Download as PDF, PPTX
![1
POSE & OCCLUSION ROBUST FACE
ALIGNMENT USING MULTIPLE SHAPE MODELS
AND PARTIAL INFERENCE
- PhD Thesis Proposal -
Jongju Shin
[jjshin@postech.ac.kr]
Advisor : Daijin Kim
2013.01.03
I.M. Lab.
Dept. of CSE](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-1-320.jpg)







![9
Previous work
Previous work
• 1. Discriminative approach
Constrained Local Model[1] Bayesian Tangent Shape Model[2]
• Feature detector : Linear SVM • Feature detector : gradient along normal vector
• Alignment algorithm : Mean-shifts • Alignment algorithm : Bayesian Inference
• They assume that all the feature points are visible.
• By the wrong detected feature points, alignment fails.
[1] Jason et al., “Face Alignment through Subspace Constrained Mean-Shifts”, ICCV 2009
[2] Yi et al., “Bayesian Tangent Shape Model:Estimating Shape and Pose Parameters via Bayesian Inference”, CVPR 2003](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-9-320.jpg)
![10
Previous work
Previous work
• 2. Generative approach
Boosted Appearance Model[3] Fourier Active Appearance Model[4]
• Appearance model : Haar-like feature • Appearance model : Fourier transformed
and boosting. appearance
• Weak classifier : discriminate aligned • Alignment algorithm : gradient descent
images from not-aligned images.
• Due to high dimensional solution space, it has large number of
local minimums.
• They need good initialization by eye detection.
[3] Xiaoming Liu, “Generic Face Alignment using Boosted Appearance Model”, CVPR 2007
[4] Rajitha, et al., “Fourier Active Appearance Models”, ICCV 2011](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-10-320.jpg)






![17
Proposed method
Algorithm Overview
Model Hypotheses
[Input] Evaluation
Local Feature Detection
[Output]
[Hypothesis-and-test]
Hypothesizing
Transformation Parameters
Face Hypothesizing
Detection Shape Parameters](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-17-320.jpg)
![18
Proposed method
Local Feature Detection
Model Hypotheses
[Input] Evaluation
Local Feature Detection
[Output]
[Hypothesis-and-test]
Hypothesizing
Transformation Parameters
Face Hypothesizing
Detection Shape Parameters](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-18-320.jpg)
![19
Proposed method
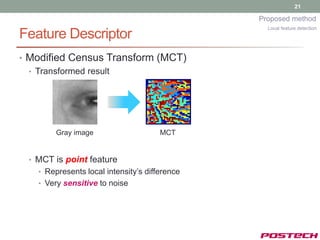
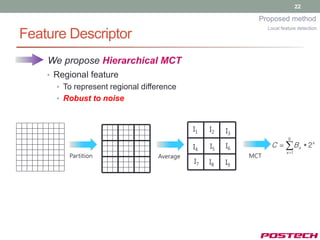
Local feature detection
Local Feature Detection
• Goal
Detect feature point candidates with Gaussian Model!
• Based on MCT+Adaboost algorithm [5],
• We propose Hierarchical MCT to increase detection
performance.
[5] Jun, and Kim, “Robust Real-Time Face Detection Using Face Certainty Map”, ICB, 2007](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-19-320.jpg)

![25
Proposed method
Local feature detection
Process of local feature detection
[Input] Hierarchical Adaboost Regressed
Search region
MCT Response Response
How to obtain feature point candidates?](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-25-320.jpg)
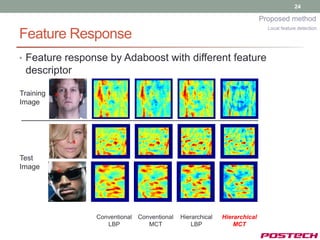
![26
Proposed method
Local feature detection
Representation of Feature Response
• How to obtain feature point candidates?
• Local maximum points in candidate search region
arg max x y, y , and px 0, x is center of
x
Segmented
[Input] Response region](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-26-320.jpg)

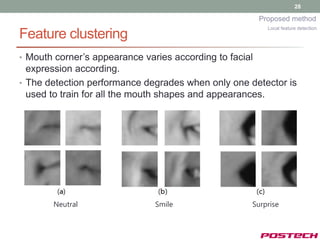
![30
Proposed method
Local feature detection
Local feature detection
…..
..…
[Candidates
[Input] [Search region] [Adaboost [output of detection]
with Gaussian]
Response]](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-30-320.jpg)
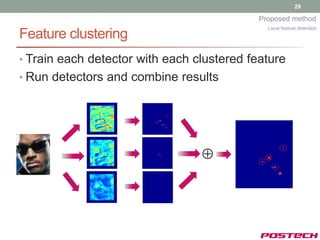
![31
Proposed method
Hypothesizing Transformation Parameters
Model Hypotheses
[Input] Evaluation
Local Feature Detection
[Output]
[Hypothesis-and-test]
Hypothesizing
Transformation Parameters
Face Hypothesizing
Detection Shape Parameters](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-31-320.jpg)
![32
Proposed method
Hypothesizing Hypo. trans. param.
• Goal
Find a best combination of the
local feature point candidates
which represents input image well.
[Feature point candidates]
• Assumption for occlusion
• We assume that at least half of feature points are not occluded.
• Let be N is total number of features points.
• N/2 feature points can be assumed to be visible ones.](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-32-320.jpg)

![34
Proposed method
Hypothesizing Transformation Parameters Hypo. trans. param.
Algorithm 1. Partial Inference (PI) algorithm for transformation parameters
[PI algorithm]](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-34-320.jpg)
![35
Proposed method
Hypothesizing Shape Parameters
Model Hypotheses
[Input] Evaluation
Local Feature Detection
[Output]
[Hypothesis-and-test]
Hypothesizing
Transformation Parameters
Face Hypothesizing
Detection Shape Parameters](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-35-320.jpg)

![37
Proposed method
Hypothesizing shape parameters Hypo. shp. param.
Algorithm 2. Partial Inference (PI) algorithm for shape parameters
[Selected feature points]
[Hallucinated shape]](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-37-320.jpg)

![39
Proposed method
Model Hypothesis Evaluation
Model Hypotheses
[Input] Evaluation
Local Feature Detection
[Output]
[Hypothesis-and-test]
Hypothesizing
Transformation Parameters
Face Hypothesizing
Detection Shape Parameters](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-39-320.jpg)

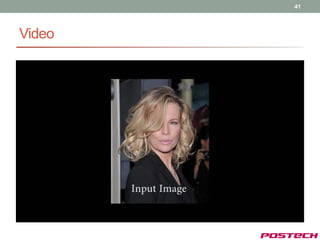

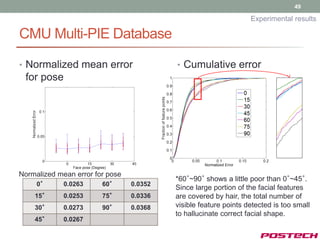
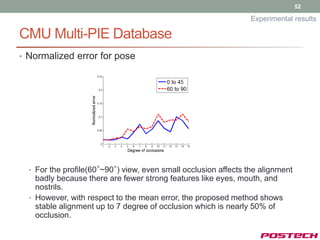
![43
Experimental results
Training database
• CMU Multi-PIE [7]
• Various pose, expression and illumination
• We used 10,948 images among 750,000 images
• 5 Pose models
• 0°, 15°~30°, 30°~45° (70 feature points)
• 60°~75°, and 75°~90° (40 feature points)
• 2 Expression models
• Neutral and smile
• surprise
[7] Ralph et al., “Guide to the CMU Multi-pie database”, Technical report, CMU, 2007](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-43-320.jpg)
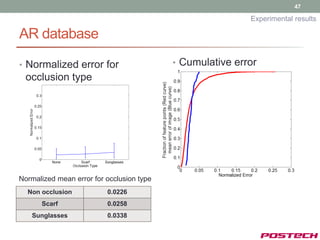
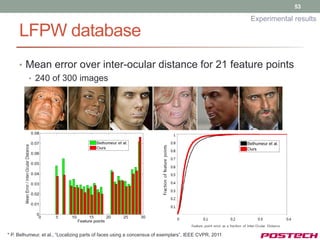
![44
Experimental results
Test database
• ARDB [8]
• Occlusion (Sunglasses, and scarf)
• CMU Multi-PIE
• Various pose, expression, illumination
• For artificial occlusion
• LFPW(Labeled Face Parts in the Wild) [9]
• Various pose, expression, illumination, and partial occlusion.
• 29 feature points
• To compare our algorithm with other state-of-the art one
AR DB LFPW
[8] A.M. Martinez and R. Benavente. The AR Face Database. CVC Technical Report #24, June 1998
[9] P. Belhumeur, et al., “Localizing parts of faces using a concensus of exemplars”, IEEE CVPR, 2011](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-44-320.jpg)
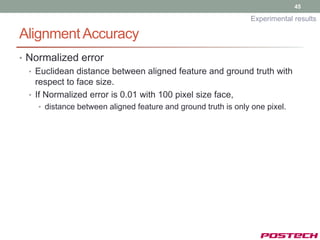
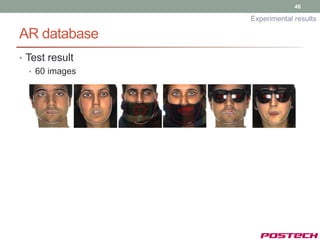

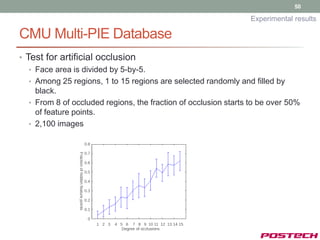




![58
Future work
• Problem in facial feature tracking
• Drift problem
Iterative Update
Appearance
Error
arg minE AAM I n , A,p, α
[Input] [Output]
p,α
-
Update
parameters
p p p
α α α
x x0 pi si
Condition](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-58-320.jpg)

![60
Future work
[Input In]
Iterative Update
[Point constraint]
Feature point Appearance
selection Error
arg minE AAM I n , A,p, α
p,α
-
Local feature [Output]
detector Point Error Update
parameters
x1 y1 p p p
E pts x2 y2 α α α
x x0 pi si
…
xn yn
Condition](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-60-320.jpg)

![62
Future work
Validation
[Input In] Matrix
Iterative Update
[Point constraint]
Feature point Appearance
selection Error
arg minE AAM I n , A,p, α Occlusion
p,α
Decision
x1-pos.
- x2-neg.
…
xn-pos.
Local feature
detector Point Error Update
parameters
x1 y1 p p p [Output]
E pts x2 y2 α α α
x x0 pi si
…
xn yn
Condition](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-62-320.jpg)
![63
Future work
Validation
[Input In+1] Matrix
Iterative Update
[Point constraint]
Feature point Robust
selection App. Error
arg minE AAM I n , A,p, α Occlusion
p,α Decision
* - x1-pos.
x2-neg.
…
xn-pos.
Local feature
detector Point Error Update
parameters
x1 y1 p p p [Output]
E pts x2 y2 α α α
x x0 pi si
…
xn yn
Condition](https://image.slidesharecdn.com/jongjushinphdproposal-130116190108-phpapp02/85/All-pose-face-alignment-robust-to-occlusion-63-320.jpg)


The document proposes a method for pose and occlusion robust face alignment using multiple shape models and partial inference. It introduces shape representation using point distribution models and multiple shape models to handle various poses and expressions. The method detects local features hierarchically using modified census transform and Adaboost. It then hypothesizes transformation and shape parameters using partial inference to estimate visible and invisible features. Experimental results on public databases show the method achieves accurate alignment under poses, expressions, and occlusions.











![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)


































