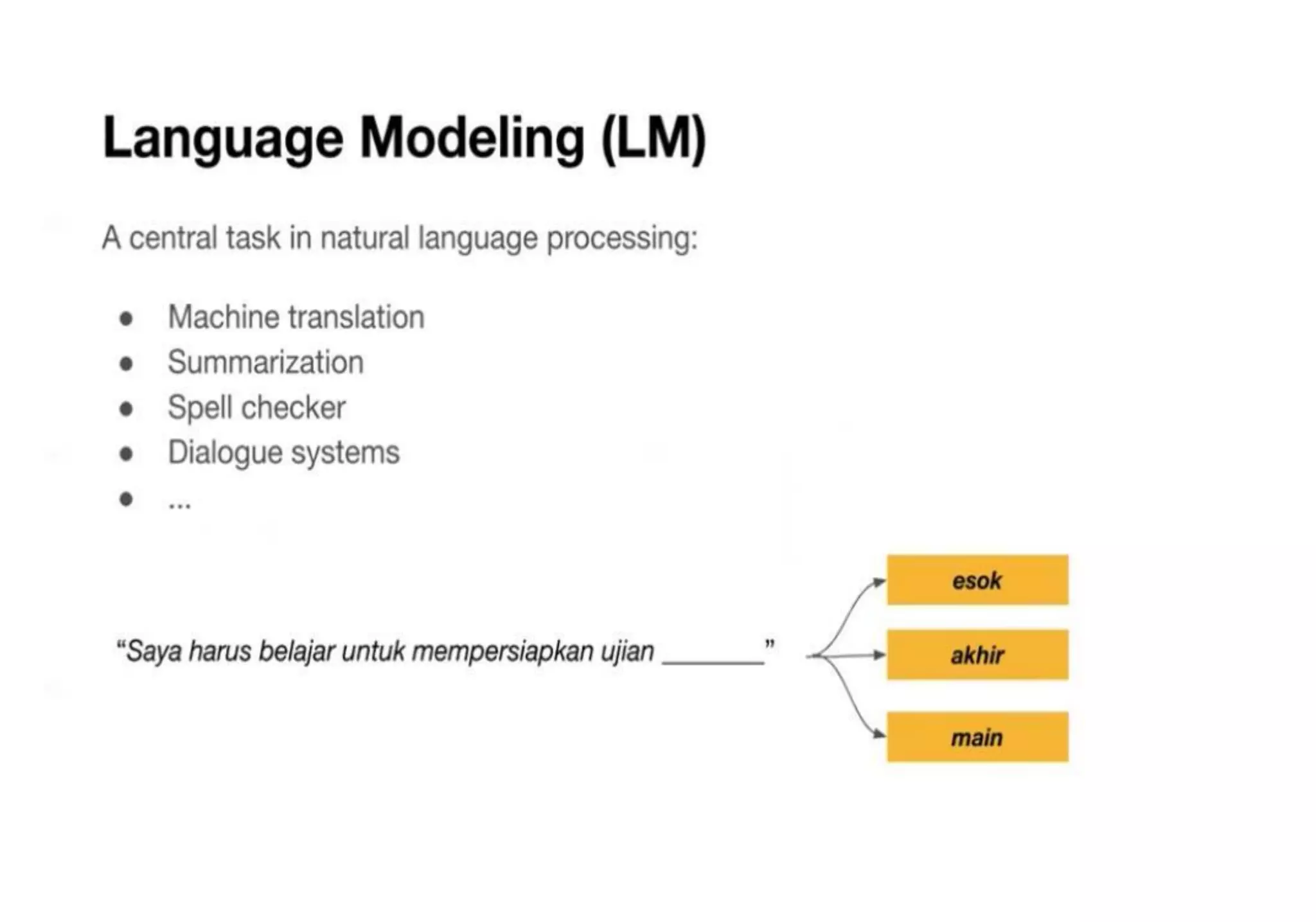
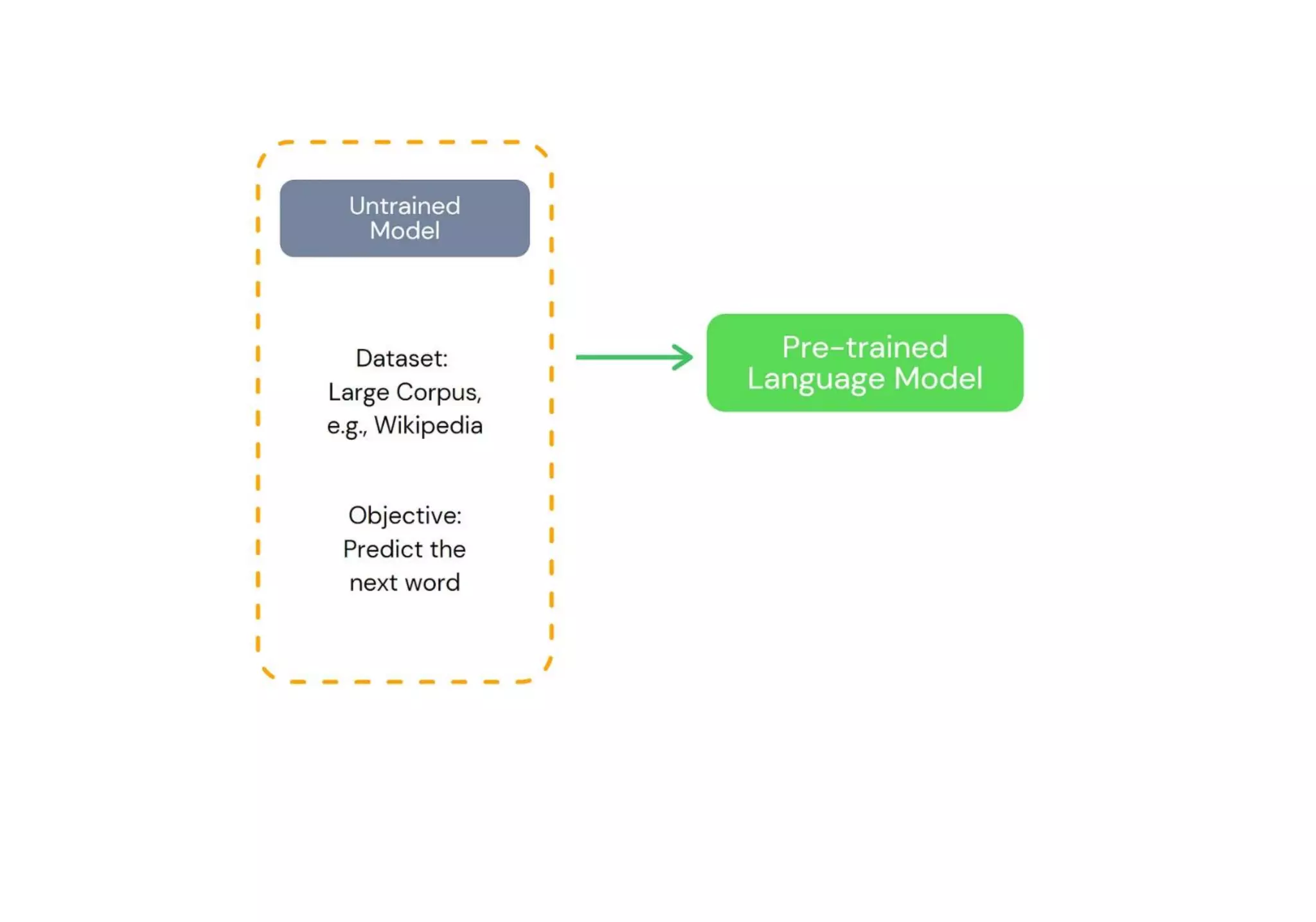
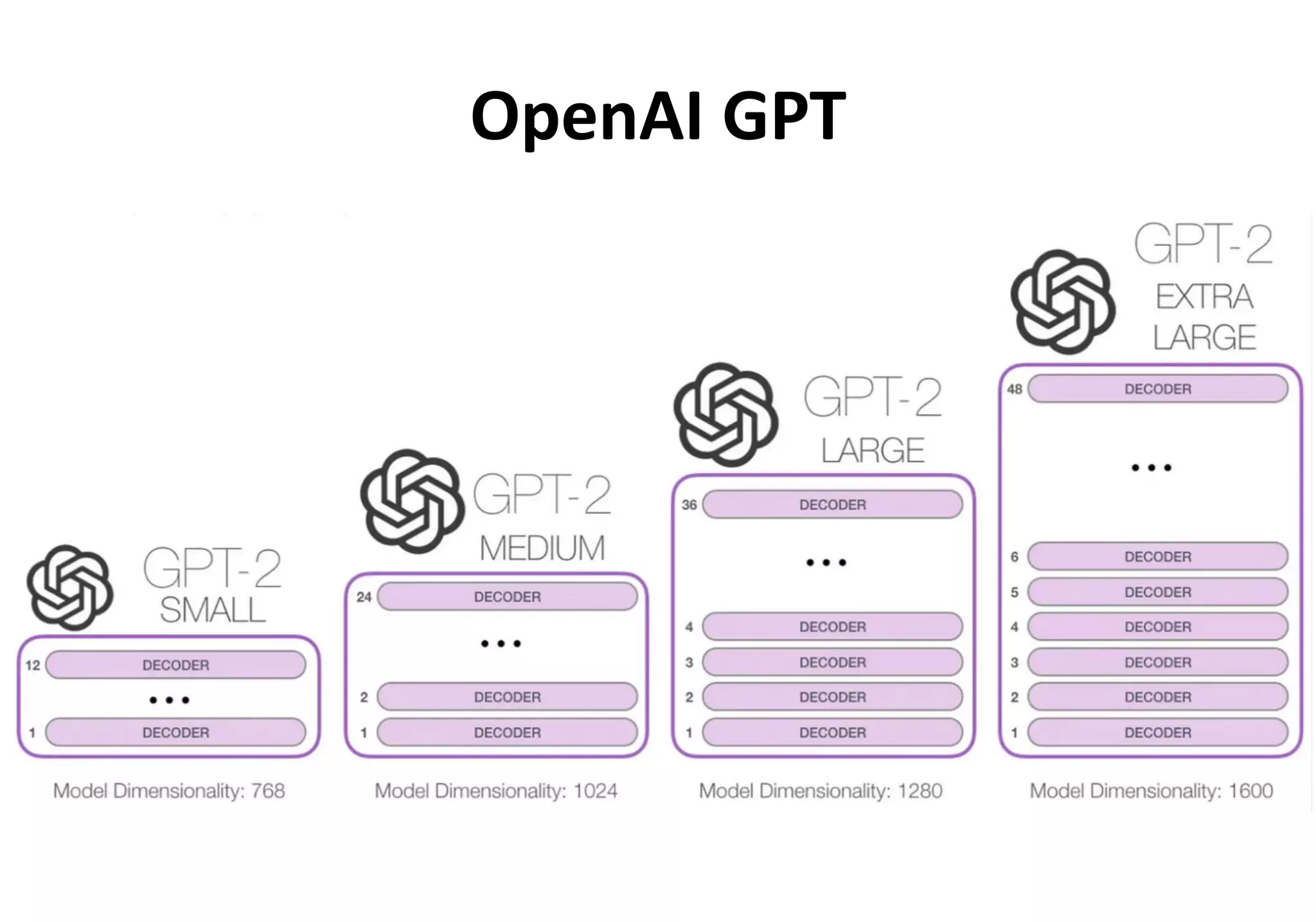
Teks tersebut membahas tentang pemodelan bahasa dan pemrosesan bahasa alami dengan menggunakan model probabilitas dan pembelajaran mesin, termasuk model n-gram, GPT, dan BERT. Teks tersebut juga membandingkan pendekatan GPT dan BERT dalam melatih model bahasa.