Downloaded 84 times




![E. Della Valle – http://emanueledellavalle.org - @manudellavalle
HL7 v2 enables bi-later integrations
Complementary application
[…]
Organizational
boundaries
application
[…]
adapter
!
5](https://image.slidesharecdn.com/ist16-02ahl7from-v2-syntax-to-v3-semantics-160320201257/85/Ist16-02-HL7-from-v2-syntax-to-v3-semantics-5-320.jpg)









![E. Della Valle – http://emanueledellavalle.org - @manudellavalle
HL7 version 3 intent
18
[…]
[…]
[…]
[…]
[…]
[…]
[…]](https://image.slidesharecdn.com/ist16-02ahl7from-v2-syntax-to-v3-semantics-160320201257/85/Ist16-02-HL7-from-v2-syntax-to-v3-semantics-18-320.jpg)








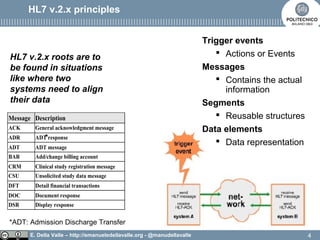
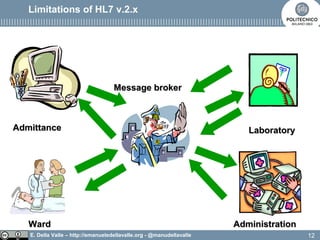
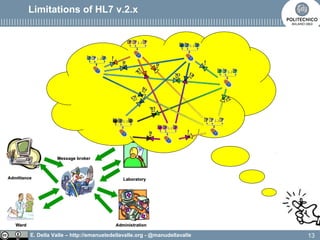
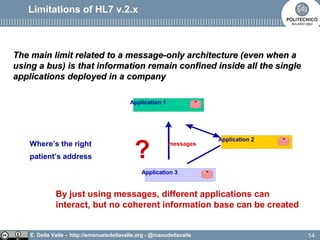
The document discusses Health Level Seven (HL7), an organization established in 1987 that develops standards for clinical and administrative data in healthcare. It outlines the evolution from HL7 version 2, which has limitations like implicit data models and difficulty in linking events to business processes, to HL7 version 3, which adopts a model-based methodology with a focus on shared models and robust communication techniques. The text highlights that HL7 version 3 improves on previous versions by providing a common reference information model and ensuring technology neutrality.




































































