Downloaded 141 times

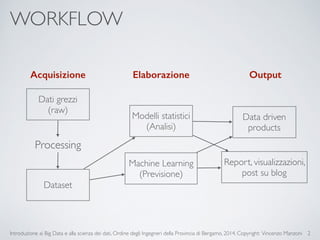
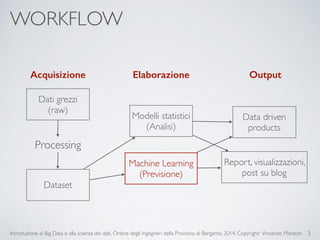

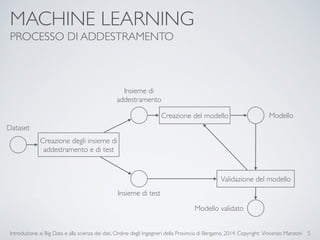


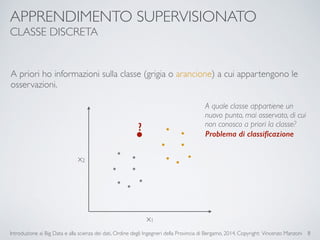
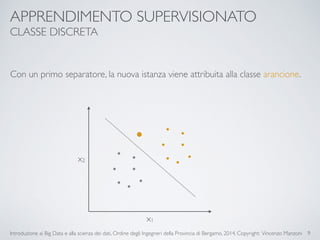
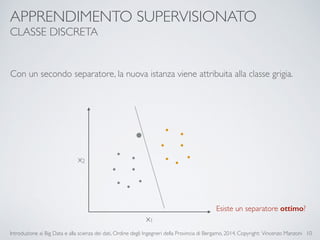
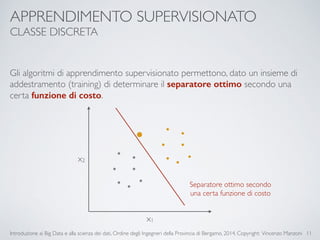
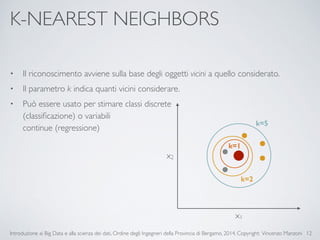
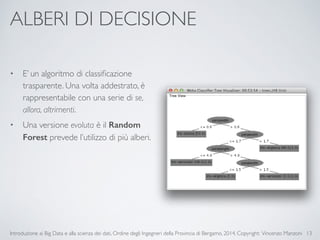

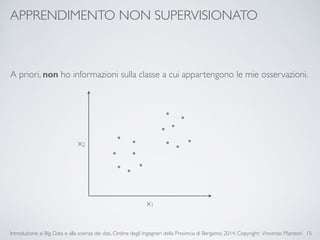
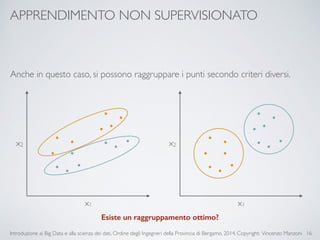
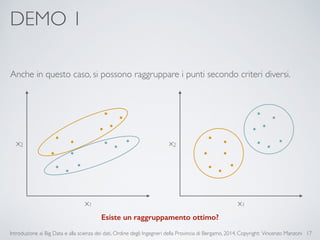

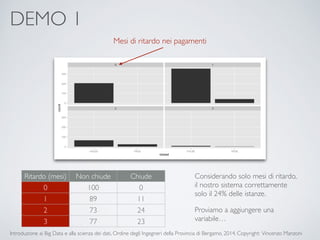



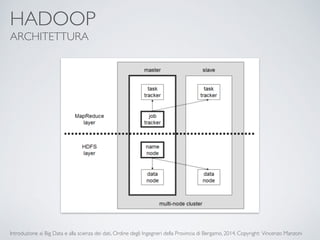






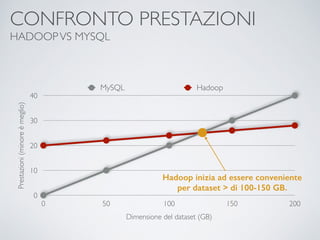



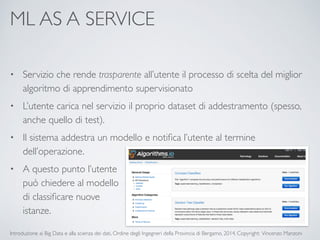



Il documento fornisce un'introduzione ai big data e alla scienza dei dati, coprendo argomenti come il machine learning, le sue tipologie (apprendimento supervisionato e non supervisionato) e la tecnologia Hadoop, fra cui strumenti come Hive e Pig per l'analisi dei dati. Viene anche trattato il cloud computing e servizi come ML as a Service per facilitare l'addestramento di modelli predittivi. Infine, vengono presentati esempi di applicazione e delle performance di diverse tecnologie per la gestione dei big data.


































![[SLIDE] Tecniche basate su machine learning per la determinazione del profilo...](https://cdn.slidesharecdn.com/ss_thumbnails/laderchi-151109180727-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
































