Automated Test CaseRepair Using
Language Models
Ahmadreza Saboor Yaraghi • Darren Holden • Nafiseh Kahani • Lionel Briand
IEEE Transactions on Software Engineering 2025
a.saboor@uottawa.ca • darren.holden@carleton.ca • kahani@sce.carleton.ca • lbriand@uottawa.ca
www.nanda-lab.ca
University of Ottawa
School of Electrical Engineering & Computer Science
Nanda Lab
Research supported by Huawei Canada
2.
What is RegressionTesting?
2
Software testing ensures that software works as expected.
It is critical for delivering reliable and functional software.
Regression testing ensures existing functionalities still work when the software
evolves (e.g., bug fixes or new features).
Why regression
testing?
1. Rapid software evolution
2. Interdependent features (small changes can break features)
3.
Motivating Challenges inRegression Testing
3
Regression Testing in Software Systems Test Execution Failure
1. Fault in the
System Under Test
(SUT)
2. Broken Test Code
Challenge: Maintenance Overhead
• Frequent test code changes in fast-evolving systems increase
development costs.
• Ignoring broken tests affects testing quality and software
reliability.
Localizing and fixing
the fault in the SUT Goal: Automated Test Evolution and Repair
4.
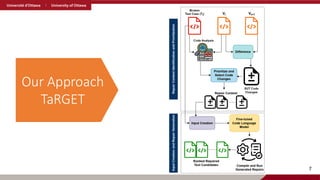
Broken Test RepairMotivating Example
4
SUT Test Case
Code Changes (Hunks) in the SUT, adding
the currency feature
Test Case Repair
5.
Limitations of ExistingWork
5
Most approaches target specific repair categories (e.g., assertions).
Most existing benchmarks are limited in size and diversity (e.g., only
91 broken test instances across four projects).
Most existing approaches lack reproducibility due to missing
publicly available replication packages.
6.
Contributions (Automated TestCase Repair)
1. TaRGET (Test Repair GEneraTor)
• Using fine-tuned code language models (CLMs)
• Not limited to specific repair categories or programming languages
2. TaRBench (Test Repair Benchmark)
• Large and diverse benchmark
• Includes 45.3k instances across 59 projects
3. Addressed three research questions (RQs)
• Evaluated CLM performance and data formatting (prompting)
• Analyzed factors impacting performance
6
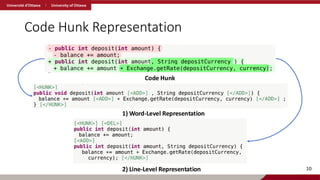
The Input andOutput Format
1. Test Context
• Broken test code and broken line(s)
2. Repair Context
• SUT code changes (hunks) relevant for
the repair
8
Input
Output
9.
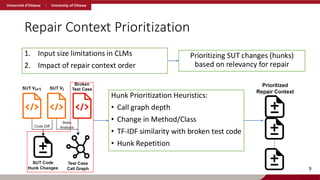
Repair Context Prioritization
1.Input size limitations in CLMs
2. Impact of repair context order
9
Prioritizing SUT changes (hunks)
based on relevancy for repair
Hunk Prioritization Heuristics:
• Call graph depth
• Change in Method/Class
• TF-IDF similarity with broken test code
• Hunk Repetition
Input-Output Formats Overview
•Repair Context
• R: All SUT hunks
• Rm⊂ R: Method-level hunks within
test call graph
• Rc⊂ R : Class-level hunks within
test call graph
12
• Hunk Prioritization
• CGD: Call Graph Depth
• CT: Context Type (method/class)
• BrkSim: TF-IDF similarity with broken code
• TSim: TF-IDF similarity with test code
• Rep: Number of hunk repetition
13.
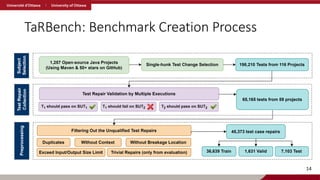
TaRBench: Collecting ValidTest Repairs
• We detect valid repairs through three executions:
1. Test V1 on SUT V1 should pass
2. Test V1 on SUT V2 should fail
3. Test V2 on SUT V2 should pass
13
SUT V1 SUT V2
Test Case V1 Test Case V2
Update
Code Change
(Potential Repair)
1
2
3
Research Questions
RQ1: RepairPerformance
RQ1.1: CLMs and Input-Output Formats
RQ1.2: TaRGET Against Baselines
RQ2: Repair Analysis
RQ2.1: Analyzing Repair Characteristics
RQ2.2: Predicting Repair Trustworthiness
RQ3: Fine-tuning analysis
RQ3.1: Analyzing Fine-tuning Data Size
RQ3.2: Assessing Model Generalization
15
16.
Evaluation Metrics
Exact MatchAccuracy (EM)
Measures repair candidates that exactly
match the ground truth
Plausible Repair Accuracy (PR)
Measures repair candidates that
successfully compile and pass
BLEU and CodeBLEU
Measure textual similarities between the
repair candidate and the ground truth
16
17.
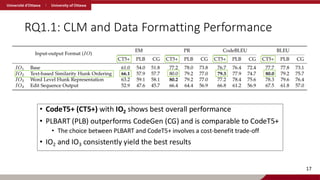
RQ1.1: CLM andData Formatting Performance
• CodeT5+ (CT5+) with IO2 shows best overall performance
• PLBART (PLB) outperforms CodeGen (CG) and is comparable to CodeT5+
• The choice between PLBART and CodeT5+ involves a cost-benefit trade-off
• IO2 and IO3 consistently yield the best results
17
18.
RQ1.2: TaRGET AgainstBaselines
• Baselines:
• CEPROT [1] (SOTA): Automatically detects and updates obsolete tests using a
fine-tuned CodeT5 model and introduces a new dataset.
• NoContext: Fine-tuning CodeT5+ without repair context
• SUTCopy: Replicating SUT changes in test code if applicable
18
[1] X. Hu, Z. Liu, X. Xia, Z. Liu, T. Xu, and X. Yang, “Identify and update test cases when production code changes: A transformer-based approach,” in 2023 38th IEEE/ACM
International Conference on Automated Software Engineering (ASE), 2023, pp. 1111–1122.
Benchmark Approach EM
214 test set
instances of
CEPROT
TaRGET 40.6%
CEPROT 21%
Benchmark Approach EM
7,103 test set
instances of
TaRBench
TaRGET 66%
NoContext 29%
SUTCopy 11%
19.
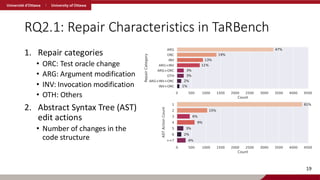
RQ2.1: Repair Characteristicsin TaRBench
19
1. Repair categories
• ORC: Test oracle change
• ARG: Argument modification
• INV: Invocation modification
• OTH: Others
2. Abstract Syntax Tree (AST)
edit actions
• Number of changes in the
code structure
20.
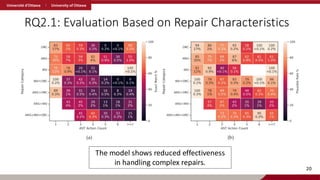
RQ2.1: Evaluation Basedon Repair Characteristics
20
The model shows reduced effectiveness
in handling complex repairs.
21.
RQ2.2: Predicting RepairTrustworthiness
• Created a Random Forest classifier utilizing test and repair context (input)
features
• Results show high accuracy in prediction:
• Practical Implications
1. Enhances TaRGet’s practicality
2. Saves time by avoiding low-quality repairs
21
22.
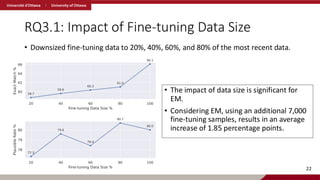
RQ3.1: Impact ofFine-tuning Data Size
• Downsized fine-tuning data to 20%, 40%, 60%, and 80% of the most recent data.
22
• The impact of data size is significant for
EM.
• Considering EM, using an additional 7,000
fine-tuning samples, results in an average
increase of 1.85 percentage points.
23.
RQ3.2: Assessing Generalization
•Stratified project exclusion from fine-tuning data:
• Creating 10 folds, each excluding six projects
• Keeping the evaluation set unchanged
• Fine-tuned 10 project-agnostic models based on the above folds
23
• Project-agnostic models are acceptable alternatives, with an average
difference of 4.9 EM points.
• TaRGet can effectively generalize to unseen projects.
24.
TaRGET and Advancesin Foundation Models (FM)
• TaRGET’s challenges: (1) Time-intensive data preparation for fine-tuning,
(2) Expensive fine-tuning process, (3) Limited context window
• FM’s challenges: (1) Lower task-specific performance, (2) Data privacy
concerns
• Advancements in FMs since TaRGET
• Large context (up to 1M in GPT-4.1), RAG techniques, multi-agent solutions, and
reasoning capability (O3, DeepSeek R1)
• Future research can utilize FM to
1. Overcome TaRGET’s existing challenges (e.g., aiding data preparation)
2. Improve components of TaRGET’s approach (e.g., using RAG for repair context)
3. Explore trade-offs: When is fine-tuning worth it?
24
25.
Summary
1. TaRGET showsthat CLMs can be effectively tailored for repairing
tests, achieving 66% EM and 80% PR.
2. TaRGET significantly outperforms the baselines, highlighting
importance of input-output formatting and repair context selection.
3. We introduce TaRBench, the most comprehensive benchmark
available.
4. Using our proposed repair trustworthiness predictor, TaRGET can be
utilized effectively.
5. TaRGET has the capability to generalize across new projects.
25
26.
Publication
• This workwas recently accepted for publication by IEEE Transactions
on Software Engineering (TSE), 2025.
26
https://doi.org/10.1109/TSE.2025.3541166













![RQ1.2: TaRGET Against Baselines
• Baselines:
• CEPROT [1] (SOTA): Automatically detects and updates obsolete tests using a
fine-tuned CodeT5 model and introduces a new dataset.
• NoContext: Fine-tuning CodeT5+ without repair context
• SUTCopy: Replicating SUT changes in test code if applicable
18
[1] X. Hu, Z. Liu, X. Xia, Z. Liu, T. Xu, and X. Yang, “Identify and update test cases when production code changes: A transformer-based approach,” in 2023 38th IEEE/ACM
International Conference on Automated Software Engineering (ASE), 2023, pp. 1111–1122.
Benchmark Approach EM
214 test set
instances of
CEPROT
TaRGET 40.6%
CEPROT 21%
Benchmark Approach EM
7,103 test set
instances of
TaRBench
TaRGET 66%
NoContext 29%
SUTCopy 11%](https://image.slidesharecdn.com/fsetesting11420ahmadrezasabooryaraghiautomated-read-only-250624141233-63dab101/85/Automated-Test-Case-Repair-Using-Language-Models-18-320.jpg)






































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
