Practical Deep Learning for Natural Language Processing
Seminar dua hari ini membahas pengenalan singkat tentang pemrosesan bahasa alami dan pembelajaran mendalam serta persiapan data dan model teks untuk aplikasi klasifikasi teks dan penerjemahan mesin."
Practical Deep Learning for Natural Language Processing
1.
Practical Deep LearningFor Natural
Language Processing with Python
14-15 August 2018
Data Science Research Group - Research Center for Informatics
Indonesian Institute of Sciences
2.
Outlines
● Introduction
○ NaturalLanguage Processing
○ Deep Learning
● System Preparation
● Data Preparation
● Text Model
● Language Models
● Applications
○ Text Classifications
○ Machine Translation
Keltian Data Science - P2Informatika, LIPI
3.
Agenda
Day-1, Session-1 WS:Introduction (Natural Language Processing, Deep Learning)
AA: System Installation / Configuration (Python + NLTK + Keras)
Day-1, Session-2 EN: Data Preparation
Day-1, Session-3 NY: Text Model Application (Text Classifications : MLP)
Day-2, Session-1 DM: Text Model
RW: Text Model Application (Text Classifications : CNN)
Day-2, Session-2 AR: Language Model
Day-2, Session-3 DR: Language Model Application (Text Generator, Machine Translation)
AR: Python Module and Web API development
Keltian Data Science - P2Informatika, LIPI
4.
Requirements
● A littleknowledge of
○ Python for programming
○ NumPY for array manipulation
○ Scikit-learn for Machine Learning
○ Keras for Deep Learning
● Might a little bit of (but you will get more)
○ Predictive modelling
○ Natural language processing
○ NLTK
Keltian Data Science - P2Informatika, LIPI
5.
Goals
● Able touse simple deep learning method for natural language processing
● Able to prepare text for processing from raw data
● Able to represent text for processing
● Able to present value information from processed text
Keltian Data Science - P2Informatika, LIPI
Natural Language Processing
●From linguistic with the help of computer (and programmer) -> Computational Linguistic
● Computer Science + Artificial Intelligence + Lingusitic
● Rule-Based -> Statistical -> Machine Learning -> Deep Learning
● Natural language
○ Signs
○ Menu
○ Text Messages
○ Email
○ News articles
Keltian Data Science - P2Informatika, LIPI
9.
What is NaturalLanguage Processing or Computational Linguistics?
● To make computers to process or
“understand” natural language (to
perform useful tasks)
○ Performing tasks
○ Question - Answers (Siri, Google
Assistant, Cortana, …)
Keltian Data Science - P2Informatika, LIPI
10.
Natural Language ProcessingLevels
Phonetic/Phonological Analysis OCR / Tokenization
Speech Text
Morphological Analysis
Syntactic Analysis
Semantic Interpretation
Discourse Processing
Keltian Data Science - P2Informatika, LIPI
11.
Natural Language Processingin Industry
● Spell checker
● Sentiment Analysis
● Text generator
● Machine Translation
● Question - Answering
Keltian Data Science - P2Informatika, LIPI
12.
Natural Language Processingis Hard
● It is hard from the standpoint of the child, who must spend many years acquiring a language ... it is hard for the
adult language learner, it is hard for the scientist who attempts to model the relevant phenomena, and it is hard
for the engineer who attempts to build systems that deal with natural language input or output. These tasks are
so hard that Turing could rightly make fluent conversation in natural language the centerpiece of his test for
intelligence.
-- Page 248, Mathematical Linguistics, 2010.
● Human language is highly ambiguous ... It is also ever changing and evolving. People are great at producing
language and understanding language, and are capable of expressing, perceiving, and interpreting very
elaborate and nuanced meanings. At the same time, while we humans are great users of language, we are also
very poor at formally understanding and describing the rules that govern language.
-- Page 1, Neural Network Methods in Natural Language Processing, 2017
Keltian Data Science - P2Informatika, LIPI
13.
Why Research onNLP and Computational Linguistics?
● Development of internet with million documents
● Human-friendly technology
● Development of CL technology is related with language used in certain country/region opportunity
for local industry to compete with global
Keltian Data Science - P2Informatika, LIPI
14.
Indonesia is Huge,Many, Diverse
Keltian Data Science - P2Informatika, LIPI
Problems on CL(research opportunity)
● OOV (Out of vocabulary)
○ New words are not available in dictionary
● Ambiguity
○ Words with more than 1 sense
● For bahasa Indonesia: low resource language/small number of available basic tools of CL
● Relation among basic tools
○ Low accuracy of one basic tool will affect the next basic tool
○ Large execution time
Keltian Data Science - P2Informatika, LIPI
17.
Text and DataMining
● Information Extraction
● Text Summarization
Keltian Data Science - P2Informatika, LIPI
18.
Predictive Model forText
Keltian Data Science - P2Informatika, LIPI
Classical document retrieval process
19.
Basic Tools inComputational Linguistics
Keltian Data Science - P2Informatika, LIPI
Deep Learning
● Deeplearning is large neural networks with many
intermediate/hidden layers
● Simulating how human brain works
Keltian Data Science - P2Informatika, LIPI
Why Deep Learning
●Learning by finding (good) intermediate features are (usually) better than hand crafted features
● Flexible with new type of data
● Could be used for unsupervised learning
● It is effective (in supervised learning) with availability of big data and faster CPU (/GPU)
○ More data
○ Bigger models
○ More computation
○ >> better results
Keltian Data Science - P2Informatika, LIPI
25.
Deep Learning Architectures
●Hierarchical Feature Learning
○ Feedforward deep network or Multilayer perceptorn
● Convolutional Neural Network
● Recurrent Neural Network
○ Long Short Term Memory
● Many more ...
Keltian Data Science - P2Informatika, LIPI
26.
Deep Learning -Multi-Layer Perceptorn
● Consists of many layers of perceptrons
● One input layers, many hidden layers, one output
layer
● Also called ‘feedforward’
● Nodes are fully interconnected
Keltian Data Science - P2Informatika, LIPI
27.
Deep Learning -Convolutional Neural Network
● Feedforward neural network with localized
interconnection
● For important ‘local’ information; image and time
series data
Keltian Data Science - P2Informatika, LIPI
28.
Deep Learning -Recurrent Neural Network
● Neural network where perceptorn’s outputs is also
input to itself
Keltian Data Science - P2Informatika, LIPI
29.
Deep Learning forNatural Language Processing
● Better models’ performance with more data but less linguistic expertise
○ Replacement of existing models with new NLP models
○ Feature learning
○ Continued improvement
○ End-to-end models
Keltian Data Science - P2Informatika, LIPI
30.
Deep Learning +Natural Language Processing
● Combine ideas and goals of NLP with using representation learning and deep learning methods
to solve them
● Several big improvements in recent years in NLP
○ Linguistic levels : (speech), words, syntax, semantics
○ Intermediate tasks/tools : parts-of-speech, entities, parsing
○ Full applications : sentiment analysis, question answering, dialogue agents, machine translation
Keltian Data Science - P2Informatika, LIPI
Python
● Interpreted high-levelprogramming language for
general-purpose programming
● Dynamic type system and automatic memory
management
Keltian Data Science - P2Informatika, LIPI
Tensorflow
● Software libraryfor dataflow programming across a range
of tasks
● Usually used for machine learning applications
● Developed and used in Google
Keltian Data Science - P2Informatika, LIPI
35.
NLTK
● Natural LanguageToolkit
● Collections of libraries and programs for
symbolic and statistical natural language
processing (NLP) for English
● Functions:
○ Classification
○ Tokenization
○ Stemming
○ Tagging
○ Parsing
○ Semantic reasoning functionalities
Keltian Data Science - P2Informatika, LIPI
36.
Keras
● Neural networklibrary for Python
● Can be run on top of Tensorflow, Theano, etc.
● Designed for Deep Learning
● Keras model life cycle
○ Define network
○ Compile network
○ Fit network
○ Evaluate network
○ Make predictions
Keltian Data Science - P2Informatika, LIPI
Topics
● How toClean Text Manually and with NLTK
● How to Prepare Text Data with scikit-learn
● How to Prepare Text Data with Keras
Keltian Data Science - P2Informatika, LIPI
45.
I. How toClean Text Manually and With NLTK
Teks mentah harus bersih agar sesuai dengan model machine learning dan deep learning :
● Memisahkan (splitting) teks menjadi kata-kata (words).
● Menangani tanda baca dan huruf besar/kecil.
Langkah pertama adalah memilih set data.
Untuk latihan ini akan menggunakan teks dari buku "Metamorphosis" oleh Franz Kafka
http://www.gutenberg.org/cache/epub/5200/pg5200.txt
1. Unduh dan simpan file pada direktori kerja yang aktif dengan nama metamorphosis.txt
2. Buka file dan hapus informasi pada header and footer, simpan file sebagai metamorphosis_clean.txt
Keltian Data Science - P2Informatika, LIPI
46.
Text Cleaning IsTask Specific
Perhatikan teks dari metamorphosis_clean.txt
● Merupakan plain text, sehingga tidak perlu ada parsing markup
● Tidak ada kesalahan ketik atau kesalahan eja
● Ada tanda baca seperti koma, titik, tanda tanya, tanda penyingkat (apostrof) dan lainnya.
● Ada teks yang ditulis dengan tanda penghubung, seperti armour-like
● Ada banyak penggunaan tanda strip (-) untuk melanjutkan kalimat
● Ada penggunaan nama orang (contoh : Mr. Samsa)
● Ada penanda bagian bab (contoh : II dan III)
Keltian Data Science - P2Informatika, LIPI
47.
1. Manual Tokenization
●Load Data : Load seluruh teks dari file metamorphosis_clean.txt ke dalam memory
# load text
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt')
text = file.read()
file.close()
● Split by whitespace : mengubah teks mentah menjadi daftar kata berdasarkan spasi (whitespace), baris baru
dan tab sehingga menjadi daftar kata-kata.
❖ 100 kata pertama dari dokumen akan dipisahkan..
# load text
...
# split into words by white space
words = text. split()
print(words[:100])
Keltian Data Science - P2Informatika, LIPI
48.
a. Manual Tokenization- Split by whitespace
100 kata pertama dari dokumen akan dipisahkan.
['One', 'morning,', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams,', 'he', 'found', 'himself',
'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible','vermin.', 'He', 'lay', 'on', 'his', 'armour-like',
'back,', 'and', 'if', 'he', 'lifted', 'his', 'head', 'a', 'little', 'he', 'could', 'see', 'his', 'brown',
'belly,', 'slightly', 'domed', 'and', 'divided', 'by', 'arches', 'into', 'stiff','sections.', 'The', 'bedding',
'was', 'hardly', 'able', 'to', 'cover', 'it', 'and', 'seemed', 'ready', 'to', 'slide', 'off', 'any','moment.',
'His', 'many', 'legs,', 'pitifully', 'thin', 'compared', 'with', 'the', 'size', 'of', 'the', 'rest', 'of',
'him,', 'waved', 'about', 'helplessly', 'as', 'he','looked.', '"What's', 'happened', 'to', 'me?"', 'he',
'thought.', 'It', "wasn't", 'a', 'dream.', 'His', 'room,', 'a', 'proper', 'human']
● Tanda penghubung masih disimpan (armour-like).
● Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat masih disimpan ( vermin., sections.,
moment., looked., thought., and me?).
● Tanda penyingkat ditambahkan dengan tanda slash (garis miring) (What’s)
Keltian Data Science - P2Informatika, LIPI
49.
b. Manual Tokenization- Split by words only
● Select Words (another approach)
Menggunakan model regex (re) untuk memisahkan dokumen menjadi kata-kata berdasarkan non-alphanumeric (termasuk
tanda baca dan spasi), sehingga yang tersisa adalah string dengan karakter alfanumerik (a-z, A-Z, 0-9)
import re
# load text
...
# split into on words only
words = re.split(r'W+', text)
print(words[:100])
➔ Kata armour-like sekarang telah menjadi dua kata : armour dan like (is fine).
➔ Kata What's sekarang juga menjadi dua kata : What dan s (not great).
➔ Kata wasn't sekarang juga menjadi dua kata : wasn dan t (not great).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat sudah tidak tersimpan.
Keltian Data Science - P2Informatika, LIPI
50.
c. Manual Tokenization- Split by Whitespace and Remove Punctuation (1)
● Split by Whitespace and Remove Punctuation
List of words :
○ tanpa menggunakan tanda baca koma, tanda kutip dan lainnya
print(string.punctuation) → !"#$%&'()*+,-./:;<=>?@[]^_`{|}~
○ mempertahankan konstraksi kata-kata seperti (e.g. armour-like)
Menggunakan reguler expression (re) untuk memilih tanda baca dan fungsi sub() untuk menggantinya dengan
nothing.
# prepare regex for char filtering
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# remove punctuation from each word
stripped = [re_punc.sub('', w) for w in words]
Keltian Data Science - P2Informatika, LIPI
51.
c. Manual Tokenization- Split by Whitespace and Remove Punctuation (2)
● load the text file,
● split it into words by white space,
● translate each word to remove the punctuation.
['One', 'morning', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams',
'he', 'found', 'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible',
'vermin', 'He', 'lay', 'on', 'his', ' armourlike',
...,
'Whats', 'happened', 'to', 'me', 'he', 'thought', 'It', ' wasnt', 'a', 'dream', 'His',
'room', 'a', 'proper', 'human']
➔ Kata What's dan wasn't menjadi Whats dan wasnt (seperti yang diinginkan).
➔ Kata armour-like menjadi seperti armourlike (not great).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat sudah tidak tersimpan
Keltian Data Science - P2Informatika, LIPI
52.
c. Manual Tokenization- Split by Whitespace and Remove Punctuation (3)
Filter out all non-printable characters by selecting the inverse of the string.printable constant.
['One', 'morning,', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams,', 'he',
'found', 'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible', ' vermin.',
'He', 'lay', 'on', 'his', ' armour-like ', 'back,', 'and', 'if', 'he', 'lifted',
...,
'helplessly', 'as', 'he', ' looked.', '"What's', 'happened', 'to', ' me?"', 'he', ' thought.',
'It', "wasn't", 'a', 'dream.', 'His', 'room,', 'a', 'proper', 'human']
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# remove punctuation from each word
result = [re_print.sub('', w) for w in words]
print(result[:100])
➔ Tanda baca masih disimpan (wasn't dan armour-like).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat masih disimpan ( vermin., dream., looked., thought., and me?).
➔ Kutipan di tengah kalimat ditambahkan dengan tanda slash (garis miring) (What’s)
Hasil serupa dengan menggunakan split()
Keltian Data Science - P2Informatika, LIPI
53.
d. Manual Tokenization- Normalizing Case
Konversi seluruh kata menjadi huruf kecil (lowercase) dengan menggunakan fungsi lower() pada setiap
kata.
# load text
# split into words by white space
# convert to lower case
words = [word. lower() for word in words]
print(words[:100])
['one', 'morning,', 'when', 'gregor', 'samsa',
'woke', 'from', 'troubled', 'dreams,', 'he',
'found', 'himself', 'transformed', 'in', 'his',
'bed', 'into', 'a', 'horrible', 'vermin.',
'he', 'lay', 'on', 'his', 'armour-like',
'back,', 'and', 'if', 'he', 'lifted', 'his',
'head', 'a', 'little', 'he', 'could', 'see',
'his', 'brown', 'belly,', 'slightly', 'domed',
'and', 'divided', 'by', 'arches', 'into',
'stiff', 'sections.', 'the', 'bedding', 'was',
'hardly', 'able', 'to', 'cover', 'it', 'and',
'seemed', 'ready', 'to', 'slide', 'off', 'any',
'moment.', 'his', 'many', 'legs,', 'pitifully',
'thin', 'compared', 'with', 'the', 'size',
'of', 'the', 'rest', 'of', 'him,', 'waved',
'about', 'helplessly', 'as', 'he', 'looked.',
'"what's', 'happened', 'to', 'me?"', 'he',
'thought.', 'it', "wasn't", 'a', 'dream.',
'his', 'room,', 'a', 'proper', 'human']
Cleaning text is really hard, problem specific, and full
of tradeoffs.
Simple is better. Simpler text data, simpler models,
smaller vocabularies.
You can always make things more
complex later to see if it results in better model skill.
Keltian Data Science - P2Informatika, LIPI
54.
2. Tokenization andCleaning with NLTK
Install NLTK > python -m pip -U nltk
install the data used with the library
Script :
import nltk
nltk.download()
From the command line:
> python -m nltk.downloader all
Keltian Data Science - P2Informatika, LIPI
55.
a. Cleaning withNLTK - Split into Sentences
● Menguraikan setiap teks menjadi kalimat-kalimat
● NLTK provides the sent_tokenize() function to split text into sentences
from nltk import sent_tokenize
# load data
...
# split into sentences
sentences = sent_tokenize(text)
print(sentences[0])
➔ Teks dokumen dibagi menjadi kalimat-kalimat yang masih mempertahankan baris baru dari
dokumen asli.
One morning, when Gregor Samsa woke from troubled dreams, he found
himself transformed in his bed into a horrible vermin.
Keltian Data Science - P2Informatika, LIPI
56.
b. Cleaning withNLTK - Split into Words
● Menguraikan setiap teks menjadi kata-kata
● NLTK menyediakan fungsi word_tokenize() untuk
membagi string menjadi token-token (kata-kata nominal)
berdasarkan tanda baca dan spasi
from nltk.tokenize import word_tokenize
# load data
...
# split into words
tokens = word_tokenize(text)
print(tokens[:100])
➔ Koma, titik dan baris kosong akan dianggap sebagai token terpisah.
➔ Ada kontraksi yang masih disimpan (armour-like).
➔ Ada kontraksi yang dipisah (What's menjadi What dan 's).
['One', 'morning', ',', 'when', 'Gregor',
'Samsa', 'woke', 'from', 'troubled', 'dreams',
',', 'he', 'found', 'himself', 'transformed',
'in', 'his', 'bed', 'into', 'a', 'horrible',
'vermin', '.', 'He', 'lay', 'on', 'his',
'armour-like', 'back', ',', 'and', 'if', 'he',
'lifted', 'his', 'head', 'a', 'little', 'he',
'could', 'see', 'his', 'brown', 'belly', ',',
'slightly', 'domed', 'and', 'divided', 'by',
'arches', 'into', 'stiff', 'sections', '.',
'The', 'bedding', 'was', 'hardly', 'able',
'to', 'cover', 'it', 'and', 'seemed', 'ready',
'to', 'slide', 'off', 'any', 'moment', '.',
'His', 'many', 'legs', ',', 'pitifully',
'thin', 'compared', 'with', 'the', 'size',
'of', 'the', 'rest', 'of', 'him', ',',
'waved', 'about', 'helplessly', 'as', 'he',
'looked', '.', '``', 'What', "'s", 'happened',
'to']
Keltian Data Science - P2Informatika, LIPI
57.
c. Cleaning withNLTK - Filter Out Punctuation
● Filter semua token yang tidak diinginkan
(semua tanda baca yang berdiri sendiri),
● Lakukan iterasi berulang pada semua token dan
hanya menyimpan token yang terdiri dari abjad
saja, menggunakan fungsi isalpha()
['One', 'morning', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams', 'he', 'found',
'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible', 'vermin', 'He', 'lay',
'on', 'his', 'back', 'and', 'if', 'he', 'lifted', 'his', 'head', 'a', 'little', 'he', 'could',
'see', 'his', 'brown', 'belly', 'slightly', 'domed', 'and', 'divided', 'by', 'arches', 'into',
'stiff', 'sections', 'The', 'bedding', 'was', 'hardly', 'able', 'to', 'cover', 'it', 'and',
'seemed', 'ready', 'to', 'slide', 'off', 'any', 'moment', 'His', 'many', 'legs', 'pitifully',
'thin', 'compared', 'with', 'the', 'size', 'of', 'the', 'rest', 'of', 'him', 'waved', 'about',
'helplessly', 'as', 'he', 'looked', 'What', 'happened', 'to', 'me', 'he', 'thought', 'It', 'was',
'a', 'dream', 'His', 'room', 'a', 'proper', 'human', 'room']
from nltk.tokenize import word_tokenize
# load data
# split into sentences
tokens = word_tokenize(text)
# remove all tokens that are not alphabetic
words = [word for word in tokens if word.isalpha()]
print(words[:100])
Keltian Data Science - P2Informatika, LIPI
58.
d. Cleaning withNLTK - Filter Out Stop Words (1)
● Kata-kata umum seperti : the, a, an dan is adalah 'stop words'.
● Stop words : kata-kata yang tidak berkontribusi pada makna yang lebih dalam dari frasa.
● NLTK menyediakan daftar 'stop words' untuk berbagai bahasa yang telah disetujui secara umum .
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd",
'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers',
'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which',
'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been',
'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if',
'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into',
'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off',
'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all',
'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same',
'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd',
'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn',
"doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't",
'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren',
"weren't", 'won', "won't", 'wouldn', "wouldn't"] Keltian Data Science - P2Informatika, LIPI
59.
d. Cleaning withNLTK - Filter Out Stop Words (2)
Tahap-tahap untuk persiapan teks :
● Load raw text
● Split/pisahkan menjadi token-token
● Konversi ke huruf kecil
● Hapus tanda baca dari setiap token
● Hapus yang bukan termasuk abjad
● filter token yang tersisa yang bukan stop
words
import string
import re
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# load data
...
# split into words
tokens = word_tokenize(text)
# convert to lower case
tokens = [w.lower() for w in tokens]
# prepare regex for char filtering
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# remove punctuation from each word
stripped = [re_punc.sub('', w) for w in tokens]
# remove remaining tokens that are not alphabetic
words = [word for word in stripped if word.isalpha()]
# filter out stop words
stop_words = set(stopwords.words('english'))
words = [w for w in words if not w in stop_words]
print(words[:100])
Keltian Data Science - P2Informatika, LIPI
60.
d. Cleaning withNLTK - Steam Words (1)
● Stemming merujuk pada proses untuk mendapatkan akar kata. Misalnya fishing, fished, fisher,
semua akan direduksi hingga menjadi fish.
● Beberapa aplikasi seperti klasifikasi dokumen dapat memanfaatkan stemming untuk
mengurangi kosakata dan lebih fokus pada arti atau sentimen dokumen daripada makna yang
lebih dalam
● Algoritma stemming yang populer dan telah lama digunakan adalah Porter Stemming. Jika
mengurangi kata-kata hingga ke akarnya menjadi sesuatu yang dibutuhkan, NLTK menyediakan
metode ini melalui class PorterStemmer().
Keltian Data Science - P2Informatika, LIPI
61.
d. Cleaning withNLTK - Steam Words (2)
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
# load data
...
# split into words
tokens = word_tokenize(text)
# stemming of words
porter = PorterStemmer()
stemmed = [ porter.stem(word) for word in tokens]
print(stemmed[:100])
['one', 'morn', ',', 'when', 'gregor', 'samsa', 'woke', 'from', 'troubl', 'dream', ',', 'he',
'found', 'himself', 'transform', 'in', 'hi', 'bed', 'into', 'a', 'horribl', 'vermin', '.', 'He',
'lay', 'on', 'hi', 'armour-lik', 'back', ',', 'and', 'if', 'he', 'lift', 'hi', 'head', 'a',
'littl', 'he', 'could', 'see', 'hi', 'brown', 'belli', ',', 'slightli', 'dome', 'and', 'divid',
'by', 'arch', 'into', 'stiff', 'section', '.', 'the', 'bed', 'wa', 'hardli', 'abl', 'to',
'cover', 'it', 'and', 'seem', 'readi', 'to', 'slide', 'off', 'ani', 'moment', '.', 'hi', 'mani',
'leg', ',', 'piti', 'thin', 'compar', 'with', 'the', 'size', 'of', 'the', 'rest', 'of', 'him',
',', 'wave', 'about', 'helplessli', 'as', 'he', 'look', '.', '``', 'what', "'s", 'happen', 'to']
● Beberapa kata telah mendapatkan akar
katanya, seperti trouble menjadi troub,
morning menjadi morn, transformed menjadi
transform.
● implementasi stemming menghasilkan
token-token dengan huruf kecil.
Keltian Data Science - P2Informatika, LIPI
62.
Beberapa tambahan yangharus dipertimbangkan saat Text Cleaning
● Dokumen yang besar dan koleksi dokumen teks yang besar, yang tidak sesuai dengan
memori.
● Ekstraksi teks dari markup, seperti HTML, PDF atau format dokumen terstruktur lainnya.
● Transliterasi karakter dari bahasa lain ke bahasa Inggris.
● Decoding karakter unicode ke bentuk normal, seperti UTF8.
● Penanganan kata-kata khusus, frasa dan akronim.
● Penanganan untuk menghapus angka, seperti tanggal atau jumlah.
● Menemukan dan memperbaiki kesalahan umum dan salah eja.
63.
Bag of Words(1)
Teks harus di konversi menjadi angka untuk dapat digunakan dalam algoritma machine learning.
- Fokus pada kemunculan kata-kata dalam dokumen dan mengabaikan urutan kata-kata.
- Menetapkan setiap kata menjadi angka yang unik.
- Setiap dokumen dapat dikodekan sebagai vektor dengan panjang tetap dengan kosakata yang
dikenal.
- Nilai setiap posisi dalam vektor dapat diisi dengan frekuensi atau menghitung setiap kata dalam
dokumen yang telah di encode sebelumnya.
Keltian Data Science - P2Informatika, LIPI
64.
Bag of Words(2)
Langkah 1. Collect Data
dari buku "A Tale of Two Cities" karya Charles
Dickenns
It was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness
Keltian Data Science - P2Informatika, LIPI
Langkah 2. Design Vocabulary
Membuat daftar seluruh kata-kata untuk
model vocabulary (menjadi huruf kecil)
it
was
the
best
of
times
worst
age
wisdom
foolishness
65.
Bag of Words(3)
Langkah 3. Create Document Vectors
- Memberi nilai untuk setiap kata. Metode penilaian : 0 untuk absen dan 1 untuk yang ada.
- Menggunakan dokumen pada baris pertama, hasil penilaian dari kata-kata sebagai berikut :
it = 1
was = 1
the = 1
best = 1
of = 1
times = 1
worst = 0
age = 0
wisdom = 0
foolishness = 0
Keltian Data Science - P2Informatika, LIPI
- sebagai binary vektor akan tampak seperti :
it - was- the-best-of-times-worst-age-wisdom-foolishness
"it was the best of times" = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
”it was the age of foolishnes"= [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
66.
Bag of words(4)
1. Managing Vocabulary
Untuk mengatasi Corpus yang sangat besar (vektor dengan ribuan sampai jutaan posisi), ukuran
kamuskata/vocabulary perlu dikurangi.
Teknik text cleaning yang sederhana : ignoring case, ignoring punctuation, ignoring stop words, fixing
misspeled words, reducing words from their stem.
Pendekatan lain adalah membuat vocabulary dari kelompok kata-kata (n-gram) → urutan kata-kata
n-token.
● 2-gram (bigram) rangkaian dua kata ("please turn", " turn your", "your homework")
● 3-gram (trigram) rangkaian tiga kata ("please turn your", "turn your homework")
2-grams dari “it was the best of times”:
- it was - the best - of times
- was the - best of Keltian Data Science - P2Informatika, LIPI
67.
Bag of words(5)
2. Scoring Words
Metode sederhana :
● Counts : jumlah kata muncul dalam sebuah dokumen
● Frequencies : frekuensi kata yang muncul dalam dokumen dari semua kata-kata yang ada dalam
dokumen.
3. Limitation of BoW
● Vocabulary : memerlukan desain yang cermat, terutama untuk mengatur ukurannya
● Sparsity : representasi yang jarang akan menyulitkan model (komputasi dan informasi)
● Meaning : membuang urutan kata dan mengabaikan konteks
Keltian Data Science - P2Informatika, LIPI
68.
II. How toPrepare Text Data with scikit-learn
Scikit-learn library menawarkan tools yang mudah digunakan untuk melakukan tokenisasi dan ekstrasksi
fitur data teks.
Bagian ini akan membahas bagaimana menyiapkan data teks utuk pemodelan prediktif dalam python
dengan menggunakan scikit-learn.
Scikit-learn library menyediakan 3 skema berbeda yang bisa digunakan.
1. Word Counts with CountVectorizer
2. Word Frequencies with TfidfVectorizer
3. Hashing with HashingVectorizer
Keltian Data Science - P2Informatika, LIPI
69.
1. Scikit Learn- Word Counts with CountVectorizer
CountVectorizer adalah cara sederhana untuk me-nokenisasi kumpulan dokumen teks, membangun
kosakata dari kata-kata yang dikenal dan encode dokumen baru menggunakan kosakata tersebut.
● Buat sebuah instance dari class CountVectorizer
● panggil fungsi fit() untuk mempelajari kosakata dari satu atau lebih dokumen.
● panggil fungsi transform() pada satu atau lebih dokumen sesuai kebutuhan untuk encode
setiap dokumen sebagai sebuah vektor.
Vektor yang telah di-encode memiliki panjang seluruh kosakata dan frekuensi kemunculan setiap kata
dalam dokumen. Untuk vektor yangmemiliki banyak angka nol, disebut dengan sparse vektor (vektor yang
jarang).
Keltian Data Science - P2Informatika, LIPI
70.
2. Scikit Learn- Word Frequencies with TfidfVectorizer(1)
● Permasalahan dalam menghitung frekuensi kata adalah, beberapa kata yang muncul berkali-kali
dalam jumlah besar tapi tidak terlalu berarti dari vektor yang dikodekan (encode vektor).
● Alternatifnya : menghitung frekuensi kata (TF-IDF : Term Frequency - Inverse Document Frequency),
yang merupakan komponen dari skor yang dihasilkan dari setiap kata yang ditetapkan.
● TF-IDF menyajikan skor frekuensi kata terutama untuk kata-kata yang menarik, misalnya sering
muncul dalam satu dokumen tetapi tidak untuk semua dokumen.
Keltian Data Science - P2Informatika, LIPI
71.
2. Scikit Learn- Word Frequencies with TfidfVectorizer (2)
● Term Frequency (TF) : jumlah kata tertentu yang muncul dalam suatu dokumen
● Invers Document Frequency (IDF) : ketersediaan kata tertentu dalam seluruh dokumen. Semakin
sedikit jumlah dokumen yang mengandung kata tertentu, nilai IDF akan semakin besar.
IDF = ln((Total seluruh dokumen+1) / (Jumlah dokumen yang memuat kata tertentu+1)) + 1
ln((N+1)/(df+1)) + 1
● TfidfVectorizer akan me-nokenisasi dokumen, mempelajari kosakata dan pembobotan
idf(inverse document frequency), dan memungkinkan untuk encode dokumen baru.
● Alternatif lain, jika sudah memiliki learned CountVectorizer, maka dapat menggunakannya
dengan TfidTransformer untuk menghitung frekuensi dari idf dan memulai pengkodean dokumen.
Keltian Data Science - P2Informatika, LIPI
72.
2. Scikit Learn- Word Frequencies with TfidfVectorizer (3)
● text = ["The quick brown fox jumped over the lazy dog.", "The dog.", "The fox"]
● print(vectorizer.vocabulary_)
{'the': 7, 'quick': 6, 'brown': 0, 'fox': 2, 'jumped': 3, 'over': 5, 'lazy': 4, 'dog': 1}
● print(vectorizer.idf_)
[ 1.69314718 1.28768207 1.28768207 1.69314718 1.69314718 1.69314718
1.69314718 1. ]
untuk kata 'fox' pada dokumen pertama (0,2)
➔ tf = 1 (jumlah kata 'fox' yang muncul pada dokumen 1)
➔ df = 2 (jumlah kata 'fox' yang muncul di seluruh dokumen)
➔ N = 3 (total dokumen)
Keltian Data Science - P2Informatika, LIPI
idf = ln((N+1)/(df+1)) + 1
idf = ln(4/3) + 1
= 0.28768207 + 1
= 1.28768207
tfidf(0,2) = tf * idf
= 1 * 1.28768207
= 1.28768207
73.
3. Scikit Learn- Hashing with HashingVectorizer
Keterbatasan dari metode menghitung frekuensi adalah jika jumlah kosakata yang besar akan
memerlukan vektor yang besar untuk meng-encode dokumen → membutuhkan memori yang besar dan
memperlambat algoritma.
Cara yang tepat adalah menggunakan hash pada kata-kata dan mengkonversinya ke integer.
● Fungsi hash memetakan data ke set ukuran angka yang tetap.
● Representasi hash dari kata-kata yang diketahui dapat digunakan untuk kosakata.
● Kelemahan dari hash adalah fungsinya satu arah, sehingga tidak ada cara untuk mengubah kode kembali ke
kata.
● Class HashingVectorizer akan mengkonversi sekumpulan dokumen teks ke matriks token yang terjadi.
Dapat digunakan untuk hash kata-kata yang konsisten, kemudian melakukan tokenisasi dan encode dokumen
sesuai kebutuhan.
Keltian Data Science - P2Informatika, LIPI
74.
III. How toPrepare Text Data With Keras
Library Keras deep learning menyediakan beberapa tools dasar untuk mempersiapkan data teks
agar dapat digunakan sebagai input untuk model machine learning dan deep learning.
1. Split Words with text_to_word_sequence()
2. Encoding with one_hot()
3. Hash Encoding with hashing_trick()
4. Tokenizer API
Keltian Data Science - P2Informatika, LIPI
75.
1. Keras -Split words with text_to_word_sequence()
text_to_word_sequence(): memisahkan teks menjadi kata-kata (tokens)
3 hal otomatis yang dilakukan oleh fungsi ini, yaitu :
● split/memisahkan kata-kata dengan spasi
● menyaring tanda baca
● mengubah teks menjadi huruf kecil (lower=true)
text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI
76.
2. Keras -Encoding with one_hot()
one_hot():me-nokeninsasi dan meng-encode teks menjadi sebuah daftar indeks kata-kata berukuran n.
● Fungsi ini mengubah teks menjadi huruf kecil, menyaring tanda baca dan memisahkan kata berdasarkan
spasi.
● Hasilnya adalah nilai integer [1, n]. n adalah ukuran kosakata yang harus ditentukan, bisa berupa total
kata dalam dokumen atau lebih (jika bermaksud meng-encode dokumen tambahan yang mengandung
kata tambahan).
● Ukuran ini mendefinisikan ruang hashing dimana kata-kata di hash. Untuk meminimalkan tabrakan,
idealnya harus lebih besar dari kosakata dengan beberapa persentase (sekitar 25 %).
● Tidak ada jaminan keunikan (unicity non-guaranteed) dari setiap nilai integer yang dihasilkan
one_hot(text, n, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI
77.
3. Keras -hash Encoding with hashing_trick()
● Kata-kata yang di-hash akan ditentukan ke indeks integer yang sama dalam target hash space. Nilai
atau hitungan biner dapat digunakan untuk memberi nilai kata (scoring word), disebut dengan hash
trick atau fitur hashing.
● hashing_trick() digunakan untuk me-nokenisasi dan meng-encode dokumen seperti fungsi
one_hot(), dengan lebih banyak fleksibilitas dan memungkinkan untuk menentukan fungsi hash
yang default atau fungsi hash lain seperti fungsi md5.
● Tidak ada jaminan keunikan (unicity non-guaranteed) dari setiap nilai integer yang dihasilkan
Fungsi ini menghasilkan versi dokumen yang telah di encode ke dalam integer.
hashing_trick(text, n, hash_function=None, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~',
lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI
78.
4. Keras -Tokenizer API (1)
Keras menyediakan API yang lebih canggih untuk menyiapkan teks yang dapat disimpan dan digunakan
kembali untuk mempersiapkan beberapa dokumen teks (Tokenizer API).
● num_words : jumlah maksimum kata yang harus disimpan berdasarkan frekuensi kata.
● char_level : Jika True, maka setiap karakter akan diperlakukan sebagai token.
● oov_token : None atau string. Jika ada, akan ditambahkan ke word_index dan digunakan untuk menggantikan
kata-kata diluar kosakata.
Panjang dari vektor adalah total ukuran dari kosakata.
Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True,
split=' ', char_level=False, oov_token=None)
Keltian Data Science - P2Informatika, LIPI
79.
4. Keras -Tokenizer API (2)
Setelah di Fit, tokenizer menyediakan 4 atribut yang dapat digunakan untuk query mengenai apa yang
telah dokumen pelajari, yaitu :
○ word_counts : kamus kata dan jumlahnya
○ word_docs : kamus kata dan jumlah kata tersebut muncul di semua dokumen.
○ word_index : kamus kata dengan index (integer) unik untuk setiap kata.
○ document_count : total jumlah dokumen yang digunakan untuk tokenizer
Fungsi texts_to_matrix() dapat digunakan untuk membuat satu vektor per dokumen,
menyediakan skema standar teks encoding bag-of-words melalui mode-mode argumen dari fungsi, yaitu :
○ binary : apakah setiap kata ada dalam dokumen atau tidak (default)
○ count : jumlah setiap kata dalam dokumen
○ tfidf : skor untuk Text Frequency-Inverse DocumentFrequency (TF-IDF) untuk setiap kata dalam dokumen
○ freq : frekuensi setiap kata sebagai rasio kata dalam setiap dokumen.
Keltian Data Science - P2Informatika, LIPI
80.
Text Models -Bag Of Words
Keltian Data Science - P2Informatika, LIPI
81.
Bag of Words(BoW) Model
● Machine learning algorithm prefer well defined fixed-length inputs and outputs, can’t work with
raw text → text need to converted into numbers (specifically vector numbers)
● BoW model is a way of representing text data
Bag of Words (BoW) is
● A vocabulary of known words
● A measure of the presence of known words
Keltian Data Science - P2Informatika, LIPI
82.
Example of BoWModel
● Step 1 : Collect Data
From Project of Gutenberg : A Tale of Two Cities by Charles Dickens
● Design the Vocabulary
→ make a list of all of the words in our model vocabulary
it was the best of times,
it was the worst of times,
it was the age of wisdom,
it was the age of foolishness, It
was
the
best
of
times
worst
age
wisdom
foolishness
Keltian Data Science - P2Informatika, LIPI
83.
Example of BoWModel
● Create Document Vectors
→ score the words in each document
As a binary vectors :
it = 1
was = 1
the = 1
best = 1
of = 1
times = 1
worst = 0
age = 0
wisdom = 0
foolishness = 0
“it was the best of times” = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
“it was the worst of times” = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
“it was the age of wisdom” = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
“it was the age of foolishnes” = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
Keltian Data Science - P2Informatika, LIPI
84.
Managing Vocabulary
● Fora very large corpus → the length of vector might be thousands/millions of position → results
in a vector with a lots of zero scores (sparse vector/representation) → require more memory and
computational resources → the size of vocabulary need to be decreased
● Simple text cleaning technique : ignoring case, ignoring punctuation, ignoring stop words (a, of,
etc), fixing misspelled words, reducing words from their stem (play from playing)
● Other approach is to create a vocabulary of grouped words → n-gram : an n-token sequence of
words.
List of 2-grams or bi-grams of “it was the best of times”:
it was
was the
the best
best of
of times
Keltian Data Science - P2Informatika, LIPI
85.
Scoring Words
Simple scoringmethods : counts and frequencies
● Words Hashing : using a hash representation of known words in vocabulary
Words are hashed deterministically to the same integer index in the target hash space.
A binary score or count can then be used to score the word (hash trick or feature hashing).
● TF - IDF : rescale the frequency of words by how often they appear in all
documents
Term Frequency (TF) is a scoring of the frequency of the word in the current document.
Inverse Document Frequency (IDF) is a scoring of how rare the word is across documents.
Keltian Data Science - P2Informatika, LIPI
86.
Limitation of BoW
●Vocabulary : requires careful design, most specifically in order to manage the size
● Sparsity : Sparse representations are harder to model both for computational reasons and also for
information reasons
● Meaning : Discarding word order ignores the context, and in turn meaning of words in the
document
Keltian Data Science - P2Informatika, LIPI
87.
Text Clustering withMLP
Case Study
Nuryani
Keltian Data Science - P2Informatika, LIPI
Text Models -Word Embedding
Devi Munandar
Keltian Data Science - P2Informatika, LIPI
90.
Apa itu WordEmbeddings..??
● Word Embeddings adalah representasi yang dipelajari untuk teks di mana kata-kata yang memiliki
arti yang sama memiliki representasi yang sama. Contoh : Raja ↔ Ratu , Indonesia ↔ Jakarta ……,
…..
● Word embeddings sebenarnya adalah kelas teknik di mana setiap kata-kata direpresentasikan
sebagai vektor bernilai real dalam ruang vektor yang telah ditentukan. Setiap kata dipetakan ke
satu vektor dan nilai-nilai vektor dipelajari dengan cara yang menyerupai jaringan saraf, dan
karenanya teknik ini sering dikelompokkan ke dalam bidang Deep Learning
● Lapisan Embedding, digunakan dengan model jaringan saraf pada pemrosesan bahasa alami yang
spesifik, seperti pemodelan bahasa atau klasifikasi dokumen. Ukuran ruang vektor ditentukan
sebagai bagian dari model, seperti 50, 100, atau 300 dimensi. Vektor diinisialisasi dengan angka
acak kecil. Lapisan embedding digunakan pada ANN biasanya menggunakan algoritma
Backpropagation. Keltian Data Science - P2Informatika, LIPI
91.
Algoritma Word Embedding
●Word2Vec adalah metode statistik untuk merepresentasian kata yang melekat pada embedding dari
sebuah corpus teks. Pertama dikembangkan oleh Tomas Mikolov, et al.
● Terbagi menjadi 2 learning model yang digunakan untuk word embedding pada Word2Vec:
○ Continuous Bag-of-Words, atau CBOW model.
○ Continuous Skip-Gram Model.
Keltian Data Science - P2Informatika, LIPI
92.
Word Embedding
● Wordembedding → Word2vec (CBOW and SkipGram) model
● Continuous Bag-of-Word model (CBOW) predikis kata
berdasarkan kontek dengan membuat sebuah ‘window of
context’ dengan’proof-missing word’ atau prediksi target.
Keltian Data Science - P2Informatika, LIPI
93.
Word Embedding
● Wordembedding → Word2vec (CBOW and SkipGram) model
● Skip-gram adalah model bahasa probabilistik untuk
menemukan informasi dengan mencari kata terdekat dalam
urutan kata secara ‘logical relationship’ dengan ‘window size
‘K’ words’
Keltian Data Science - P2Informatika, LIPI
94.
Word Embedding
● Wordembedding → Word2vec (CBOW and SkipGram), Random, Glove model
● Model word embedding lainnya adalah GloVe. Model ini melakukan generates vektor kata dengan
mengevaluasi co-occurrences kata pada sebuah corpus (twitter text) dengan membuat matric X
co-occurrence. Elemen dari Xij merepresentasikan berapa kali kata i muncul dalam context kata j
--> w_i adalah ‘main word of vector’, w_j adalah ‘context word of vector’, b_i,b_j adalah scalar bias
untuk ‘main and context words’
Keltian Data Science - P2Informatika, LIPI
95.
Word Embedding
● Artificialneural network (ANN) → contoh arisitektur model
yang digunakan feedforward neural network sederhana
dengan satu hidden layer
Keltian Data Science - P2Informatika, LIPI
96.
Word Embeddings padaNLP
Aplikasi Python menggunakan
Gensim
Keltian Data Science - P2Informatika, LIPI
97.
Gensim sebagai PythonLibrary
● Gensim adalah Python library yang bersifat open source untuk digunakan di NLP, yang difokuskan
untuk pemodelan, disebut juga sebagai “topic modeling for humans”. Gensim dikembangkan oleh
seorang peneliti NLP Czech yaitu Radim Rehurek dengan perusahaanya RaRe Technologies. Gensim
lebih fokus pada pemodelan topik terutama implementasi Word2Vec WE untuk menemukan vector
baru dalam sebuah teks dan merupakan bagian dari perangkat NLP
● Word2Vec merupakan salah satu algoritma untuk pembelajaran word embedding dalam sebuah
corpus teks ada 2 algoritma utama yang di gunakan dalam pembelajran tersebut Continuous
Bag-of-Words (CBOW) and skip gram
Keltian Data Science - P2Informatika, LIPI
Load Google’s Word2VecEmbedding
● Untuk membuat vector WE dengan NLP lebih baik dengan pendekatan ‘generate’ sendiri, namun
timbul permasalahan untuk membuat WE membutuhkan waktu dan RAM yang cukup cepat dan
storage yang besar.
● Google menyediakan pre-trained WE menggunakan Word2Vec untuk train datanya dengan Google
News Data (lebih kurang 100 milyar kata, yang mengandung 3 juta kata dan frase dengan 300
dimensi) yang berukuran 1.53Gb zipped file dan setelah unzipped menjadi 3.4Gb (dalam Bahasa
Inggris)
● GoogleNews-vectors-negative300.bin.gz
https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit?usp=sharing
Keltian Data Science - P2Informatika, LIPI
102.
Load Google’s Word2VecEmbedding (3)
● Contoh demo aritmetika dengan Word2Vec google word vectors
Keltian Data Science - P2Informatika, LIPI
103.
Load Standford’s GloVeEmbedding
● Para Peneliti Stanford juga mengembangkan WE sendiri menggunakan algoritma seperti Word2Vec
yaitu ‘Global Vectors for Word Representation’ atau GloVe (base on result)
● Sama Seperti Word2Vec menyediakan pre-trained WE menggunakan Glove yang dipanggil dari
gensim lib. Tahapnya Glove file di convert ke format Word2Vec file. Perbedaanya hanya pada
header file. File berukuran 822 Megabyte zip file dengan 4 beberapa dimensi model (50, 100, 200
and 300-dimensi vektor), didapat dengan melakukan-train data Wikipedia dengan 6 miliyar token
dan 400,000 kamus kata
● glove.6B.zip
http://nlp.stanford.edu/data/glove.6B.zip
Keltian Data Science - P2Informatika, LIPI
104.
Load Stanford's GloVeEmbedding (4)
● Contoh demo aritmetika dengan Glove word vectors 100 dimensi
Keltian Data Science - P2Informatika, LIPI
Word Embeddings Keras
●Salah satu keuntungan WE adalah menyempurnakan trasional back-of-word model dengan
merepresentasikan kata dan posisinya kedalam ruang vector, salah satunya menggunakan word
embeddings untuk deep learning dalam Python dengan Keras.
● Keras embedding Layer digunakan untuk neural network pada teks data. Input data berupa integer
yang di-encoded, preparasi data dibentuk menggunakan Tokenizer API yang tersedia di Keras.
● Keuntungan menggunakan Keras Embeddings Layer:
○ Training Dataset dapat dilakukan stand alone pada WE dan dapat disimpan dalam sebuah model serta dapat digunakan
pada dataset lainnya.
○ Model WE dapat digunakan sebagai bagian dari Deep Learning dengan melakukan pembelajaran dan update terhadap
model sebelumnya.
○ Dapat digunakan sebagai pre-trained model WE, sebagai sebuah transfer learning
Keltian Data Science - P2Informatika, LIPI
107.
Word Embeddings Kerasdengan Embedding Input Layer (5)
Keltian Data Science - P2Informatika, LIPI
108.
Word Embeddings Kerasdengan Embedding Input Layer
Keltian Data Science - P2Informatika, LIPI
109.
Word Embeddings Kerasdengan Pre-Trained_GloVe (6)
Keltian Data Science - P2Informatika, LIPI
110.
Word Embeddings Kerasdengan Pre-Trained_GloVe (6)
Keltian Data Science - P2Informatika, LIPI
111.
Text Classification withCNN
Case Study
Rini Wijayanti
Keltian Data Science - P2Informatika, LIPI
Project: Sentiment Analysisusing Word Embedding + CNN Model
● Dataset: Movie review
○ http://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz
● Data Preparation
○ Split data into training and testing sets
○ Loading and cleaning the data
○ Define a vocabulary
● Data training: CNN with Embedding Layer
● Model evaluation
Keltian Data Science - P2Informatika, LIPI
114.
Project: Sentiment Analysisusing n-gram CNN Model
● Train data by developing Multichannel Model
○ Encode data
○ Define model
Keltian Data Science - P2Informatika, LIPI
Language Modelling
p(anugerah |cinta adalah)
● Text Suggestions
● Machine Translation
● Spell Correction
● Speech Recognition
● Summarization,
Question-Answering
A language model is a statistical model that assigns a probability to a sequence of words by
generating a probability distribution
Keltian Data Science - P2Informatika, LIPI
118.
Language Modeling
This isthe ...
house
malt
rat
did
What’s the probability of the next word?
p(house | this is the) = ?
Keltian Data Science - P2Informatika, LIPI
119.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
Keltian Data Science - P2Informatika, LIPI
120.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
Keltian Data Science - P2Informatika, LIPI
121.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
Keltian Data Science - P2Informatika, LIPI
122.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
c(this is the house)
c(this is the ...)
=
1
4
Keltian Data Science - P2Informatika, LIPI
123.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
c(this is the house)
c(this is the ...)
=
1
4
4-grams
Keltian Data Science - P2Informatika, LIPI
124.
Toy corpus
This isthe house that Jack built.
This is the malt
That lay in the house that Jack built.
This is the rat,
That ate the malt
That lay in the house that Jack built.
This is the cat,
That killed the rat,
That ate the malt
That lay in the house that Jack built.
p(house | this is the) =
c(that Jack)
c(that...)
=
4
10
bigrams
Keltian Data Science - P2Informatika, LIPI
125.
Language Modeling
This isthe ...
house
malt
rat
did
What’s the probability of the whole sequence?
p(this is the house) = ?
Keltian Data Science - P2Informatika, LIPI
126.
Let’s do somemath
Predict probability of a sequence of words :
w
Keltian Data Science - P2Informatika, LIPI
127.
Let’s do somemath
Predict probability of a sequence of words :
w
● Chain Rule:
p(w)
Keltian Data Science - P2Informatika, LIPI
128.
Let’s Do somemath
Predict probability of a sequence of words :
w
● Chain Rule:
p(w)
● Markov assumption:
Keltian Data Science - P2Informatika, LIPI
129.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
Keltian Data Science - P2Informatika, LIPI
130.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
Toy corpus
This is the malt
That lay in the house that Jack built
p(this is the house) = p(this) p(is | this) p(the | is) p(house | the)
Keltian Data Science - P2Informatika, LIPI
131.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
Toy corpus
This is the malt
That lay in the house that Jack built
p(this is the house) = p(this) p(is | this) p(the | is) p(house | the)
1/12 1 1 1/2
Keltian Data Science - P2Informatika, LIPI
132.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
Toy corpus
This is the malt
That lay in the house that Jack built
p(this is the house) = p(this) p(is | this) p(the | is) p(house | the)
1/2 1 1 1/2
Keltian Data Science - P2Informatika, LIPI
133.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
Keltian Data Science - P2Informatika, LIPI
134.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
It’s normalized separately for each sequence length!
p(this) + p(that) = 1.0
p(this this) + p(this is) + … + p(built built) = 1.0
...
Keltian Data Science - P2Informatika, LIPI
135.
Bigram Languange Model
Sothat’s what we get for n = 2 :
p(w)
It’s normalized separately for each sequence length!
p(this) + p(that) = 1.0
p(this this) + p(this is) + … + p(built built) = 1.0
...
Keltian Data Science - P2Informatika, LIPI
136.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) =
Keltian Data Science - P2Informatika, LIPI
137.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _)
dog cat
Keltian Data Science - P2Informatika, LIPI
138.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _)
dog cat
Keltian Data Science - P2Informatika, LIPI
139.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat)
dog cat tiger
cat dog
cat_
Keltian Data Science - P2Informatika, LIPI
140.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat)
dog cat tiger
cat dog
cat_
141.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat)
dog cat tiger
cat dog
cat_
Keltian Data Science - P2Informatika, LIPI
Keltian Data Science - P2Informatika, LIPI
142.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat) p(cat | dog)
dog cat tiger
cat dog cat
cat_
cat dog_
Keltian Data Science - P2Informatika, LIPI
143.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat) p(cat | dog)
dog cat tiger
cat dog cat
cat_
cat dog_
Keltian Data Science - P2Informatika, LIPI
144.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat) p(cat | dog) p(_ | cat)
dog cat tiger
cat dog cat tiger
cat_
cat dog_
cat dog cat dog
cat dog cat
Keltian Data Science - P2Informatika, LIPI
145.
Let’s check themodel
_ dog _
_ dog cat tiger _
_ cat dog cat _
p(cat dog cat) = p(cat | _) p(dog | cat) p(cat | dog) p(_ | cat)
dog cat tiger
cat dog cat tiger
cat_
cat dog_
cat dog cat dog
cat dog cat
c
Keltian Data Science - P2Informatika, LIPI
146.
Resume : bigramlanguage model
Define the model :
p(w) =
Estimate the probabilities :
It’s all about counting!
Keltian Data Science - P2Informatika, LIPI
Recap: Recurrent NeuralNetworks
● Extremely popular architecture for any sequential data:
...
Keltian Data Science - P2Informatika, LIPI
149.
RNN Language Model
●Predicts a next word based on a previous context
Architecture:
● Use the current state output
● Apply a linear layer on top
● Do softmax to get probabilities
Have a good
?
Mikolov, Karafiát, Burget, Cernocký, and Khudanpur. Recurrent neural network based language model. INTERSPEECH 2010. Keltian Data Science - P2Informatika, LIPI
150.
Cross-entropy loss (forone position) :
Only one non-zero
Have a good
day
● Target : word
● Output : probabilities
Keltian Data Science - P2Informatika, LIPI
151.
How do weuse it to generate language
Idea :
● Feed the previous output as the next input
● Take argmax at each step (greedily) or use beam search
Have
<EOS>
Keltian Data Science - P2Informatika, LIPI
152.
How do weuse it to generate language
Idea :
● Feed the previous output as the next input
● Take argmax at each step (greedily) or use beam search
Have
<EOS> Have
a
Keltian Data Science - P2Informatika, LIPI
153.
How do weuse it to generate language
Idea :
● Feed the previous output as the next input
● Take argmax at each step (greedily) or use beam search
Have
<EOS> Have
a good
a
Keltian Data Science - P2Informatika, LIPI
154.
How do weuse it to generate language
Idea :
● Feed the previous output as the next input
● Take argmax at each step (greedily) or use beam search
Have
<EOS> Have
a good
a
day
good
Keltian Data Science - P2Informatika, LIPI
155.
RNN Language Model
●RNN-LM has lower perplexity and word error rate than 5-gram model with
Knesser-Ney smoothing.
● The experiment is held on Wall Street Journal corpus:
Mikolov, Karafiát, Burget, Cernocký, and Khudanpur. Recurrent neural network based language model. INTERSPEECH 2010. Keltian Data Science - P2Informatika, LIPI
156.
Char/ Word LanguageModeling Pipelines
Input Text
Char/ Word
Sequences
Build
Dictionary
Map Dictionary to
Sequences
Create Features
& Output
Train
$$ Profit $$
157.
Machine Translation withRNN
Case Study
Dianadewi Riswantini
Keltian Data Science - P2Informatika, LIPI
158.
Machine Translation (PenerjemahMesin)
● Definisi : Proses yang dapat mengubah (menerjemahkan) secara otomatis
sumber data teks dalam suatu bahasa menjadi target data teks dalam bahasa
lain
● Tantangan MT : ambiguitas dan fleksibilitas dalam bahasa alami
Keltian Data Science - P2Informatika, LIPI
159.
Metoda Rule-Based MachineTranslation (RBMT)
● Jenis MT yang menggunakan aturan (rules) dalam mengubah teks dari
bahasa asal menjadi bahasa target.
● Aturan yang berlaku digunakan untuk mengembangkan operasi leksikal,
sintaktis maupun semantik.
● Kelemahan : RBMT akan membutuhkan banyak sekali aturan untuk
menangani komputasi bahasa alami (NLP).
Keltian Data Science - P2Informatika, LIPI
160.
Metoda Statistical MachineTranslation (SMT)
● Jenis MT yang menggunakan model statistik dalam melakukan pembelajaran
berdasarkan korpus (dalam volume yang besar) untuk mengubah teks dari
bahasa asal menjadi bahasa target.
● SMT akan memilih nilai kemungkinan terbesar dalam proses penerjemahan
untuk mendapatkan hasil yang terbaik.
● Teknik yang banyak digunakan : phrase-based approach.
● Sistem penerjemah ini membutuhkan pipeline yang terdiri dari beberapa
subsistem dimana proses tuning diperlukan untuk setiap subsistemnya.
Keltian Data Science - P2Informatika, LIPI
161.
Metoda Neural MachineTranslation (NMT)
● Jenis MT yang menggunakan model neural network untuk pembelajaran
model statistik.
● Single system dapat langsung dilatihkan pada teks sumber dan teks target
tanpa memerlukan pipeline dalam pemrosesannya (end-to-end system).
● Model Multilayer Percepton Neural Network (MLP NN) merupakan contoh
model yang paling sederhana. Kelemahan model ini adalah penggunaan
fixed-length sequence untuk input maupun outputnya.
● Recurrent Neural Network (RNN) merupakan model yang lebih fleksibel.
Model ini menerapkan model encoder-decoder yang dapat melakukan
pemrosesan dalam variable-length sequence.
Keltian Data Science - P2Informatika, LIPI
162.
Model Encode-Decoder padaNMT
● Encoder Neural Network berfungsi untuk membaca input (teks sumber) dan
mengkodekannya dalam betuk vektor dengan panjang tetap ('context vector').
● Decoder Neural Network berfungsi untuk memproses vektor menjadi output
(teks target).
● Sistem (encoder dan decoder) melakukan training (proses pelatihan) dengan
mengambil nilai kemungkinan terbesar dalam proses penerjemahan.
● Saat ini RNN diakui sebagai model terbaik untuk encoder-decoder.
Keltian Data Science - P2Informatika, LIPI
163.
Kelemahan NMT
● Prosespelatihan (training) memerlukan waktu panjang
● Kecepatan proses inferensi lambat
● Tidak efektif dalam menerjemahkan kata-kata yang jarang muncul/digunakan
Keltian Data Science - P2Informatika, LIPI
164.
Encoder-Decoder Model RNN
●Diakui memberikan hasil yang lebih baik dalam proses NMT dibandingkan
dengan metode statistik klasik.
● Merupakan 'core technology' dari Google Translate Service
● Efektif untuk penyelesaian masalah sequence-to-sequence (seq2seq)
prediction
● Mempunyai keunggulan utama : kemampuan melatih single end-to-end model
dan menangani variable-length input/output sequences
Keltian Data Science - P2Informatika, LIPI
165.
Contoh Model RNNuntuk NMT
● Model seq2seq yang dikembangkan untuk menerjemahkan Bahasa Inggris ke
dalam Bahasa Perancis
○ Sutskever NMT Model
■ Menggunakan LSTM (Long Short Term Memory) untuk encoder dan decoder
○ Cho NMT Model (by Kyunghyun Cho) -> lebih sederhana
■ Menggunakan GRU (Gated Recurrent Neural Network) untuk encoder dan decoder
● Catatan : untuk penjelasan lebih lengkap dapat dilihat pada Neural Machine
Translation.ipynb
Keltian Data Science - P2Informatika, LIPI
166.
Contoh Program :German to English NMT
● Dataset dapat diunduh dari http://www.manythings.org/anki/deu-eng.zip
● Dataset berisi pasangan frase kalimat bahasa inggris dan bahasa jerman
● Detil kode program dan penjelasannya dapat dilihat pada direktori
Neural_Machine_Translation.
Keltian Data Science - P2Informatika, LIPI
167.
Program : PrepareData (1_prepare_data.ipynb)
● Melakukan pembersihan dataset
● Dataset dibersihakan dengan operasi-operasi sebagai berikut:
○ Penghapusan karakter yang non-printable
○ Penghapusan tanda baca
○ Normalisasi karakter Unicode menjadi karakter ASCII
○ Normalisasi huruf menjadi huruf kecil
○ Penghapusan token/kata yang bukan alfabetis
● Keluaran program berupa file dataset () yang berisi pasangan frase dari
kedua bahasa, disimpan dalam file english-german.pkl
Keltian Data Science - P2Informatika, LIPI
168.
Program : SplitData (2_split_data.ipynb)
● Melakukan pemisahan data untuk proses training dan proses testing
● File dataset master terdiri dari 170.000 pasangan frase. Untuk mempercepat
proses training, maka dalam workhop ini digunakan 10.000 pasangan frase
(dataset turunan) yang diambil secara acak dari dataset master
● Dataset turunan kemudian dipisahkan dengan rasio 90% : 10% untuk dataset
latih (training) dan dataset uji (testing)
● Keluaran dari program ini adalah :
○ File english-german-both.pkl (10.000 data)
○ File english-german-train.pkl (9.000 data)
○ File english-german-test.pkl (1.000) data)
Keltian Data Science - P2Informatika, LIPI
169.
Program : TrainModel (3_train_model.ipynb)
● Melakukan proses pelatihan (training) untuk mendapatkan model RNN
● Program mencari panjang vocabulary dan panjang maksimal frase dari kedua
bahasa
● Word embedding digunakan untuk pengkodean input dan one hot digunakan
untuk pengkodean output. One hot akan melakukan prediksi dari berdasarkan
nilai probabilitas dari setiap kata/token dalam vocabulary
● Konfigurasi model RNN :
○ Encoder-decoder : LSTM model
○ Activation function : softmax. optimizer function : adam, loss function :
categorical_crossentropy
● Keluaran dari program ini adalah sebuah model RNN yang disimpan dalam
file model.h5
Keltian Data Science - P2Informatika, LIPI
170.
Program : GenerateEnglish Phrase (4_generate.ipynb)
● Melakukan evaluasi terhadap model yang telah dihasilkan
● Evaluasi dilakukan terhadap dataset latih maupun dataset uji. Program akan
memprediksi frase output dalam bahasa Inggris untuk setiap frase input
dalam bahasa Jerman.
● Skor BLEU (Bi-Lingual Evaluation Understudy) dihitung untuk 1 s.d. 4 -grams.
● Informasi mengenai skor BLEU dapat dilihat pada :
○ https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
Keltian Data Science - P2Informatika, LIPI
Current Baseline Model
●Konfigurasi :
○ Dimensi word embedding : 512
○ RNN cell : GRU
○ Encoder : bidirectional
○ Encoder depth : 2 layers (1 layer/direction)
○ Decoder depth : 2 layers
○ Optimizer algorithm : Adam
Keltian Data Science - P2Informatika, LIPI
173.
Rekomendasi Konfigurasi ModelRNN
● Dimensi word embedding dimulai dengan 128 dan selanjutnya dapat
dinaikkan
● Terdapat 3 tipe RNN cell : simple RNN, LSTM, dan GRU. Kinerja GRU dan
LSTM lebih baik daripada Simple RNN. Kinerja LSTM adalah yang terbaik
● Encoder depth dimulai dengan menggunakan 1 layer, dan kemudian dapat
dikembangkan menjadi 2 layers.
● Decoder depth dimulai dengan menggunakan 1 layer, dan kemudian dapat
dikembangkan menjadi 4 layers
Keltian Data Science - P2Informatika, LIPI
174.
Mekanisme Attention
● Merupakanteknik yang dapat memperbaiki kinerja sistem.
● Digunakan untuk mempelajari dimana tempat dari input teks yang harus
mendapatkan perhatian (attention) untuk mendapatkan output teks yang
terbaik.
● Teknik yang paling state-of-the-arts
● Mekanisme attention digunakan oleh Google dalam membangun mesin
penerjemahnya Google Neural Machine Translation (GNMT)
● Contoh : Bahdanan-style (weighted average style attention)
Keltian Data Science - P2Informatika, LIPI
• A communicationsprotocol
• Allows retrieving inter-linked text documents (hypertext)
• World Wide Web.
• HTTP Verbs
• HEAD
• GET
• POST
• PUT
• DELETE
• TRACE
• OPTIONS
• CONNECT
Browser Web Server
GET /index.html HTTP/1.1
Host: www.lipi.go.id
HTTP/1.1 200 OK
Content-Type: text/html
<html><head>…
Hypertext Transfer Protocol (HTTP)
Keltian Data Science - P2Informatika, LIPI
177.
• A styleof software architecture for distributed hypermedia systems such as the
World Wide Web.
• Introduced in the doctoral dissertation of Roy Fielding
• One of the principal authors of the HTTP specification.
• A collection of network architecture principles which outline how resources are
defined and addressed
Representational State Transfer (REST)
Keltian Data Science - P2Informatika, LIPI
• REST usesURI to identify resources
• http://localhost/books/
• http://localhost/books/ISBN-0011
• http://localhost/books/ISBN-0011/authors
• http://localhost/classes
• http://localhost/classes/cs2650
• http://localhost/classes/cs2650/students
• As you traverse the path from more generic to more specific, you are
navigating the data
Naming Resources
Keltian Data Science - P2Informatika, LIPI
180.
• Represent theactions to be performed on resources
○ HTTP GET
○ HTTP POST
○ HTTP PUT
○ HTTP DELETE
Verbs
Keltian Data Science - P2Informatika, LIPI
181.
• How clientsask for the information they seek.
• Issuing a GET request transfers the data from the server to the client in
some representation
• GET http://localhost/books
• Retrieve all books
• GET http://localhost/books/ISBN-0011021
• Retrieve book identified with ISBN-0011021
• GET http://localhost/books/ISBN-0011021/authors
• Retrieve authors for book identified with ISBN-0011021
HTTP GET
Keltian Data Science - P2Informatika, LIPI
182.
• HTTP POSTcreates a resource
• HTTP PUT updates a resource
• POST http://localhost/books/
• Content: {title, authors[], …}
• Creates a new book with given properties
• PUT http://localhost/books/isbn-111
• Content: {isbn, title, authors[], …}
• Updates book identified by isbn-111 with submitted properties
HTTP PUT, HTTP POST
Keltian Data Science - P2Informatika, LIPI
183.
• Removes theresource identified by the URI
• DELETE http://localhost/books/ISBN-0011
• Delete book identified by ISBN-0011
HTTP DELETE
Keltian Data Science - P2Informatika, LIPI
184.
• How datais represented or returned to the client for presentation.
• Two main formats:
• JavaScript Object Notation (JSON)
• XML
• It is common to have multiple representations of the same data
Representations
Keltian Data Science - P2Informatika, LIPI














































![1. Manual Tokenization
● Load Data : Load seluruh teks dari file metamorphosis_clean.txt ke dalam memory
# load text
filename = 'metamorphosis_clean.txt'
file = open(filename, 'rt')
text = file.read()
file.close()
● Split by whitespace : mengubah teks mentah menjadi daftar kata berdasarkan spasi (whitespace), baris baru
dan tab sehingga menjadi daftar kata-kata.
❖ 100 kata pertama dari dokumen akan dipisahkan..
# load text
...
# split into words by white space
words = text. split()
print(words[:100])
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-47-320.jpg)
![a. Manual Tokenization - Split by whitespace
100 kata pertama dari dokumen akan dipisahkan.
['One', 'morning,', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams,', 'he', 'found', 'himself',
'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible','vermin.', 'He', 'lay', 'on', 'his', 'armour-like',
'back,', 'and', 'if', 'he', 'lifted', 'his', 'head', 'a', 'little', 'he', 'could', 'see', 'his', 'brown',
'belly,', 'slightly', 'domed', 'and', 'divided', 'by', 'arches', 'into', 'stiff','sections.', 'The', 'bedding',
'was', 'hardly', 'able', 'to', 'cover', 'it', 'and', 'seemed', 'ready', 'to', 'slide', 'off', 'any','moment.',
'His', 'many', 'legs,', 'pitifully', 'thin', 'compared', 'with', 'the', 'size', 'of', 'the', 'rest', 'of',
'him,', 'waved', 'about', 'helplessly', 'as', 'he','looked.', '"What's', 'happened', 'to', 'me?"', 'he',
'thought.', 'It', "wasn't", 'a', 'dream.', 'His', 'room,', 'a', 'proper', 'human']
● Tanda penghubung masih disimpan (armour-like).
● Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat masih disimpan ( vermin., sections.,
moment., looked., thought., and me?).
● Tanda penyingkat ditambahkan dengan tanda slash (garis miring) (What’s)
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-48-320.jpg)
![b. Manual Tokenization - Split by words only
● Select Words (another approach)
Menggunakan model regex (re) untuk memisahkan dokumen menjadi kata-kata berdasarkan non-alphanumeric (termasuk
tanda baca dan spasi), sehingga yang tersisa adalah string dengan karakter alfanumerik (a-z, A-Z, 0-9)
import re
# load text
...
# split into on words only
words = re.split(r'W+', text)
print(words[:100])
➔ Kata armour-like sekarang telah menjadi dua kata : armour dan like (is fine).
➔ Kata What's sekarang juga menjadi dua kata : What dan s (not great).
➔ Kata wasn't sekarang juga menjadi dua kata : wasn dan t (not great).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat sudah tidak tersimpan.
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-49-320.jpg)
![c. Manual Tokenization - Split by Whitespace and Remove Punctuation (1)
● Split by Whitespace and Remove Punctuation
List of words :
○ tanpa menggunakan tanda baca koma, tanda kutip dan lainnya
print(string.punctuation) → !"#$%&'()*+,-./:;<=>?@[]^_`{|}~
○ mempertahankan konstraksi kata-kata seperti (e.g. armour-like)
Menggunakan reguler expression (re) untuk memilih tanda baca dan fungsi sub() untuk menggantinya dengan
nothing.
# prepare regex for char filtering
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# remove punctuation from each word
stripped = [re_punc.sub('', w) for w in words]
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-50-320.jpg)
![c. Manual Tokenization - Split by Whitespace and Remove Punctuation (2)
● load the text file,
● split it into words by white space,
● translate each word to remove the punctuation.
['One', 'morning', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams',
'he', 'found', 'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible',
'vermin', 'He', 'lay', 'on', 'his', ' armourlike',
...,
'Whats', 'happened', 'to', 'me', 'he', 'thought', 'It', ' wasnt', 'a', 'dream', 'His',
'room', 'a', 'proper', 'human']
➔ Kata What's dan wasn't menjadi Whats dan wasnt (seperti yang diinginkan).
➔ Kata armour-like menjadi seperti armourlike (not great).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat sudah tidak tersimpan
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-51-320.jpg)
![c. Manual Tokenization - Split by Whitespace and Remove Punctuation (3)
Filter out all non-printable characters by selecting the inverse of the string.printable constant.
['One', 'morning,', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams,', 'he',
'found', 'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible', ' vermin.',
'He', 'lay', 'on', 'his', ' armour-like ', 'back,', 'and', 'if', 'he', 'lifted',
...,
'helplessly', 'as', 'he', ' looked.', '"What's', 'happened', 'to', ' me?"', 'he', ' thought.',
'It', "wasn't", 'a', 'dream.', 'His', 'room,', 'a', 'proper', 'human']
# prepare regex for char filtering
re_print = re.compile('[^%s]' % re.escape(string.printable))
# remove punctuation from each word
result = [re_print.sub('', w) for w in words]
print(result[:100])
➔ Tanda baca masih disimpan (wasn't dan armour-like).
➔ Akhir tanda baca (.) pada kata terakhir dalam setiap kalimat masih disimpan ( vermin., dream., looked., thought., and me?).
➔ Kutipan di tengah kalimat ditambahkan dengan tanda slash (garis miring) (What’s)
Hasil serupa dengan menggunakan split()
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-52-320.jpg)
![d. Manual Tokenization - Normalizing Case
Konversi seluruh kata menjadi huruf kecil (lowercase) dengan menggunakan fungsi lower() pada setiap
kata.
# load text
# split into words by white space
# convert to lower case
words = [word. lower() for word in words]
print(words[:100])
['one', 'morning,', 'when', 'gregor', 'samsa',
'woke', 'from', 'troubled', 'dreams,', 'he',
'found', 'himself', 'transformed', 'in', 'his',
'bed', 'into', 'a', 'horrible', 'vermin.',
'he', 'lay', 'on', 'his', 'armour-like',
'back,', 'and', 'if', 'he', 'lifted', 'his',
'head', 'a', 'little', 'he', 'could', 'see',
'his', 'brown', 'belly,', 'slightly', 'domed',
'and', 'divided', 'by', 'arches', 'into',
'stiff', 'sections.', 'the', 'bedding', 'was',
'hardly', 'able', 'to', 'cover', 'it', 'and',
'seemed', 'ready', 'to', 'slide', 'off', 'any',
'moment.', 'his', 'many', 'legs,', 'pitifully',
'thin', 'compared', 'with', 'the', 'size',
'of', 'the', 'rest', 'of', 'him,', 'waved',
'about', 'helplessly', 'as', 'he', 'looked.',
'"what's', 'happened', 'to', 'me?"', 'he',
'thought.', 'it', "wasn't", 'a', 'dream.',
'his', 'room,', 'a', 'proper', 'human']
Cleaning text is really hard, problem specific, and full
of tradeoffs.
Simple is better. Simpler text data, simpler models,
smaller vocabularies.
You can always make things more
complex later to see if it results in better model skill.
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-53-320.jpg)

![a. Cleaning with NLTK - Split into Sentences
● Menguraikan setiap teks menjadi kalimat-kalimat
● NLTK provides the sent_tokenize() function to split text into sentences
from nltk import sent_tokenize
# load data
...
# split into sentences
sentences = sent_tokenize(text)
print(sentences[0])
➔ Teks dokumen dibagi menjadi kalimat-kalimat yang masih mempertahankan baris baru dari
dokumen asli.
One morning, when Gregor Samsa woke from troubled dreams, he found
himself transformed in his bed into a horrible vermin.
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-55-320.jpg)
![b. Cleaning with NLTK - Split into Words
● Menguraikan setiap teks menjadi kata-kata
● NLTK menyediakan fungsi word_tokenize() untuk
membagi string menjadi token-token (kata-kata nominal)
berdasarkan tanda baca dan spasi
from nltk.tokenize import word_tokenize
# load data
...
# split into words
tokens = word_tokenize(text)
print(tokens[:100])
➔ Koma, titik dan baris kosong akan dianggap sebagai token terpisah.
➔ Ada kontraksi yang masih disimpan (armour-like).
➔ Ada kontraksi yang dipisah (What's menjadi What dan 's).
['One', 'morning', ',', 'when', 'Gregor',
'Samsa', 'woke', 'from', 'troubled', 'dreams',
',', 'he', 'found', 'himself', 'transformed',
'in', 'his', 'bed', 'into', 'a', 'horrible',
'vermin', '.', 'He', 'lay', 'on', 'his',
'armour-like', 'back', ',', 'and', 'if', 'he',
'lifted', 'his', 'head', 'a', 'little', 'he',
'could', 'see', 'his', 'brown', 'belly', ',',
'slightly', 'domed', 'and', 'divided', 'by',
'arches', 'into', 'stiff', 'sections', '.',
'The', 'bedding', 'was', 'hardly', 'able',
'to', 'cover', 'it', 'and', 'seemed', 'ready',
'to', 'slide', 'off', 'any', 'moment', '.',
'His', 'many', 'legs', ',', 'pitifully',
'thin', 'compared', 'with', 'the', 'size',
'of', 'the', 'rest', 'of', 'him', ',',
'waved', 'about', 'helplessly', 'as', 'he',
'looked', '.', '``', 'What', "'s", 'happened',
'to']
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-56-320.jpg)
![c. Cleaning with NLTK - Filter Out Punctuation
● Filter semua token yang tidak diinginkan
(semua tanda baca yang berdiri sendiri),
● Lakukan iterasi berulang pada semua token dan
hanya menyimpan token yang terdiri dari abjad
saja, menggunakan fungsi isalpha()
['One', 'morning', 'when', 'Gregor', 'Samsa', 'woke', 'from', 'troubled', 'dreams', 'he', 'found',
'himself', 'transformed', 'in', 'his', 'bed', 'into', 'a', 'horrible', 'vermin', 'He', 'lay',
'on', 'his', 'back', 'and', 'if', 'he', 'lifted', 'his', 'head', 'a', 'little', 'he', 'could',
'see', 'his', 'brown', 'belly', 'slightly', 'domed', 'and', 'divided', 'by', 'arches', 'into',
'stiff', 'sections', 'The', 'bedding', 'was', 'hardly', 'able', 'to', 'cover', 'it', 'and',
'seemed', 'ready', 'to', 'slide', 'off', 'any', 'moment', 'His', 'many', 'legs', 'pitifully',
'thin', 'compared', 'with', 'the', 'size', 'of', 'the', 'rest', 'of', 'him', 'waved', 'about',
'helplessly', 'as', 'he', 'looked', 'What', 'happened', 'to', 'me', 'he', 'thought', 'It', 'was',
'a', 'dream', 'His', 'room', 'a', 'proper', 'human', 'room']
from nltk.tokenize import word_tokenize
# load data
# split into sentences
tokens = word_tokenize(text)
# remove all tokens that are not alphabetic
words = [word for word in tokens if word.isalpha()]
print(words[:100])
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-57-320.jpg)
![d. Cleaning with NLTK - Filter Out Stop Words (1)
● Kata-kata umum seperti : the, a, an dan is adalah 'stop words'.
● Stop words : kata-kata yang tidak berkontribusi pada makna yang lebih dalam dari frasa.
● NLTK menyediakan daftar 'stop words' untuk berbagai bahasa yang telah disetujui secara umum .
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd",
'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers',
'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which',
'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been',
'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if',
'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into',
'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off',
'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all',
'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same',
'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd',
'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn',
"doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't",
'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren',
"weren't", 'won', "won't", 'wouldn', "wouldn't"] Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-58-320.jpg)
![d. Cleaning with NLTK - Filter Out Stop Words (2)
Tahap-tahap untuk persiapan teks :
● Load raw text
● Split/pisahkan menjadi token-token
● Konversi ke huruf kecil
● Hapus tanda baca dari setiap token
● Hapus yang bukan termasuk abjad
● filter token yang tersisa yang bukan stop
words
import string
import re
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# load data
...
# split into words
tokens = word_tokenize(text)
# convert to lower case
tokens = [w.lower() for w in tokens]
# prepare regex for char filtering
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# remove punctuation from each word
stripped = [re_punc.sub('', w) for w in tokens]
# remove remaining tokens that are not alphabetic
words = [word for word in stripped if word.isalpha()]
# filter out stop words
stop_words = set(stopwords.words('english'))
words = [w for w in words if not w in stop_words]
print(words[:100])
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-59-320.jpg)

![d. Cleaning with NLTK - Steam Words (2)
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
# load data
...
# split into words
tokens = word_tokenize(text)
# stemming of words
porter = PorterStemmer()
stemmed = [ porter.stem(word) for word in tokens]
print(stemmed[:100])
['one', 'morn', ',', 'when', 'gregor', 'samsa', 'woke', 'from', 'troubl', 'dream', ',', 'he',
'found', 'himself', 'transform', 'in', 'hi', 'bed', 'into', 'a', 'horribl', 'vermin', '.', 'He',
'lay', 'on', 'hi', 'armour-lik', 'back', ',', 'and', 'if', 'he', 'lift', 'hi', 'head', 'a',
'littl', 'he', 'could', 'see', 'hi', 'brown', 'belli', ',', 'slightli', 'dome', 'and', 'divid',
'by', 'arch', 'into', 'stiff', 'section', '.', 'the', 'bed', 'wa', 'hardli', 'abl', 'to',
'cover', 'it', 'and', 'seem', 'readi', 'to', 'slide', 'off', 'ani', 'moment', '.', 'hi', 'mani',
'leg', ',', 'piti', 'thin', 'compar', 'with', 'the', 'size', 'of', 'the', 'rest', 'of', 'him',
',', 'wave', 'about', 'helplessli', 'as', 'he', 'look', '.', '``', 'what', "'s", 'happen', 'to']
● Beberapa kata telah mendapatkan akar
katanya, seperti trouble menjadi troub,
morning menjadi morn, transformed menjadi
transform.
● implementasi stemming menghasilkan
token-token dengan huruf kecil.
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-61-320.jpg)



![Bag of Words (3)
Langkah 3. Create Document Vectors
- Memberi nilai untuk setiap kata. Metode penilaian : 0 untuk absen dan 1 untuk yang ada.
- Menggunakan dokumen pada baris pertama, hasil penilaian dari kata-kata sebagai berikut :
it = 1
was = 1
the = 1
best = 1
of = 1
times = 1
worst = 0
age = 0
wisdom = 0
foolishness = 0
Keltian Data Science - P2Informatika, LIPI
- sebagai binary vektor akan tampak seperti :
it - was- the-best-of-times-worst-age-wisdom-foolishness
"it was the best of times" = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
"it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
”it was the age of foolishnes"= [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-65-320.jpg)






![2. Scikit Learn - Word Frequencies with TfidfVectorizer (3)
● text = ["The quick brown fox jumped over the lazy dog.", "The dog.", "The fox"]
● print(vectorizer.vocabulary_)
{'the': 7, 'quick': 6, 'brown': 0, 'fox': 2, 'jumped': 3, 'over': 5, 'lazy': 4, 'dog': 1}
● print(vectorizer.idf_)
[ 1.69314718 1.28768207 1.28768207 1.69314718 1.69314718 1.69314718
1.69314718 1. ]
untuk kata 'fox' pada dokumen pertama (0,2)
➔ tf = 1 (jumlah kata 'fox' yang muncul pada dokumen 1)
➔ df = 2 (jumlah kata 'fox' yang muncul di seluruh dokumen)
➔ N = 3 (total dokumen)
Keltian Data Science - P2Informatika, LIPI
idf = ln((N+1)/(df+1)) + 1
idf = ln(4/3) + 1
= 0.28768207 + 1
= 1.28768207
tfidf(0,2) = tf * idf
= 1 * 1.28768207
= 1.28768207](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-72-320.jpg)


![1. Keras - Split words with text_to_word_sequence()
text_to_word_sequence(): memisahkan teks menjadi kata-kata (tokens)
3 hal otomatis yang dilakukan oleh fungsi ini, yaitu :
● split/memisahkan kata-kata dengan spasi
● menyaring tanda baca
● mengubah teks menjadi huruf kecil (lower=true)
text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-75-320.jpg)
![2. Keras - Encoding with one_hot()
one_hot():me-nokeninsasi dan meng-encode teks menjadi sebuah daftar indeks kata-kata berukuran n.
● Fungsi ini mengubah teks menjadi huruf kecil, menyaring tanda baca dan memisahkan kata berdasarkan
spasi.
● Hasilnya adalah nilai integer [1, n]. n adalah ukuran kosakata yang harus ditentukan, bisa berupa total
kata dalam dokumen atau lebih (jika bermaksud meng-encode dokumen tambahan yang mengandung
kata tambahan).
● Ukuran ini mendefinisikan ruang hashing dimana kata-kata di hash. Untuk meminimalkan tabrakan,
idealnya harus lebih besar dari kosakata dengan beberapa persentase (sekitar 25 %).
● Tidak ada jaminan keunikan (unicity non-guaranteed) dari setiap nilai integer yang dihasilkan
one_hot(text, n, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-76-320.jpg)
![3. Keras - hash Encoding with hashing_trick()
● Kata-kata yang di-hash akan ditentukan ke indeks integer yang sama dalam target hash space. Nilai
atau hitungan biner dapat digunakan untuk memberi nilai kata (scoring word), disebut dengan hash
trick atau fitur hashing.
● hashing_trick() digunakan untuk me-nokenisasi dan meng-encode dokumen seperti fungsi
one_hot(), dengan lebih banyak fleksibilitas dan memungkinkan untuk menentukan fungsi hash
yang default atau fungsi hash lain seperti fungsi md5.
● Tidak ada jaminan keunikan (unicity non-guaranteed) dari setiap nilai integer yang dihasilkan
Fungsi ini menghasilkan versi dokumen yang telah di encode ke dalam integer.
hashing_trick(text, n, hash_function=None, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~',
lower=True, split=' ')
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-77-320.jpg)
![4. Keras - Tokenizer API (1)
Keras menyediakan API yang lebih canggih untuk menyiapkan teks yang dapat disimpan dan digunakan
kembali untuk mempersiapkan beberapa dokumen teks (Tokenizer API).
● num_words : jumlah maksimum kata yang harus disimpan berdasarkan frekuensi kata.
● char_level : Jika True, maka setiap karakter akan diperlakukan sebagai token.
● oov_token : None atau string. Jika ada, akan ditambahkan ke word_index dan digunakan untuk menggantikan
kata-kata diluar kosakata.
Panjang dari vektor adalah total ukuran dari kosakata.
Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~', lower=True,
split=' ', char_level=False, oov_token=None)
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-78-320.jpg)




![Example of BoW Model
● Create Document Vectors
→ score the words in each document
As a binary vectors :
it = 1
was = 1
the = 1
best = 1
of = 1
times = 1
worst = 0
age = 0
wisdom = 0
foolishness = 0
“it was the best of times” = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
“it was the worst of times” = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
“it was the age of wisdom” = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
“it was the age of foolishnes” = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-83-320.jpg)







































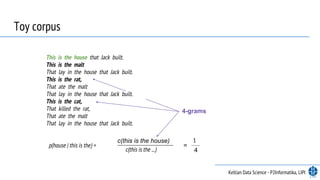


























































![• HTTP POST creates a resource
• HTTP PUT updates a resource
• POST http://localhost/books/
• Content: {title, authors[], …}
• Creates a new book with given properties
• PUT http://localhost/books/isbn-111
• Content: {isbn, title, authors[], …}
• Updates book identified by isbn-111 with submitted properties
HTTP PUT, HTTP POST
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-182-320.jpg)


![• XML
• <COURSE>
• <ID>CS2650</ID>
• <NAME>Distributed Multimedia Software</NAME>
• </COURSE>
• JSON
• { course : [{ id: CS2650}, { name: Distributed Multimedia Sofware} ]}
Representations
Keltian Data Science - P2Informatika, LIPI](https://image.slidesharecdn.com/dl4nlp-slides-180817145426/85/Practical-Deep-Learning-for-Natural-Language-Processing-185-320.jpg)













































