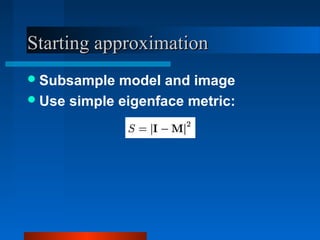
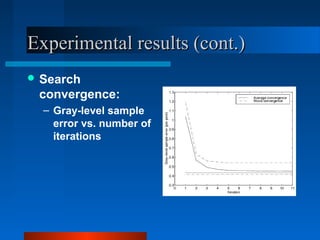
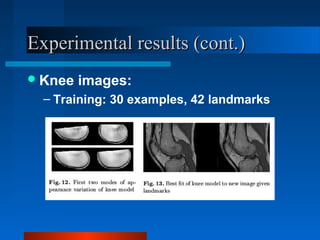
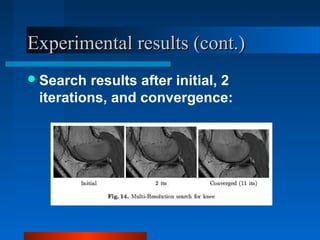
Active Appearance Models (AAMs) combine shape and texture models into a single statistical model. AAMs are trained on labeled images to learn the relationship between shape, texture, and model parameters. To interpret a new image, an optimization problem is solved to minimize the difference between the image and one synthesized by the AAM. The model parameters are updated iteratively based on a linear model trained to relate parameter adjustments to image differences. Constrained AAMs incorporate prior information to improve the influence of the starting approximation on the search results.