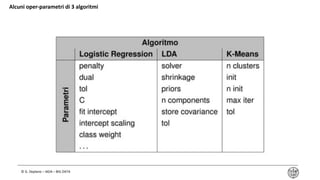
Il documento tratta del machine learning nel contesto dei big data, esplorando le definizioni, i casi d'uso e i vari tipi di apprendimento, tra cui supervisionato, non supervisionato, semi-supervisionato e rinforzato. Viene analizzata la scelta degli algoritmi e gli errori del modello, inclusi bias e varianza, con focus sulla variabilità intrinseca e sull'errore totale. Infine, il documento offre una panoramica di alcune applicazioni pratiche, come le raccomandazioni e l'analisi medica.