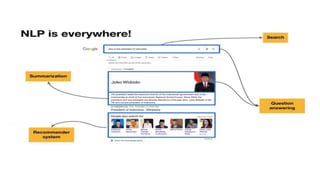
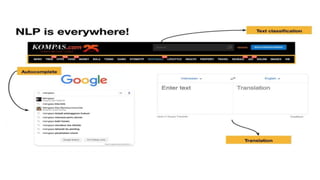
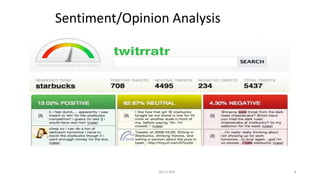
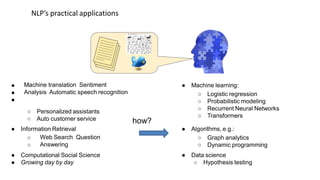
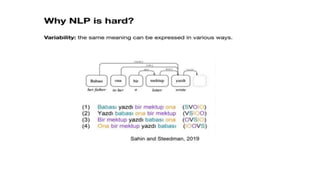
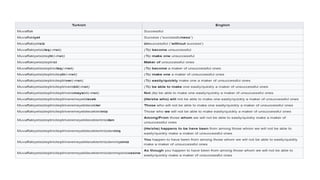
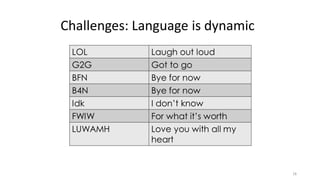
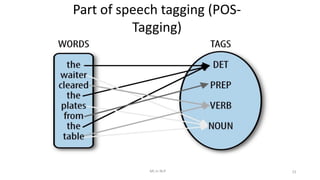
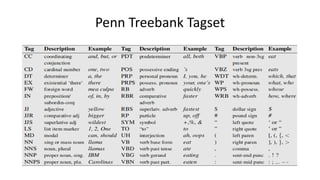
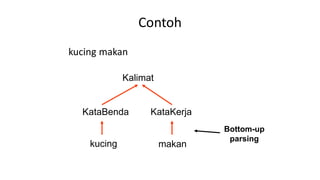
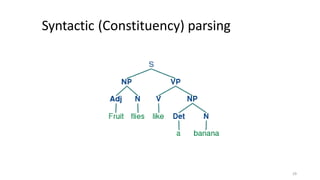
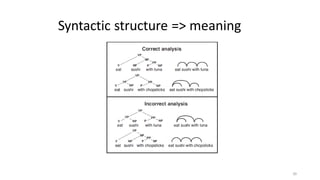
Dokumen tersebut membahas tentang Natural Language Processing (NLP) yang merupakan bidang ilmu komputer yang berfokus pada interaksi antara komputer dengan bahasa alami manusia. Dokumen tersebut menjelaskan tujuan dari NLP untuk memahami bahasa alami, komponen-komponen NLP seperti sintaksis, semantik, dan tag part of speech, serta tantangan yang dihadapi dalam NLP seperti ambiguitas bahasa.