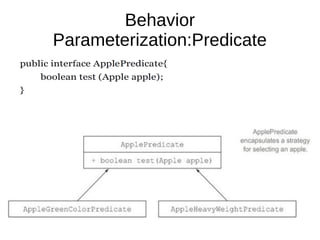
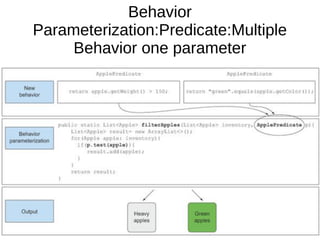
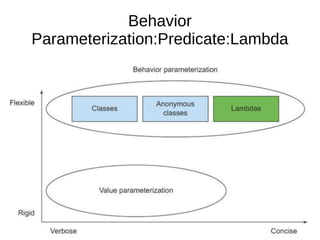
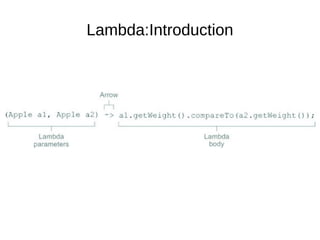
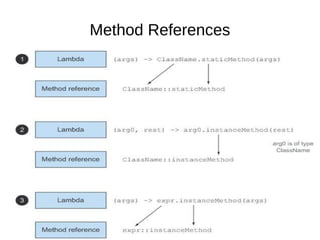
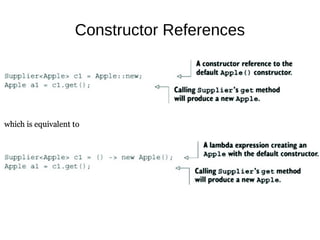
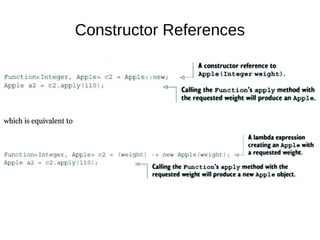
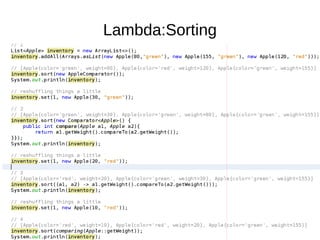
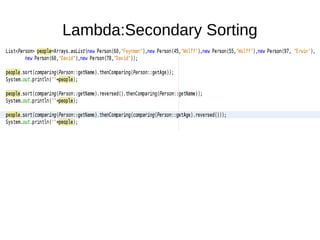
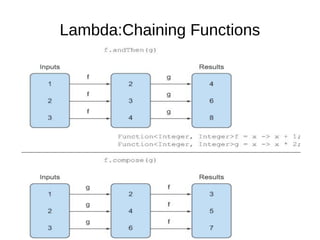
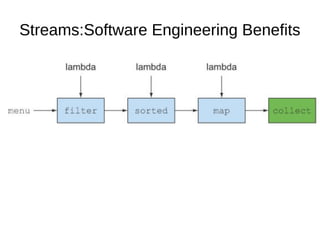
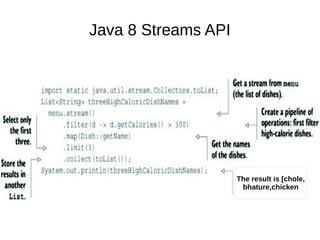
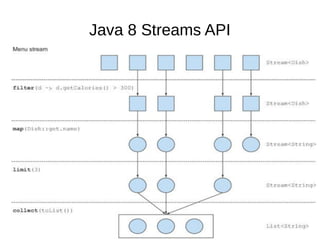
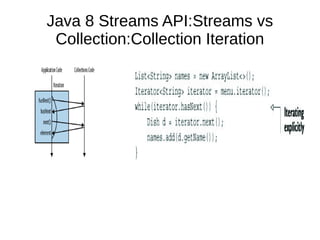
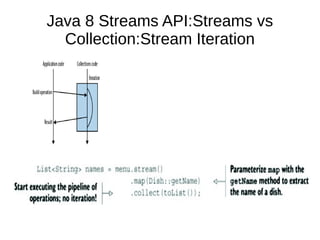
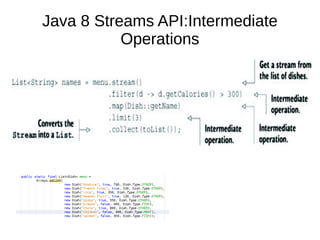
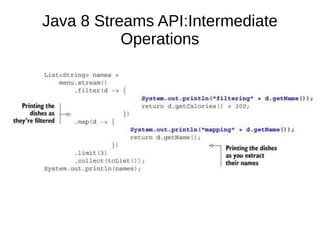
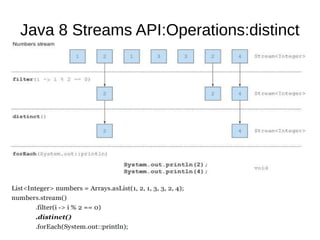
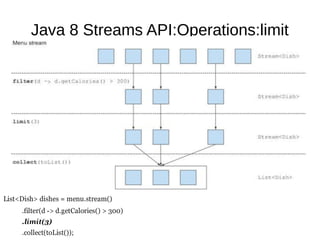
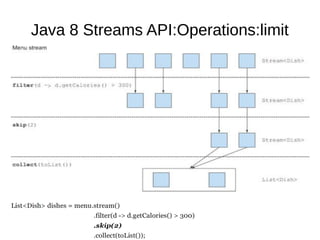
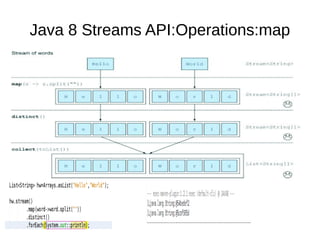
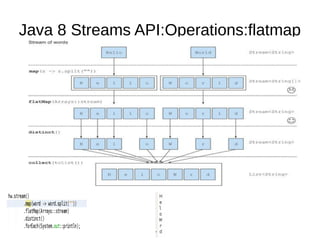
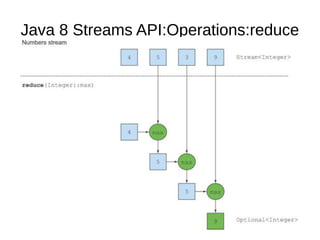
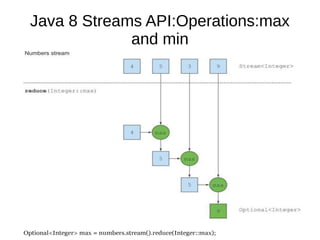
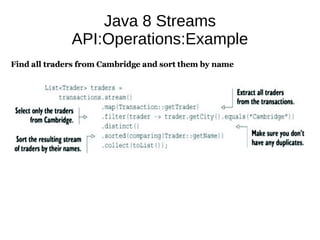
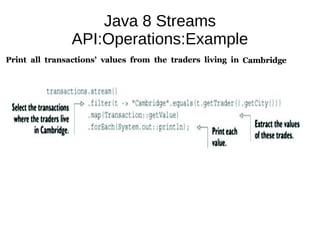
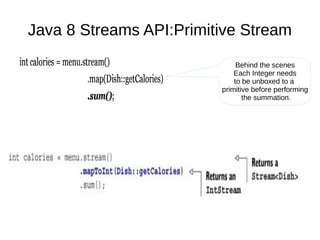
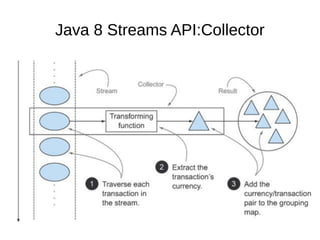
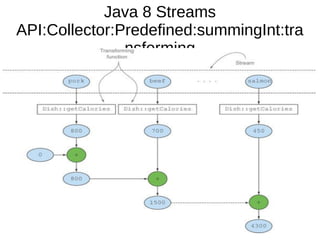
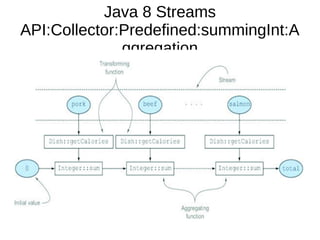
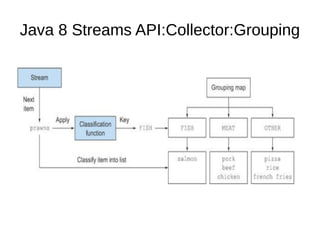
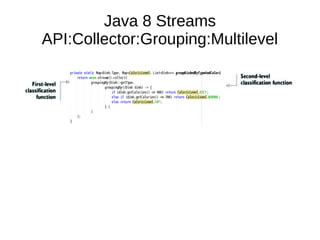
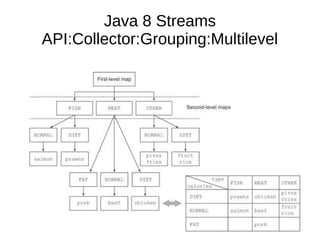
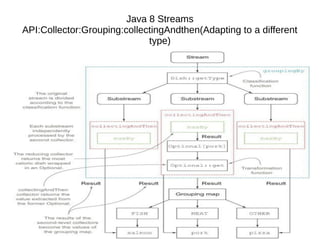
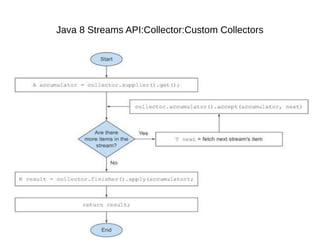
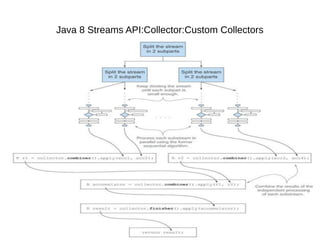
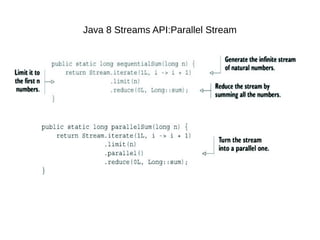
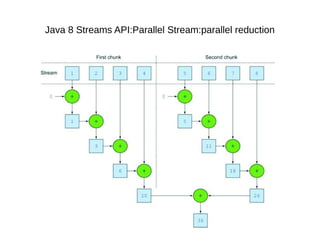
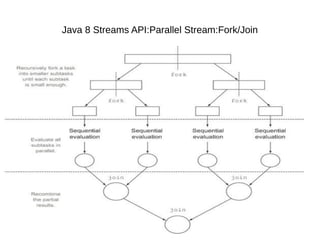
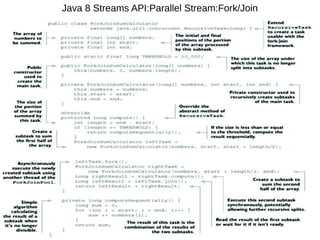
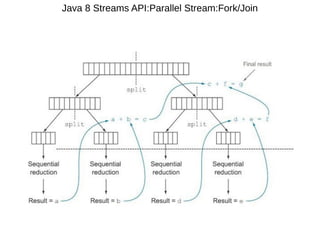
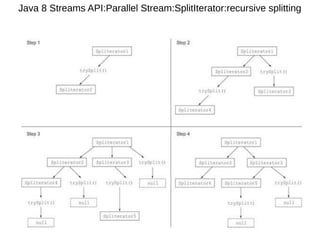
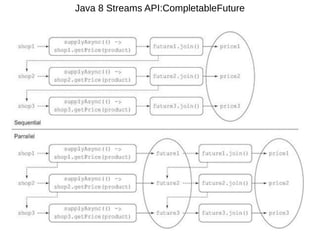
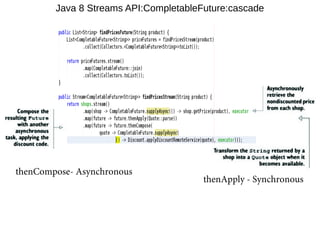
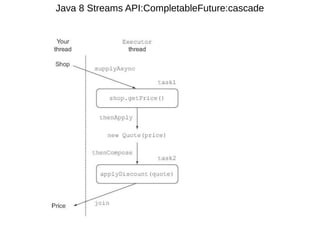
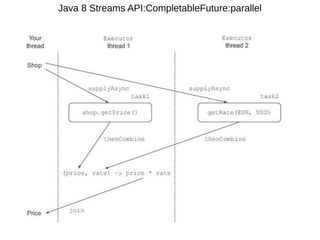
This document provides information about parameterization and lambda expressions in Java. It discusses how parameterization allows functions to be configured through parameters. Lambda expressions are described as anonymous functions that can be passed as arguments or stored in variables. The document outlines the benefits of streams in Java 8 for processing data in a declarative way through composable and parallelizable operations like filter, map, and reduce. It compares streams to collections and explains intermediate and terminal stream operations.