Downloaded 10 times










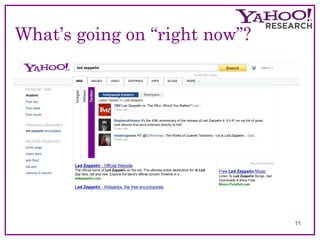














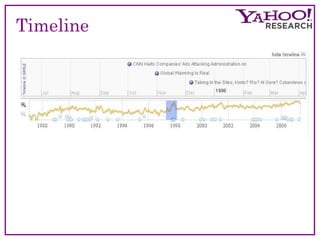




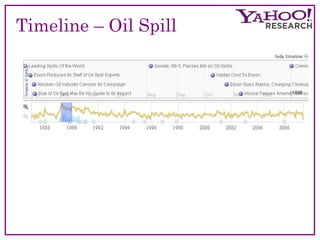

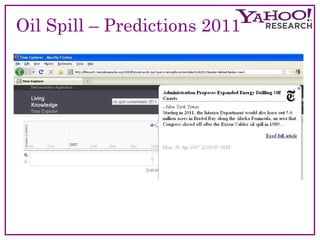





The document discusses the evolution and current methodologies in web search engines, particularly focusing on incorporating temporal dimensions into search processes. It highlights challenges related to information freshness, caching strategies, and the analysis of natural language, aiming to enhance user experience over time-based searches. The 'Time Explorer' project is presented as a tool for exploring news through time, analyzing how topics and sentiments evolve, and providing a robust platform for future prediction and understanding.






























































































