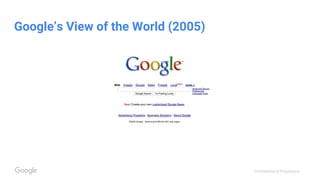
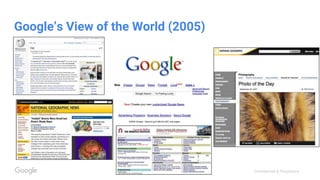
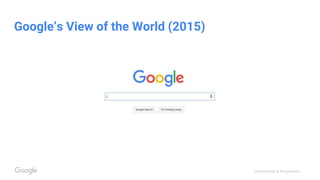
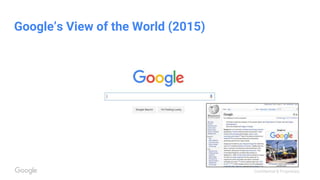
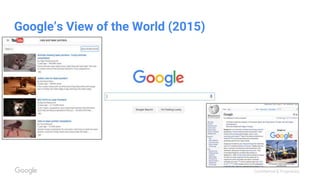
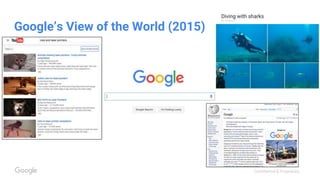
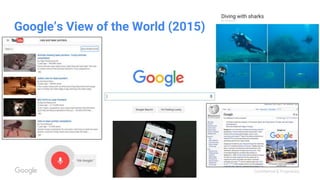
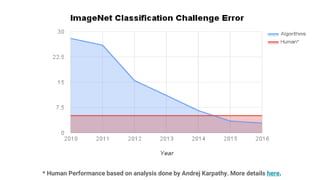
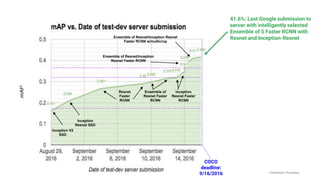
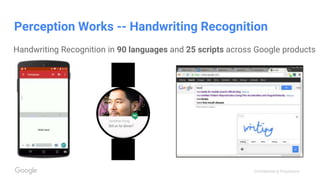
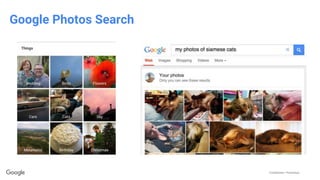
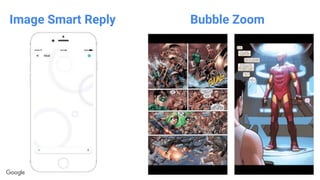
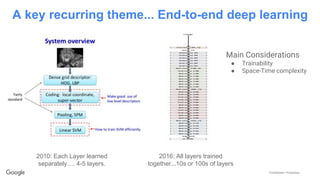
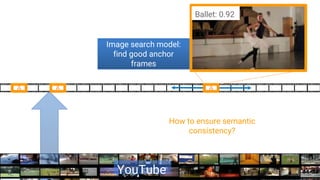
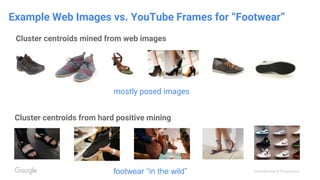
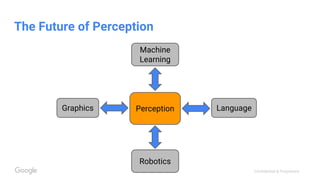
This document discusses the rapid evolution of machine perception capabilities from 2005 to the present. It outlines Google's progress in developing perception systems for tasks like image recognition, handwriting recognition, geo tagging, image captioning, and video annotation. This progress is attributed to novel deep learning architectures, techniques for augmenting training data, and shared machine learning infrastructure. The document envisions future directions like cross-modal learning between vision, language, audio and other domains, as well as moving beyond passive perception to interactive systems like robotics.