Download as PDF, PPTX










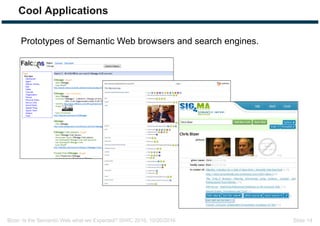


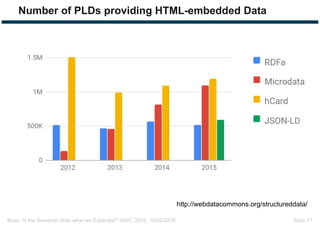
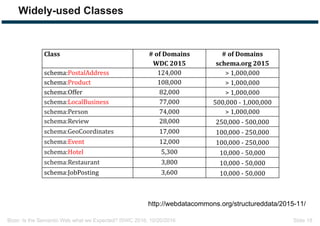
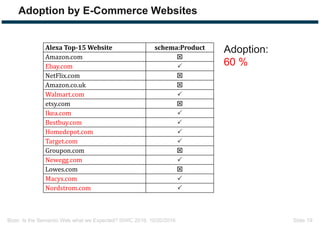



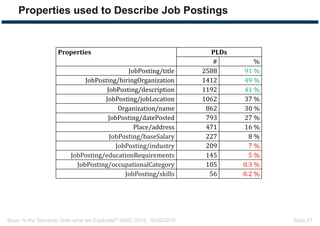
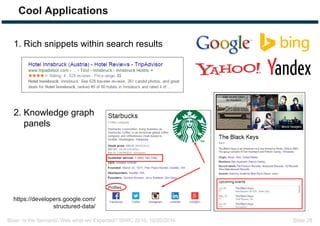
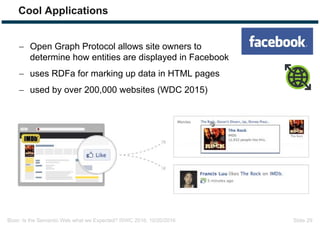
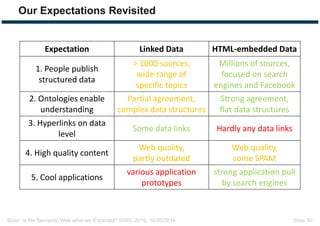
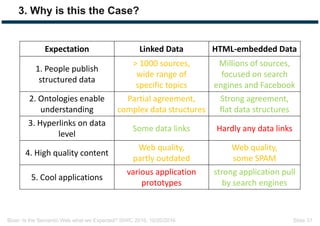
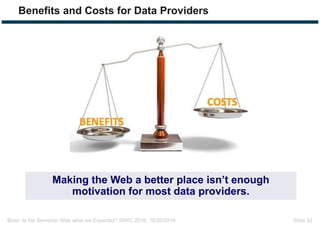









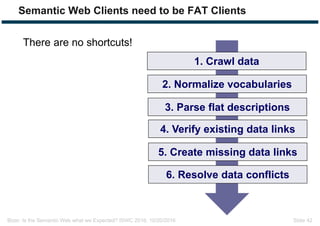
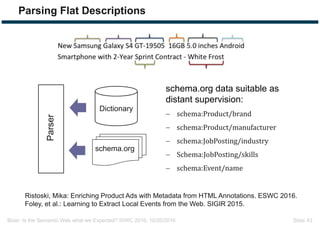
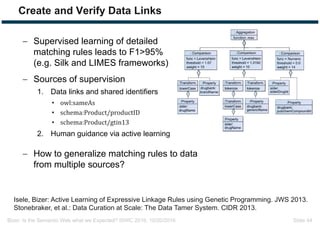

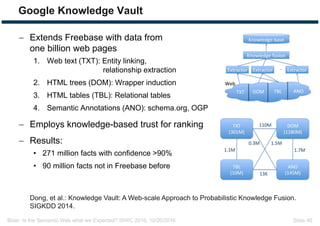

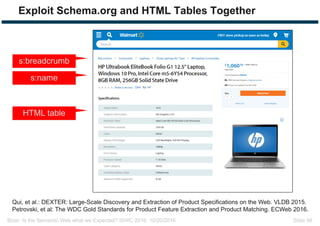





The document discusses expectations and realities of the semantic web, highlighting that while there was hope for structured data publishing and comprehensive ontologies, the actual landscape shows limited data sharing and varying quality. It compares linked data and HTML-embedded data, revealing challenges such as low identifier usage and the complexity of product categorization. Ultimately, it notes a significant gap between initial aspirations and current implementations, suggesting the need for improved incentives for data providers.


























































