Downloaded 13 times






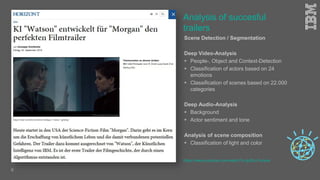

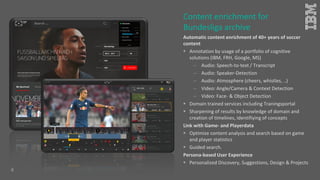



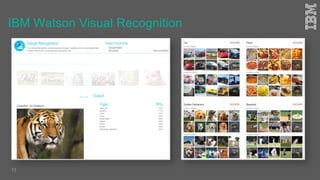
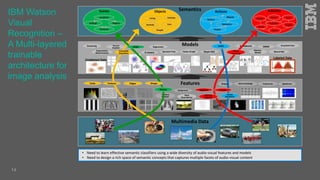
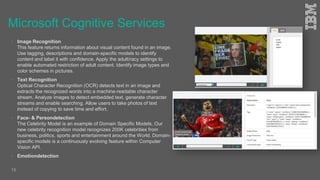


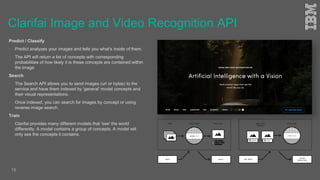
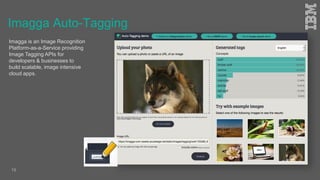



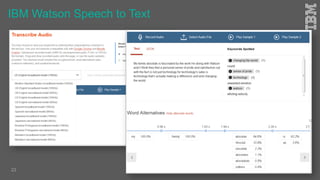


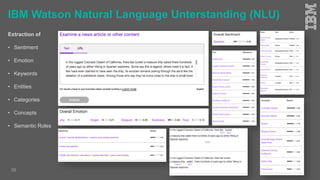




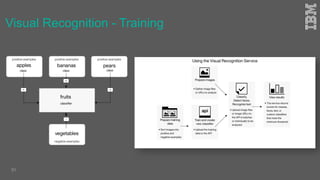
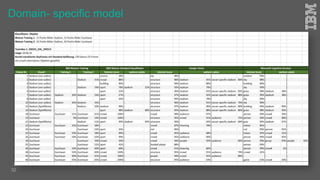
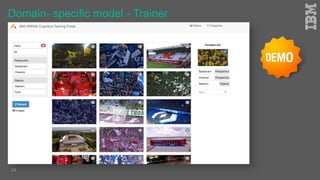
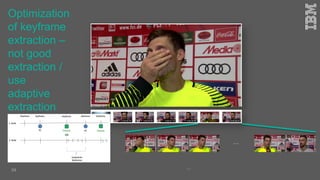

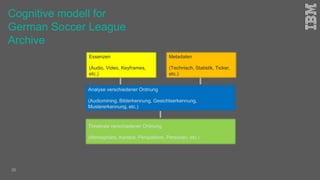




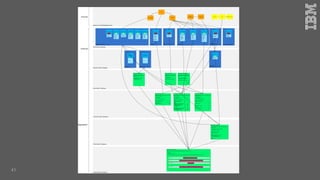




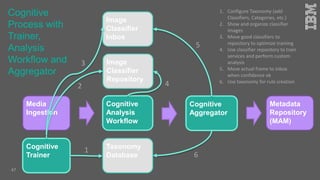



Jakob Rosinski presented on automatic multi-modal metadata annotation based on trained cognitive solutions. He discussed using various cognitive services like IBM Watson, Microsoft Cognitive Services, Google Vision, and OpenCV to analyze video and audio content. This includes scene detection, people and object detection, emotion detection, speech to text, and more. The extracted metadata can then be used to enrich content and power advanced search and discovery tools.



































































