Downloaded 125 times





















































![Corso Big Data
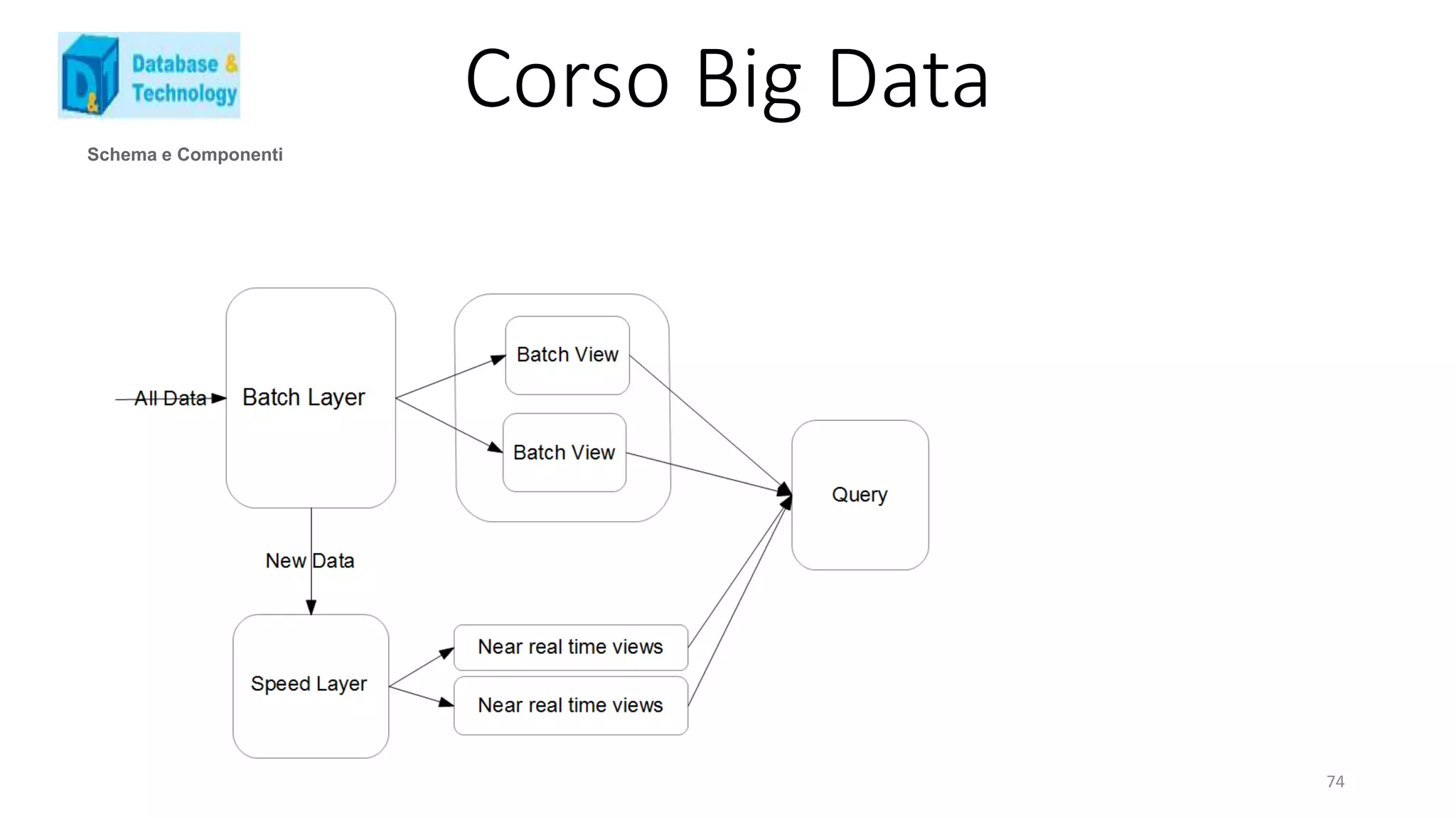
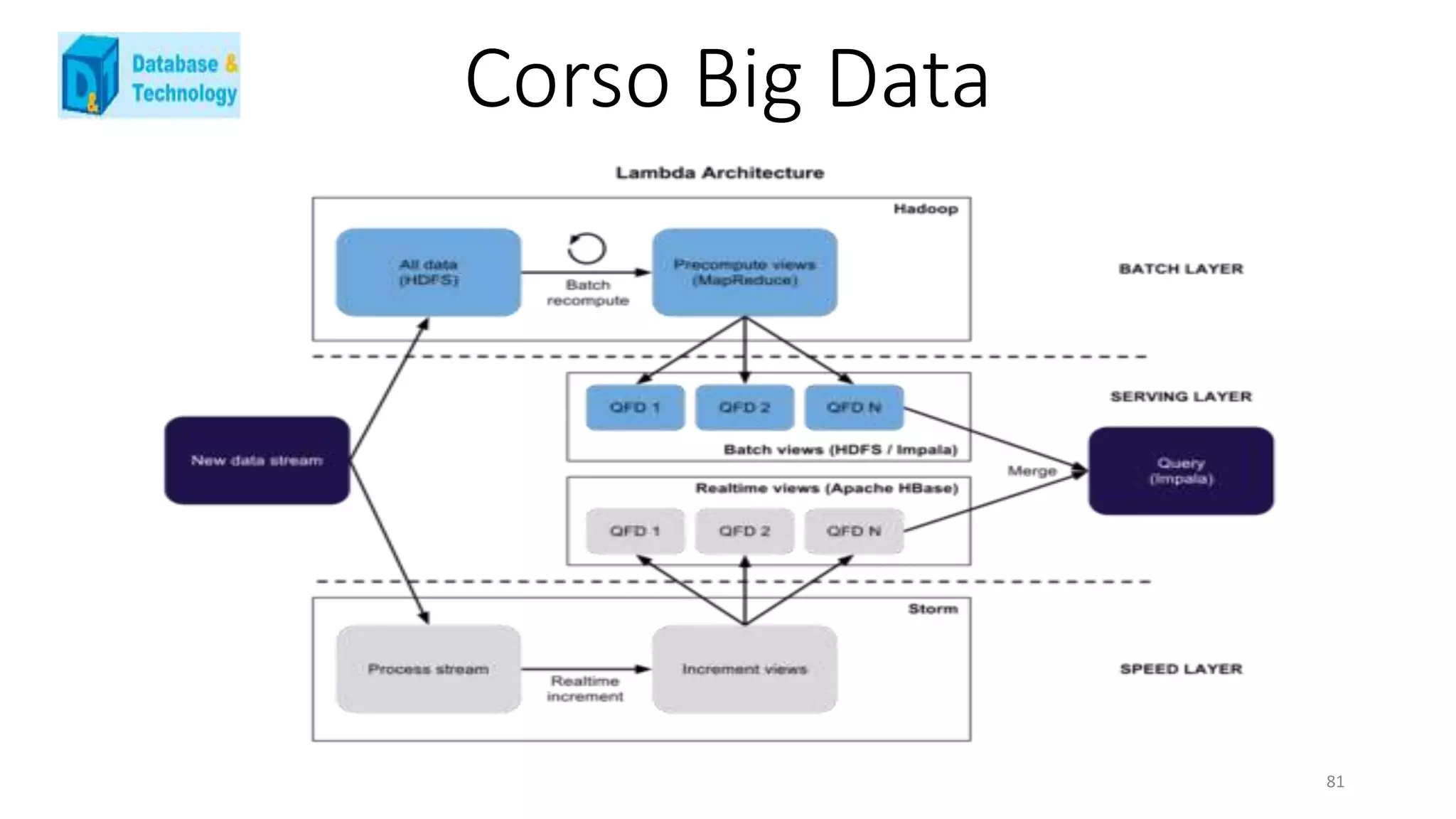
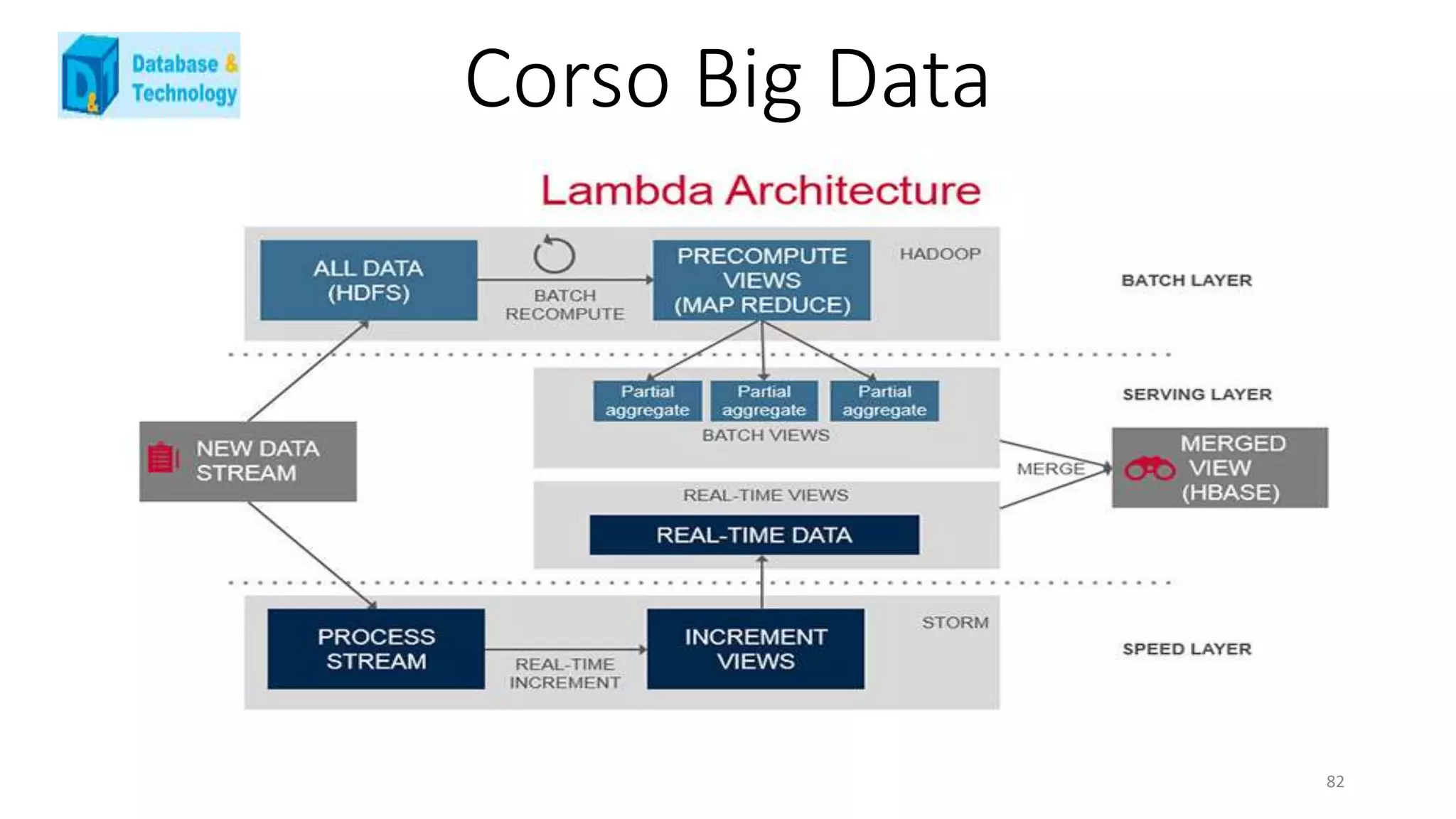
Lambda Architecture : una soluzione [ functional ]
La Lambda Architecture è una prima proposta di alto livello che cerca di dare una risposta al problema dei Big Data,
che oggi è tanto di moda.
La proposta di Nathan Marz, è nata quando si occupava dei sistemi in Twitter.
Il big del 140 caratteri aveva una stack applicativo interamente progettato in Ruby, che però non riusciva a reggere
l’enorme mole di utenti e messaggi che ogni mese incrementavano.
Nonostante gli sforzi di ottimizazzione, che si sono spinti fino alla riscrittura di parti dell’interprete, la conclusione è
stata la necessità di abbandonare Ruby.
La nuova proposta era basata sulla Java Virtual Machine, ma anche in questo caso non c’era a disposizione una
architettura che garantisse la scalabilità con le performance richieste da Twitter.
70](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-70-2048.jpg)



































![Corso Big Data
126
MONGODB
MongoDB è un database sviluppato da MongoDB Inc., divenuto il principale database NoSQL utilizzato grazie alla sua
estrema facilità di installazione e manutenzione. Questa semplicità non preclude però di ottenere ottime prestazioni da
questo database, che grazie ad una campagna di vendita aggressiva e un supporto continuo, oltre alla fornitura di API in
molti linguaggi di programmazione, continua la sua scalata verso le prime posizioni tra i database piu` usati, anche piu` di
alcuni database relazionali.
Tipologia
MongoDB `e un database document-oriented, in cui quindi l’unità fondamentale sono i documenti[41], equivalenti alle
singole tabelle di un database relazionale ma molto piu` espressivi. Questi sono identificati tutti da una chiave speciale ed
univoca, id, che li identifica. A questi si aggiunge il concetto di collection, insieme di documenti, paragonabili a schemi. La
possibilit`a di innestare documenti o di avere delle referenze tra essi rende molto potente, flessibile e dinamico questo
modello. Per quanto riguarda il CAP theorem, MongoDB utilizza le proprietà di partitioning e consistency. I dati non sono
infatti disponibili nel momento in cui il nodo principale, detto primario e spiegato nel paragrafo successivo, non sia piu`
disponibile, dovendo aspettare un suo recupero prima di poter accedere ai dati in esso contenuti.](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-126-2048.jpg)

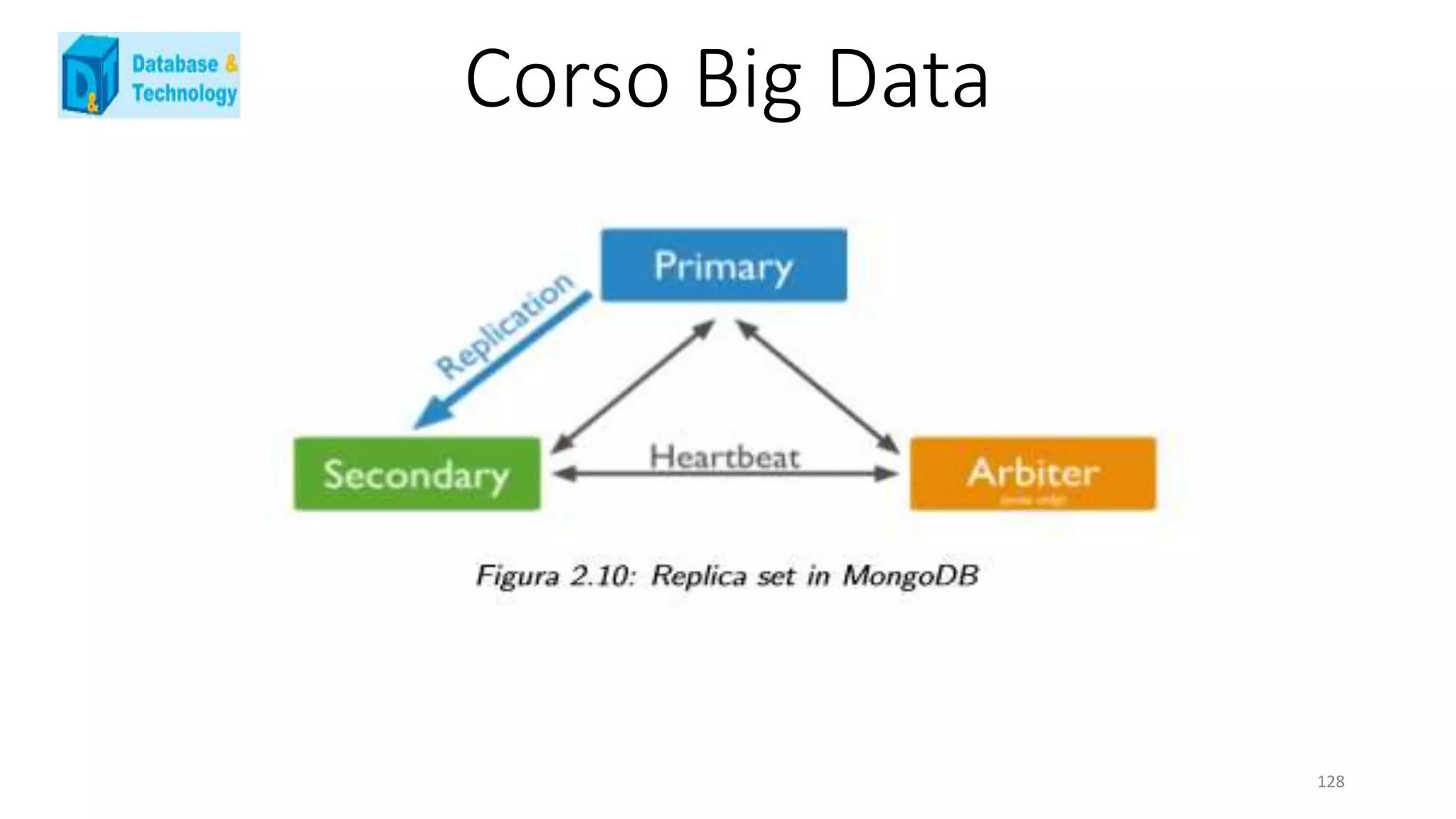


![Corso Big Data
131
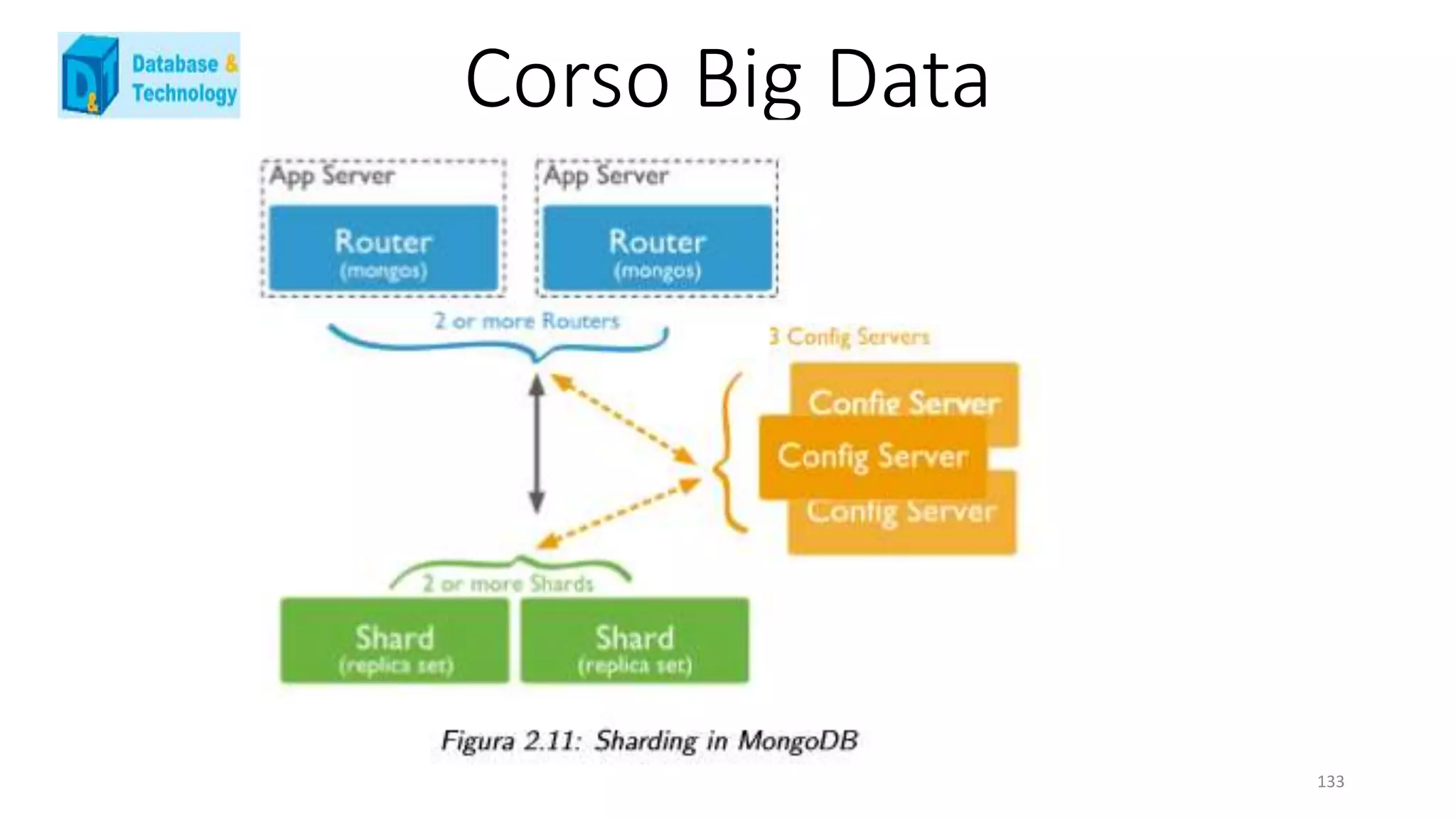
• config server[37]: Nel momento in cui si decide di avere una rete multi shard, bisogna inserire due nuovi processi
all’interno dell’architettura di MongoDB. Il primo tra questi è il config server, processo chiave dell’intero cluster. Questo
contiene tutti i metadata riguardo a quale nodo contiene quale dato, diventando così un nodo estremamente importante
per la vita del database. Esso è una particolare istanza del processo mongod ed è possibile, nell’intero cluster, istanziarne
solamente uno o tre, per permettere un risultato sicuro ed immediato nel momento in cui debba svolgersi un majority
voting, necessario nel caso di inconsistenza dati.
• mongos: è il secondo processo necessario qualora si decida di creare piu` shard. Questo dispone di un elenco
contenente tutti i nodi che compongono il database e il relativo replica set di appartenenza, dati recuperati e
continuamente aggiornati attraverso la continua comunicazione con i config server. E’ inoltre l’unico processo ad essere
abilitato a comunicare con i client, reindirizzando la loro richiesta ai nodi delle varie shard e restituendo i risultati al
richiedente del servizio. Non ci sono limiti sul numero di istanze possibili di questo processo, definendo quindi il numero
di entry point per MongoDB uguale al numero di processi mongos istanziati.](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-131-2048.jpg)


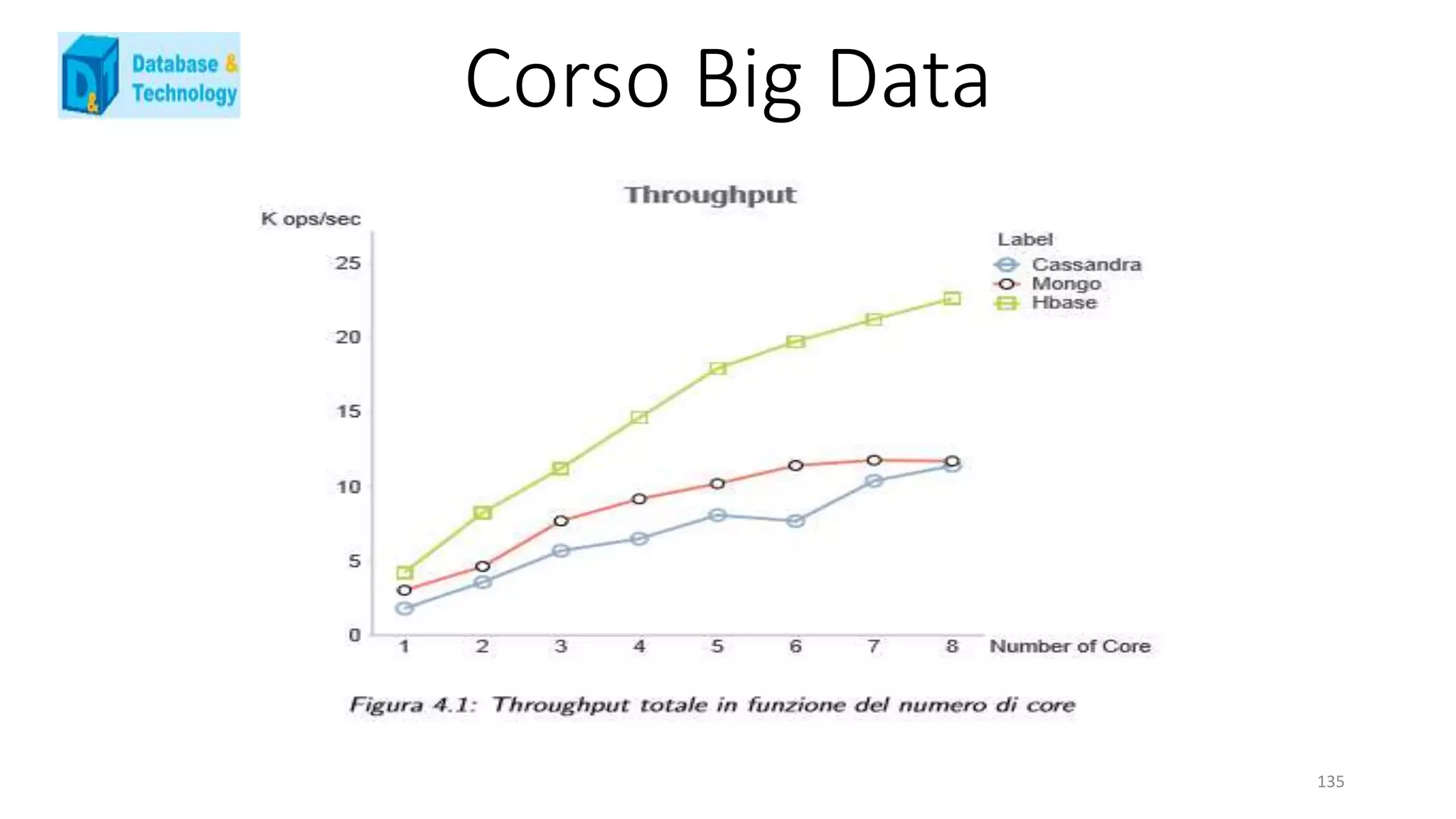
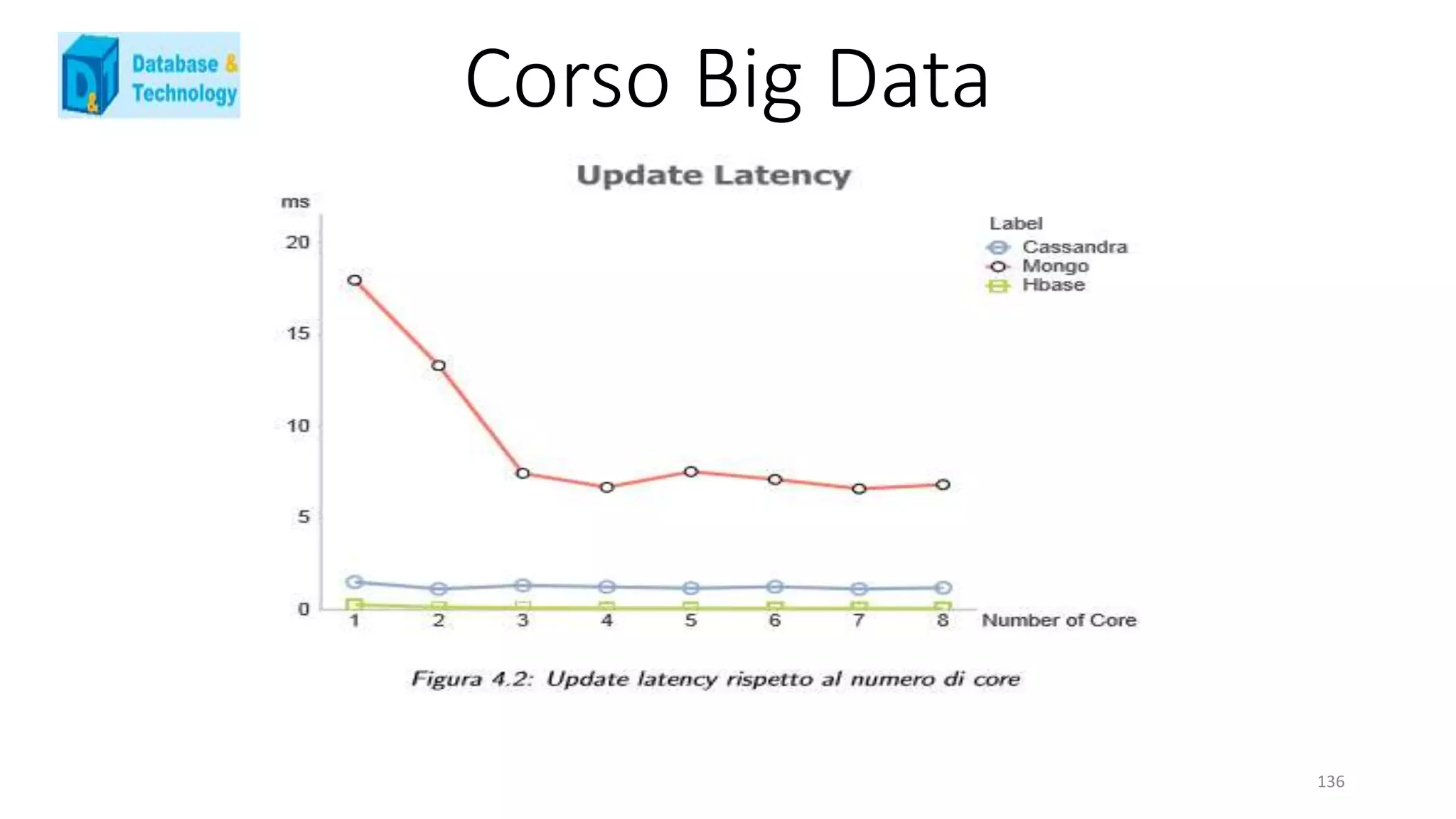
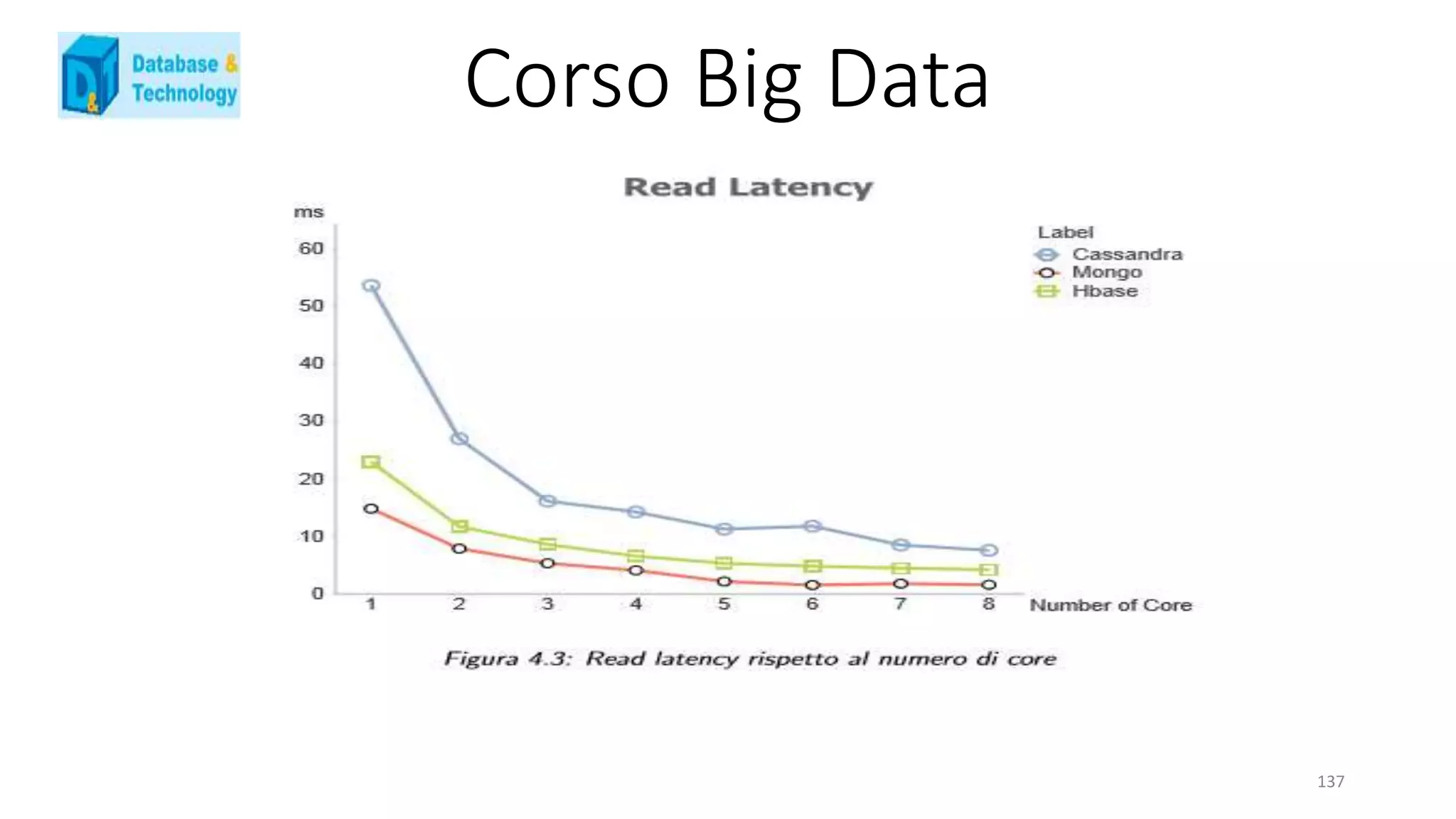
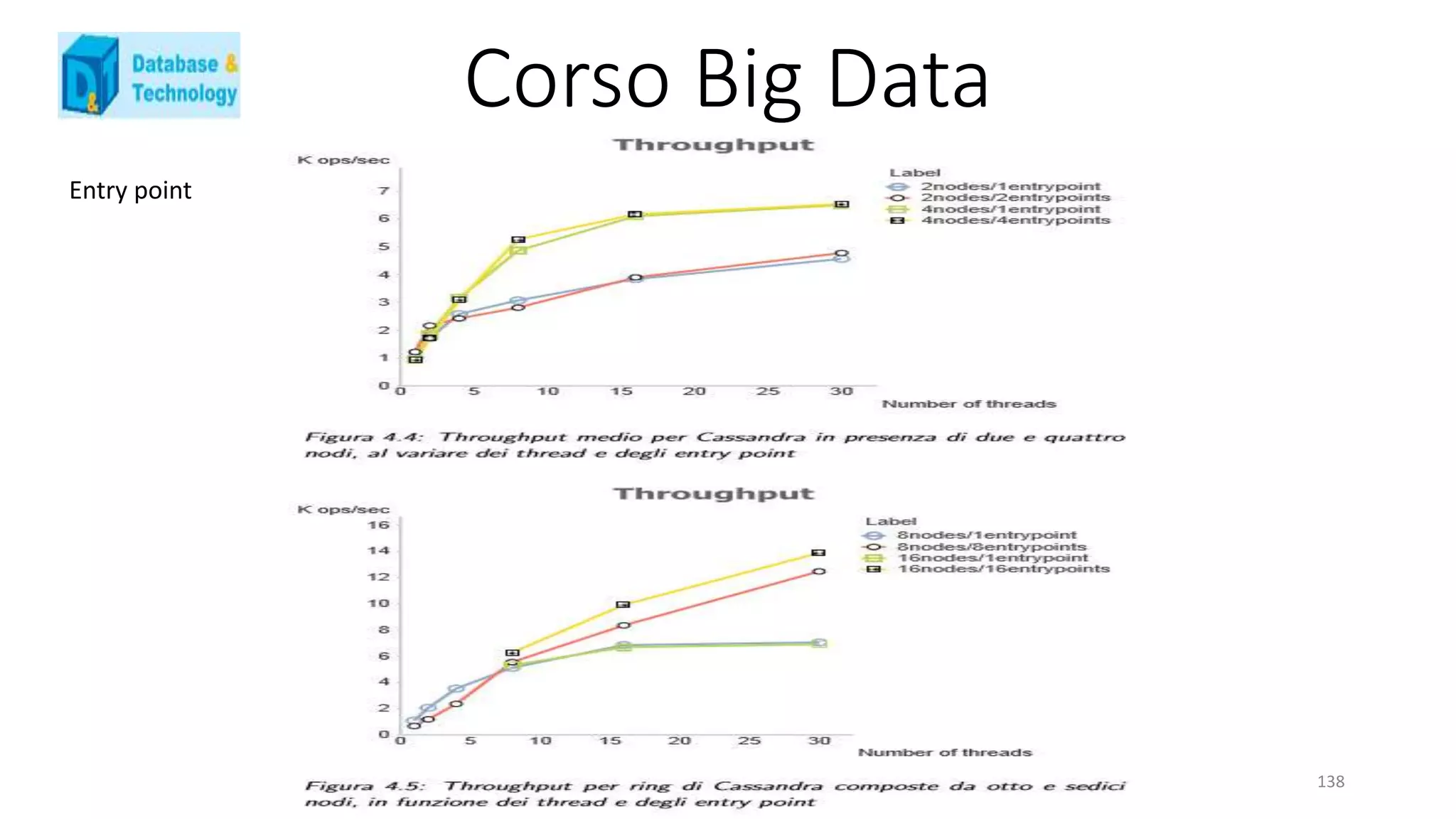
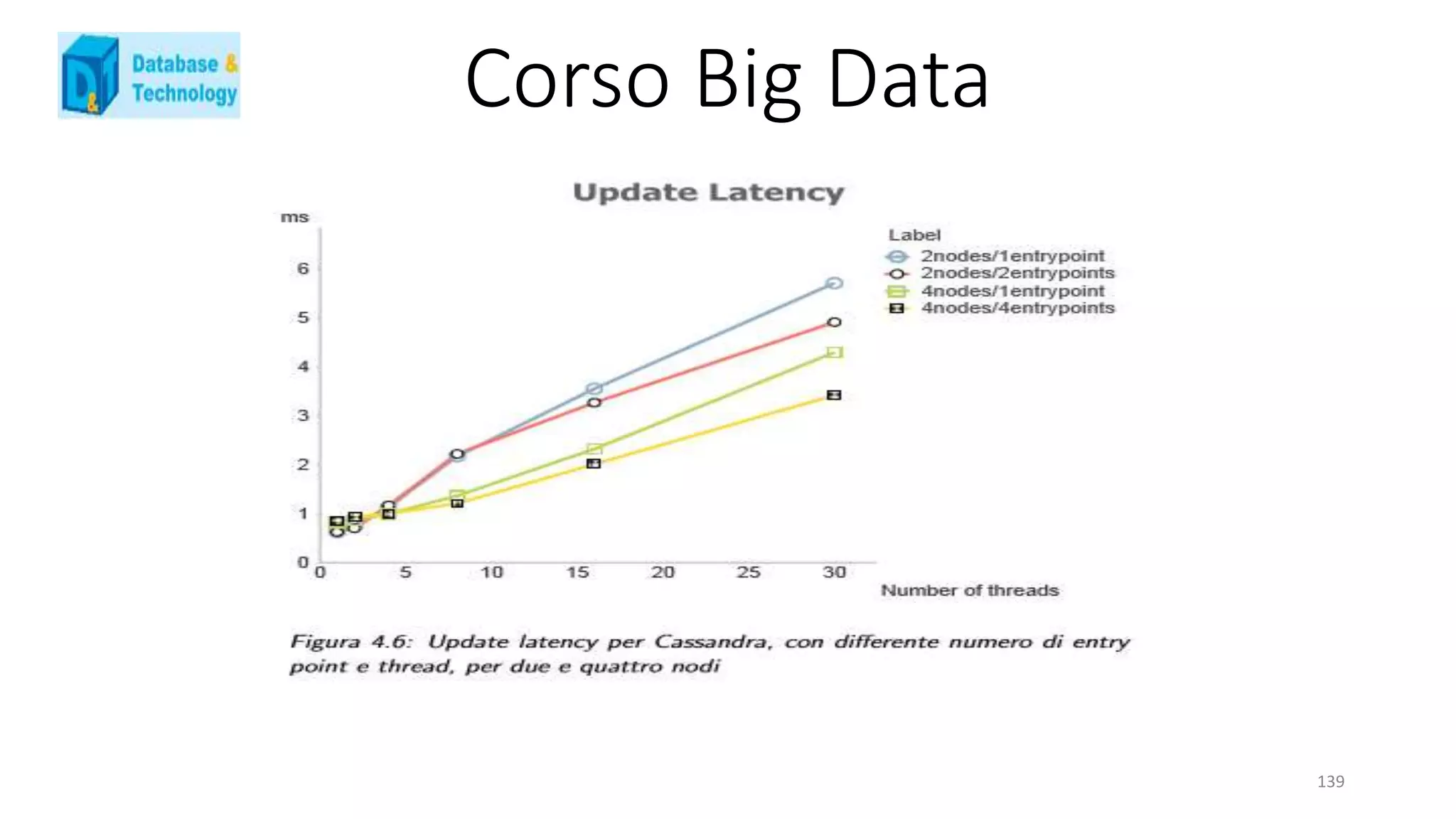
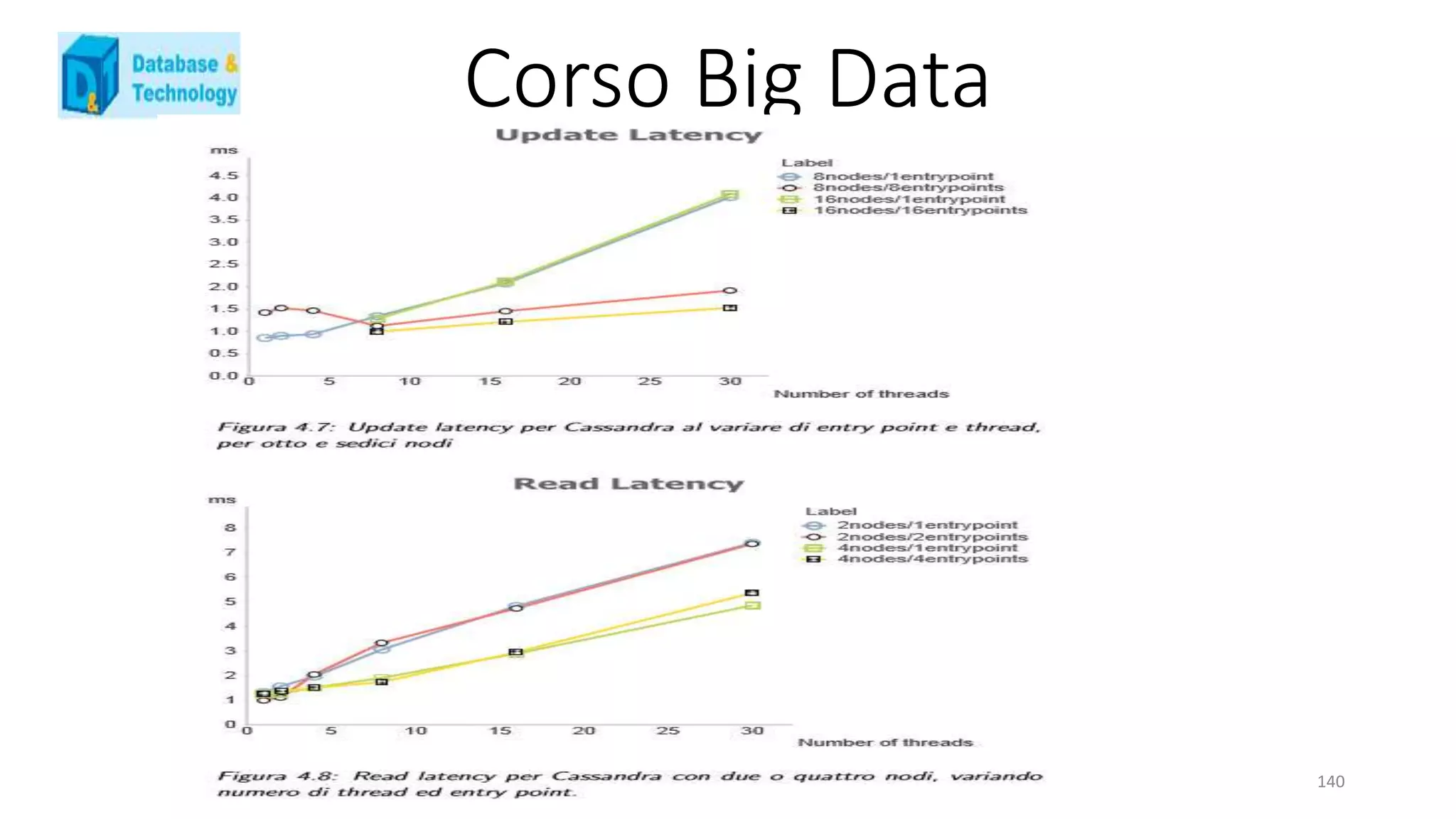
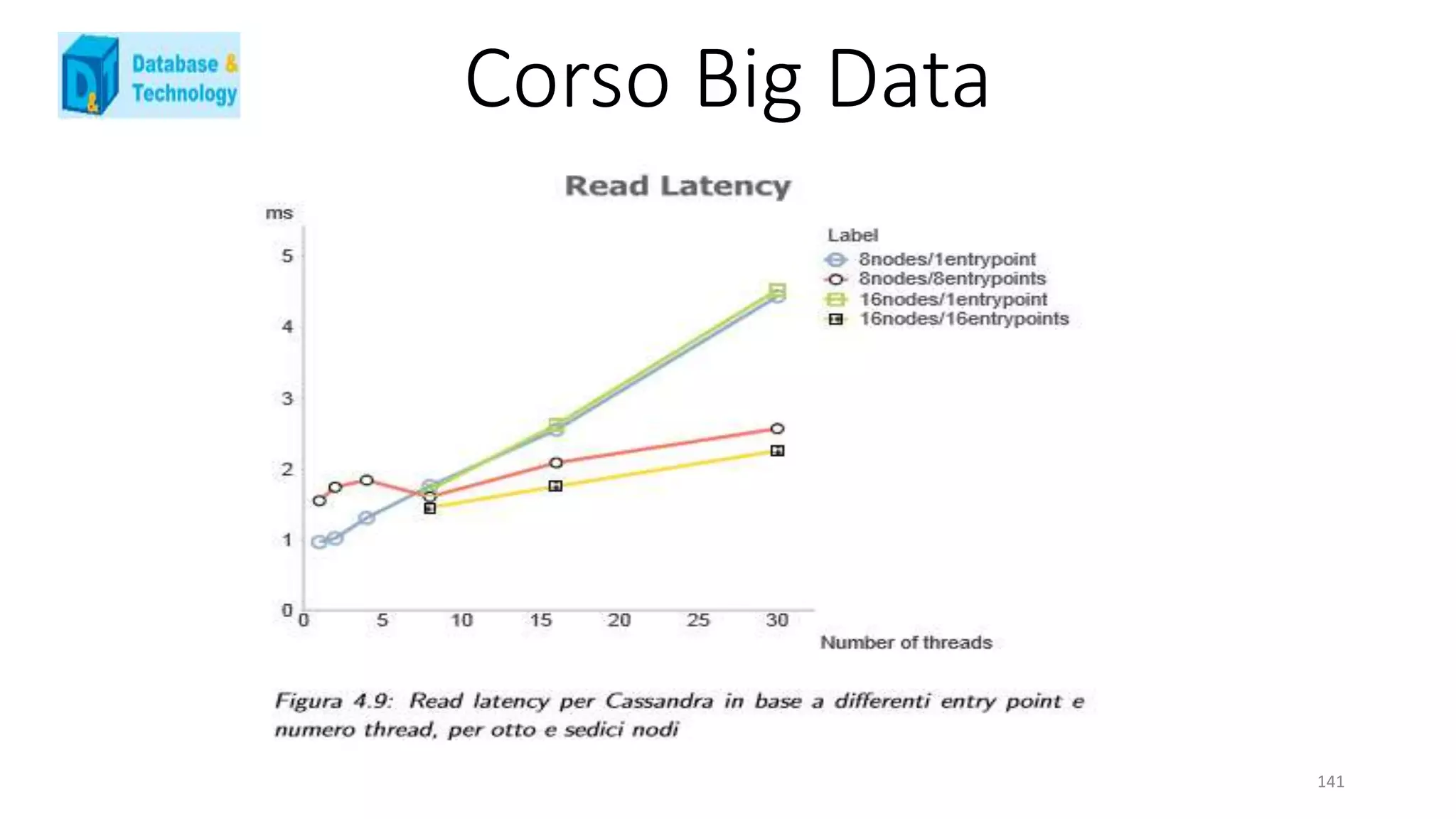
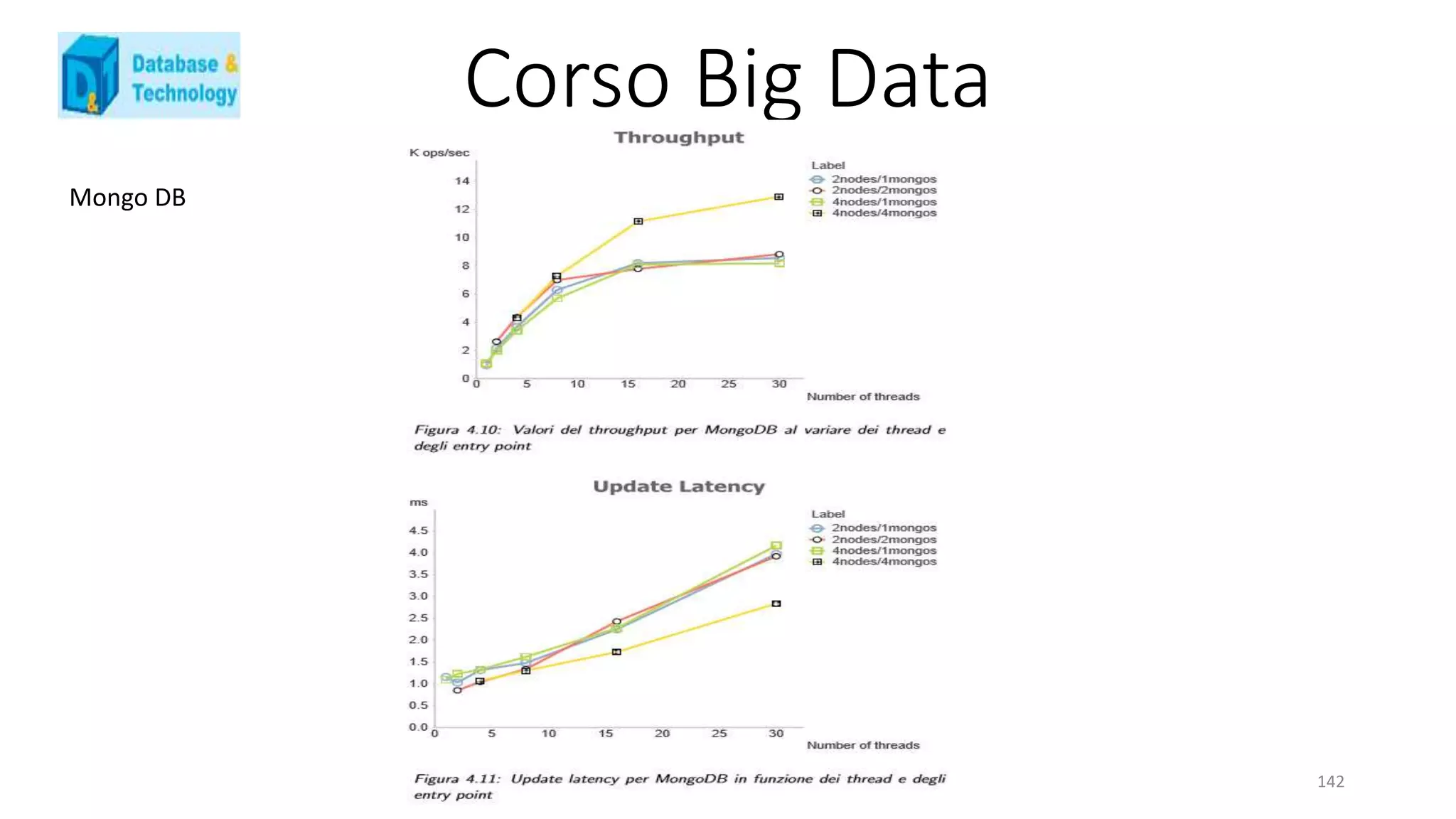
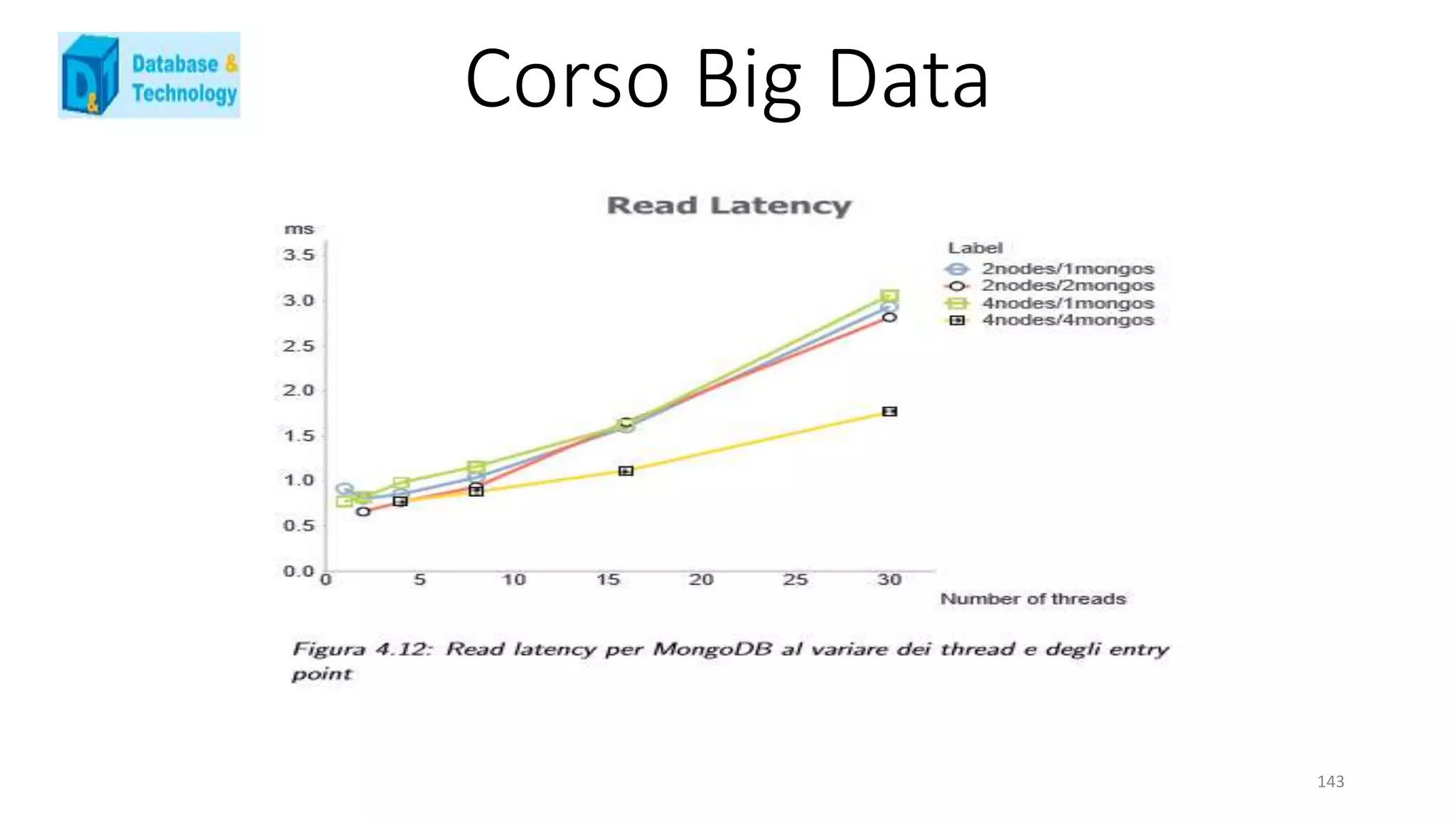
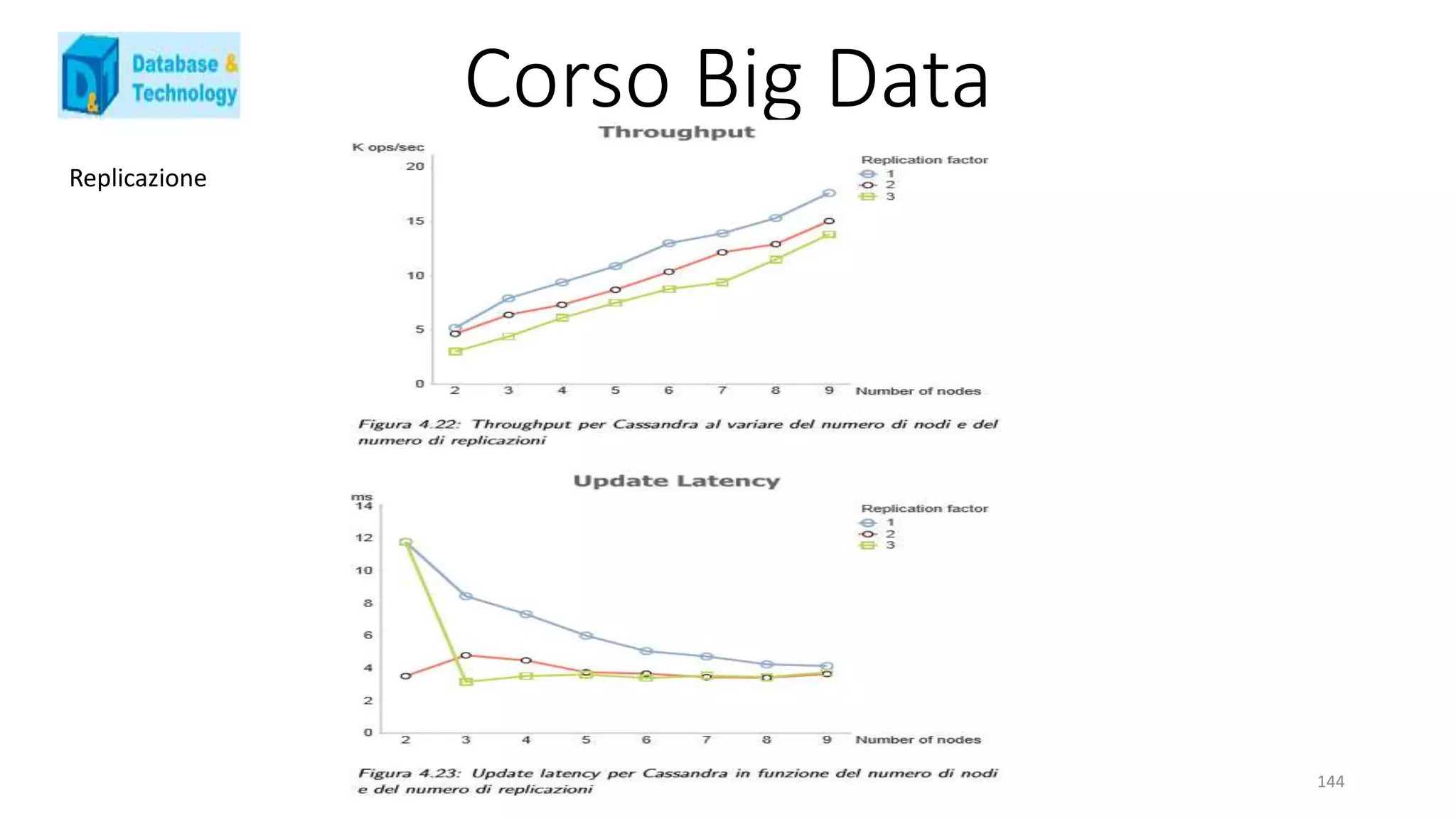














![Corso Big Data
163
SOA
Argomenti
introduzione
SOA come stile architetturale [SAP]
SOA e obiettivi di business I
dai servizi alle SOA
principi per la progettazione dei servizi
SOA e obiettivi di business II
SOA e Layers
enterprise service bus
discussione](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-163-2048.jpg)














![Corso Big Data
178
SOA – Service-Oriented Architecture [SEI]
un servizio è un’implementazione di un pezzo ben definito di
funzionalità di business – con un’interfaccia che è pubblicata e
può essere cercata/trovata – che può essere usato da
consumatori di servizi nella costruzione di diversi processi di
business e applicazioni
SOA è un approccio architetturale per costruire sistemi e
applicazioni che usano un insieme di servizi – e non solo un
singolo sistema come un insieme di servizi](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-178-2048.jpg)
![Corso Big Data
179
SOA – Service-Oriented Architecture [Marks&Bell]
un servizio è una funzionalità di business con un’interfaccia
esposta, che può essere invocato dai suoi consumatori
mediante messaggi
SOA è un’architettura concettuale di business in cui le
funzionalità di business (logica applicativa) vengono esposte
agli utenti SOA come servizi riusabili e condivisi in rete
un servizio è un’unità, modulare e riusabile, di capacità di
business, processo o funzione tecnica, che può essere
acceduto/utilizzato in modo ripetuto da una molteplicità di
consumatori
i servizi sono la risorsa architetturale primaria di una SOA
SOA è una disciplina critica per far sì che i servizi lavorino
insieme per aiutare l’organizzazione a raggiungere i propri
obiettivi di business](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-179-2048.jpg)
![Corso Big Data
180
SOA – Service-Oriented Architecture [Papazoglou]
lo scopo essenziale di una SOA è di abilitare l’interoperabilità
tra tecnologie esistenti, nonché l’estendibilità a scopi e
architetture futuri ....
SOA è uno stile architetturale il cui obiettivo è consentire alle
organizzazioni di sviluppare, connettere e mantenere
applicazioni e servizi di tipo enterprise in modo efficiente ed
economico
una SOA fornisce un insieme di linee guida, principi e tecniche
per cui i beni, le informazioni, e i processi di business di
un’organizzazione possono essere ri-organizzati efficacemente
per sostenere e abilitare piani strategici e livelli di produttività
come richiesto da ambienti di business competitivi](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-180-2048.jpg)
![Corso Big Data
181
Il cloud computing è [NIST]
un modello di elaborazione
che abilita un accesso in rete, su richiesta, ubiquo e
conveniente
a un pool di risorse di calcolo (CPU, storage, reti, sistemi
operativi, servizi e/o applicazioni) condivise e configurabili
che possono essere acquisite e rilasciate rapidamente e in
modo dinamico
con uno sforzo di gestione minimo, o comunque con
un’interazione minima con il fornitore del servizio](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-181-2048.jpg)


![Corso Big Data
184
Cinque caratteristiche essenziali per il cloud computing [NIST]
pooling di risorse
le risorse di calcolo del fornitore del servizio sono riunite per
servire una molteplicità di consumatori, secondo un modello
multi-tenant (letteralmente, “con più affittuari”)
le risorse fisiche e virtuali sono assegnate e riassegnate
dinamicamente ai consumatori, sulla base delle loro richieste
c’è inoltre un’indipendenza dalla locazione – i consumatori
non hanno né controllo né conoscenza della locazione
esatta delle risorse che gli sono assegnate
è tuttavia possibile che i consumatori abbiano controllo
sulla locazione a un livello di astrazione più alto, ad
esempio la nazione (spesso è necessario per motivi di
legge)](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-184-2048.jpg)
![Corso Big Data
185
Cinque caratteristiche essenziali per il cloud computing [NIST]
elasticità rapida
le capacità di calcolo possono essere ottenute in modo
rapido e elastico, e in alcuni casi questo può avvenire
automaticamente
elasticità – è possibile scalare rapidamente queste capacità
di calcolo – sia all’insù che all’ingiù
per il consumatore del servizio, queste capacità di calcolo
spesso appaiono illimitate, e possono essere acquisite in
qualunque momento e in qualunque quantità](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-185-2048.jpg)
![Corso Big Data
186
Cinque caratteristiche essenziali per il cloud computing [NIST]
misura dei servizi
i sistemi di cloud computing controllano e ottimizzano in
modo automatico l’uso delle risorse, sulla base di misure
appropriate per il tipo del servizio – ad es., per lo storage,
sia la quantità memorizzata che la quantità mossa nel tempo
la misurazione dell’uso delle risorse fornisce trasparenza sia
al fornitore che al consumatore del servizio utilizzato](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-186-2048.jpg)
![Corso Big Data
187
Il cloud computing è [Vaquero]
un grande insieme di risorse (come hardware, piattaforme di
sviluppo e/o servizi)
che sono virtualizzate
e sono facilmente accessibili e usabili
queste risorse
possono essere dinamicamente riconfigurate – per adattarle
a un carico variabile (sono scalabili) – favorendo un utilizzo
ottimale delle risorse
sono tipicamente utilizzate sulla base di un modello di
pagamento a consumo
sono dotate di garanzie – sulla base di SLA personalizzate –
offerte dal loro fornitore](https://image.slidesharecdn.com/681e6b6e-16f0-43ad-9c59-614ea1bf93d6-160119102040/75/FANTIN-BIG-DATA-1-187-2048.jpg)















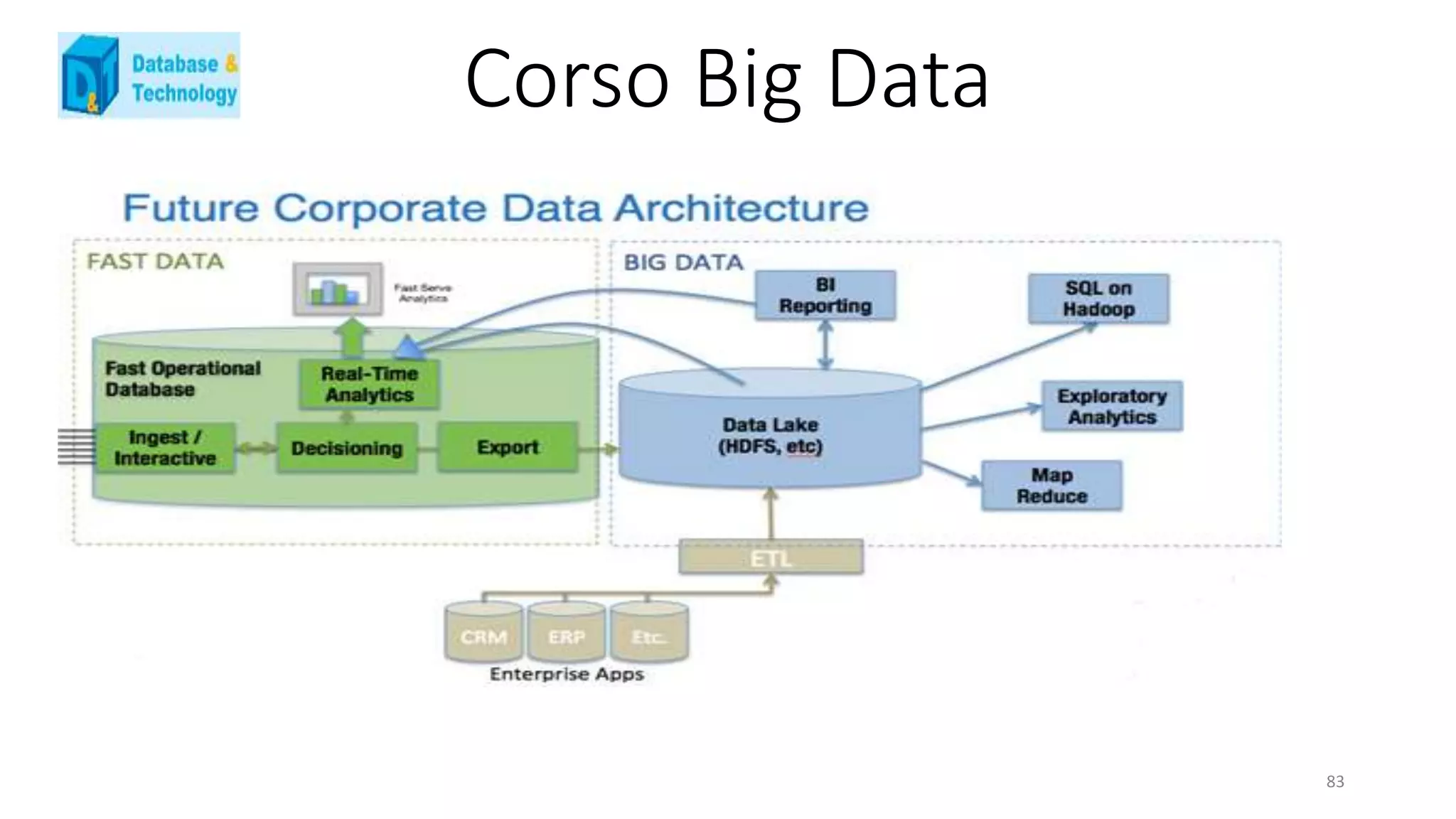
Il documento analizza il panorama dei big data in Italia nel 2013, evidenziando la scarsità di aziende che necessitano effettivamente di gestire grandi volumi di dati e la prevalenza di strumenti tradizionali come business intelligence e data mining. Viene discussa l'importanza di creare architetture integrative per ottimizzare la gestione dei dati e le opportunità di business derivanti da un uso efficace dei big data all'interno delle aziende, con riferimenti a casi reali e sfide operative. Infine, emergono considerazioni sull'evoluzione verso modelli predittivi e sulla necessità di adattare le competenze professionali alle nuove esigenze del mercato.























































