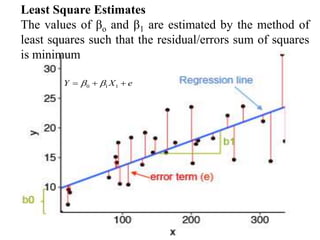
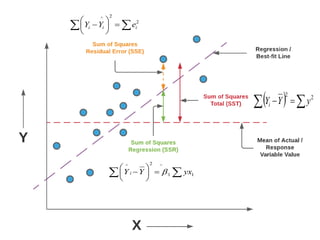
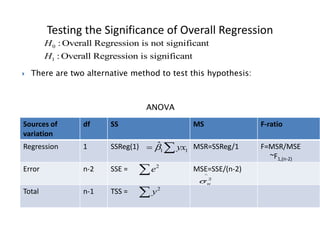
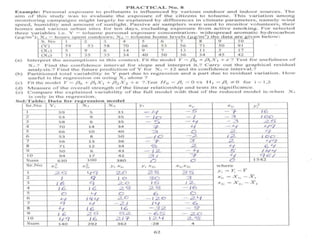
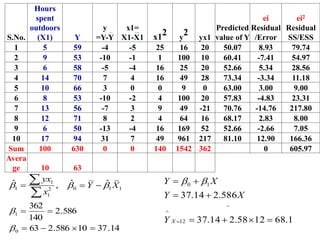
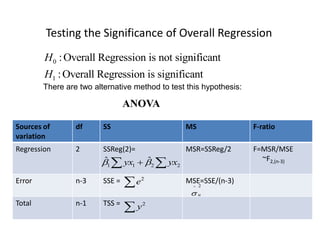
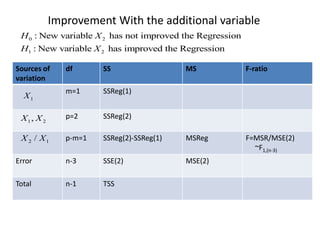
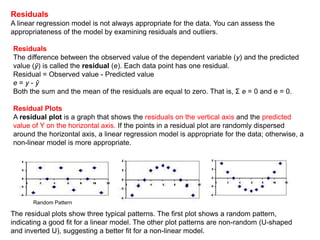
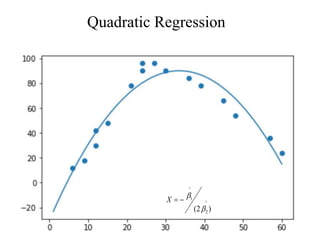
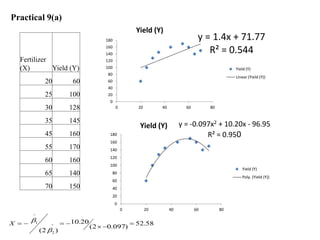
This document discusses regression analysis techniques. Regression analysis is used to model the relationship between a dependent variable (Y) and one or more independent variables (X1, X2, etc). Simple linear regression involves one independent variable, while multiple linear regression involves two or more independent variables. The key assumptions of linear regression are outlined. Methods for estimating regression coefficients using least squares and testing the significance of regression coefficients and the overall regression model are also described. An example application involving modeling personal pollutant exposure (Y) based on hours outdoors (X1) and home pollutant levels (X2) is provided.