg)
![Appendix (I) Programs Appendices
22
[y]=testlvq1(x);
[psnrvalue]=psnr2(original,y,255)
%=========================Zigzag============================
p=zigzag(Xswt);
%==========================Huffman==========================
pp=p';
BB = sort(pp);
BB= unique(BB);
[M N]=size(pp);
ppnew=zeros(M,1);
for k=1:M
ppnew(k,1) =find(BB==pp(k,1));
end
[v nn]=size(ppnew);
count = [1:1:v+8]; % Distinct data symbols appearing in sig
total=sum(count);
for i=1:1:size((count)');
p(i)=count(i)/total;
end
[dict,avglen]=huffmandict(count,p); % build the Huffman dictionary
code= huffmanenco(ppnew,dict); %encode your original image with the dictionary you
just built
CompressionRatio = CR(decl,code)
toc;](https://image.slidesharecdn.com/omarghazithesis4-9-2016-170127204237/85/Lossy-Compression-Using-Stationary-Wavelet-Transform-and-Vector-Quantization-117-320.jpg)

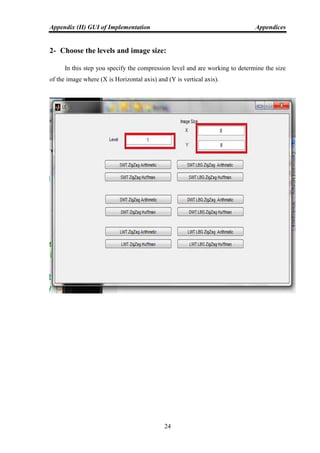








This document is a thesis submitted by Omar Ghazi Abbood Khukre to the Department of Information Technology at Alexandria University in partial fulfillment of the requirements for a Master's degree in Information Technology. The thesis proposes a lossy image compression approach using Stationary Wavelet Transform and Vector Quantization. It includes acknowledgments, an abstract, table of contents, list of figures/tables, and chapters on introduction, background/literature review, the proposed lossy compression method, experiments and results analysis, and conclusion.



































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












