Downloaded 40 times










![Modeling Data as Documents
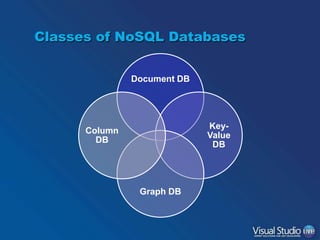
•
Don’t be tempted to use a document store
like a relational database
– Documents should be aggregate roots
– References to other documents are OK but (some)
data duplication (denormalization) is also OK
“conference/11” : {
tracks: [
{ title: “Web”, days: { 1, 2 }, sessions: [ ... ] },
...
]
Should the tracks be
}
references?](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-12-320.jpg)
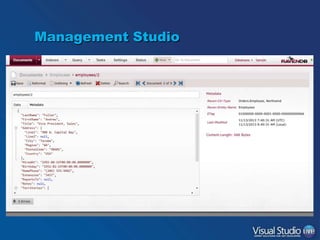
![…But Don’t Go Too Far
•
Is this a reasonable document?
“blogs/1” : {
tags : [ “Windows”, “Visual Studio”, “VSLive” ],
posts : [
My blog has 500 posts
{ title: “Migrating to RavenDB”,
content: “When planning a migration to Raven…”,
author: “Sasha Goldshtein”,
comments: [ ... ]
...
},
...
]
}](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-13-320.jpg)
![One More Example
“orders/1783”: {
customer: { name: “James Bond”, id: “customers/007” },
items: [
{ product: “Disintegrator”, cost: 78.3, qty: 1 },
{ product: “Laser shark”,
cost: 99.0, qty: 3 }
]
}
What if we always need
to know whether the
product is in stock?
What if we always need
the customer’s address?
What if the customer’s
address changes often?](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-14-320.jpg)
![Include
•
Load the referenced document when the
referencing document is retrieved
– Also supports arrays of referenced documents
Order order = session.Include<Order>(o => o.Customer.Id)
.Load(“orders/1783”);
Customer customer = session.Load<Customer>(
order.Customer.Id);
Order[] orders = session.Query<Order>()
.Customize(q => q.Include<Order>(o => o.Customer.Id))
.Where(o => o.Items.Length > 5)
.ToArray();](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-15-320.jpg)





![Hierarchical Data
•
How to index the following hierarchy of
comments by author and text?
public class Post
{
public string Title { get; set; }
public Comment[] Comments { get; set; }
}
public class Comment
{
public string Author { get; set; }
public string Text { get; set; }
public Comment[] Comments { get; set; }
}](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-21-320.jpg)


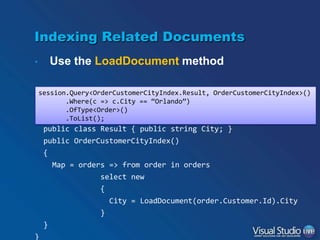


![Using Full-Text Search and Query
Suggestions
var query = session.Query<Speaker, SpeakerIndex>()
.Where(s => s.Name == name);
var speaker = query.FirstOrDefault();
Will find “Dave Smith” when
searching for “dave” or “smith”
if (speaker == null)
{
Will suggest “dave” when
searching for “david”
string[] suggestions = query.Suggest().Suggestions;
}](https://image.slidesharecdn.com/ravendb-131120145844-phpapp01/85/Introduction-to-RavenDB-28-320.jpg)






This document provides an overview of the RavenDB NoSQL document database. It begins with an introduction to NoSQL databases and describes the main classes. It then discusses RavenDB specifically - including that it is a transactional document database, is open source, and uses JSON storage with LINQ querying. Options for hosting RavenDB are presented. The document demonstrates basic CRUD operations on documents as well as modeling data, indexing, and advanced querying features like full-text search. It also briefly mentions upcoming RavenDB 3.0 features.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















