Downloaded 21 times














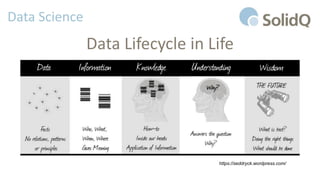
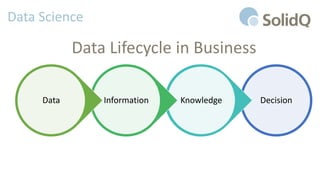





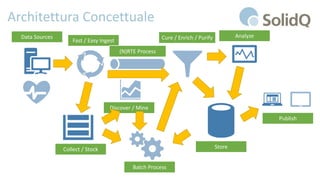
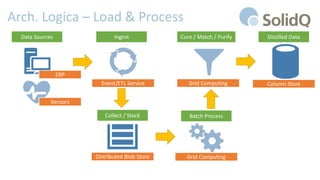
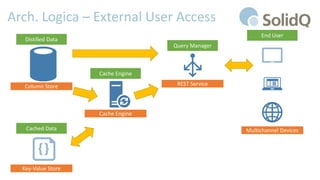
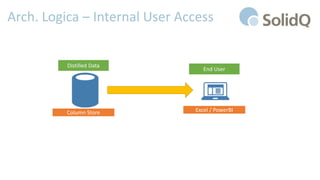
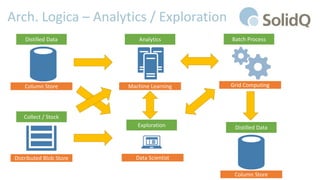








Il documento tratta l'analisi dei big data e dell'internet delle cose, presentando eventi di registrazione e sessioni sulla business intelligence, l'uso dei big data nello sport e architetture di riferimento per la loro gestione. Viene discussa la crescente importanza dei big data e le sfide associate, evidenziando come le architetture possono evolversi nel tempo e come il cloud possa rendere queste tecnologie più accessibili e sostenibili. Inoltre, la piattaforma Azure viene proposta come soluzione ideale per affrontare le esigenze di gestione dei dati e migliorare l'efficienza operativa.
























































