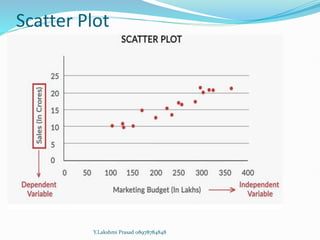
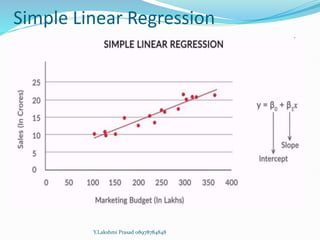
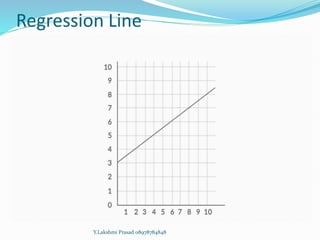
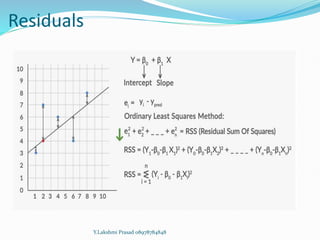
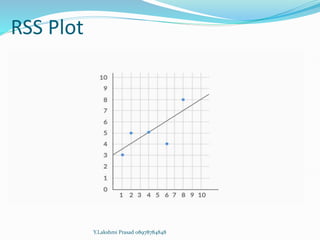
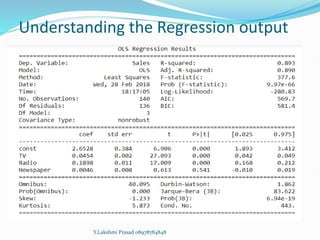
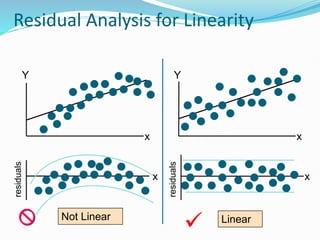
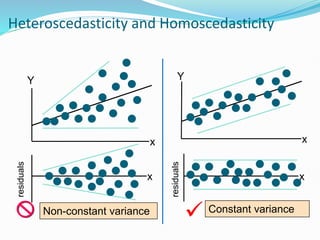
The document provides an overview of linear regression, covering concepts such as simple and multiple linear regression, the least squares method, and metrics for model evaluation like R-squared and residual sum of squares. It also discusses the assumptions underlying linear regression, issues related to multicollinearity, and techniques for variable selection such as Recursive Feature Elimination (RFE). Overall, the text serves as a comprehensive guide to understanding and implementing linear regression models.






























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















